 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairFlow: Closed-Form Source-Target Coupling for Few-Step Generation in Discrete Flow Models
Dec 23, 2025We introduce $\texttt{PairFlow}$, a lightweight preprocessing step for training Discrete Flow Models (DFMs) to achieve few-step sampling without requiring a pretrained teacher. DFMs have recently emerged as a new class of generative models for discrete data, offering strong performance. However, they suffer from slow sampling due to their iterative nature. Existing acceleration methods largely depend on finetuning, which introduces substantial additional training overhead. $\texttt{PairFlow}$ addresses this issue with a lightweight preprocessing step. Inspired by ReFlow and its extension to DFMs, we train DFMs from coupled samples of source and target distributions, without requiring any pretrained teacher. At the core of our approach is a closed-form inversion for DFMs, which allows efficient construction of paired source-target samples. Despite its extremely low cost, taking only up to 1.7% of the compute needed for full model training, $\texttt{PairFlow}$ matches or even surpasses the performance of two-stage training involving finetuning. Furthermore, models trained with our framework provide stronger base models for subsequent distillation, yielding further acceleration after finetuning. Experiments on molecular data as well as binary and RGB images demonstrate the broad applicability and effectiveness of our approach.
MatLat: Material Latent Space for PBR Texture Generation
Dec 19, 2025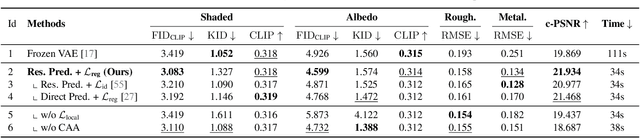
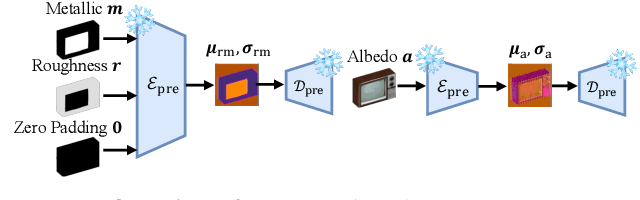
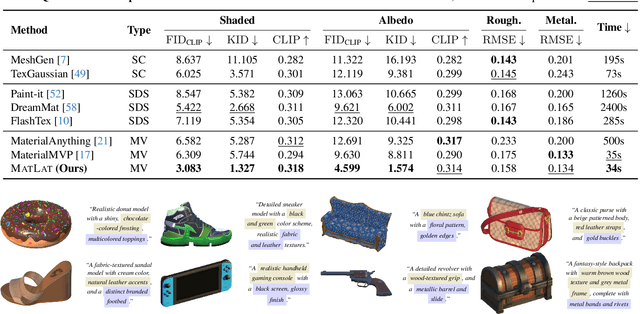
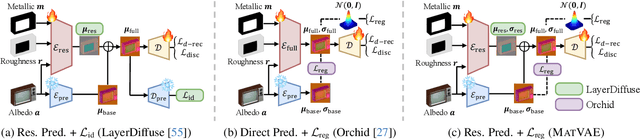
We propose a generative framework for producing high-quality PBR textures on a given 3D mesh. As large-scale PBR texture datasets are scarce, our approach focuses on effectively leveraging the embedding space and diffusion priors of pretrained latent image generative models while learning a material latent space, MatLat, through targeted fine-tuning. Unlike prior methods that freeze the embedding network and thus lead to distribution shifts when encoding additional PBR channels and hinder subsequent diffusion training, we fine-tune the pretrained VAE so that new material channels can be incorporated with minimal latent distribution deviation. We further show that correspondence-aware attention alone is insufficient for cross-view consistency unless the latent-to-image mapping preserves locality. To enforce this locality, we introduce a regularization in the VAE fine-tuning that crops latent patches, decodes them, and aligns the corresponding image regions to maintain strong pixel-latent spatial correspondence. Ablation studies and comparison with previous baselines demonstrate that our framework improves PBR texture fidelity and that each component is critical for achieving state-of-the-art performance.
ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation
Mar 28, 2025We introduce ORIGEN, the first zero-shot method for 3D orientation grounding in text-to-image generation across multiple objects and diverse categories. While previous work on spatial grounding in image generation has mainly focused on 2D positioning, it lacks control over 3D orientation. To address this, we propose a reward-guided sampling approach using a pretrained discriminative model for 3D orientation estimation and a one-step text-to-image generative flow model. While gradient-ascent-based optimization is a natural choice for reward-based guidance, it struggles to maintain image realism. Instead, we adopt a sampling-based approach using Langevin dynamics, which extends gradient ascent by simply injecting random noise--requiring just a single additional line of code. Additionally, we introduce adaptive time rescaling based on the reward function to accelerate convergence. Our experiments show that ORIGEN outperforms both training-based and test-time guidance methods across quantitative metrics and user studies.
StochSync: Stochastic Diffusion Synchronization for Image Generation in Arbitrary Spaces
Jan 26, 2025



We propose a zero-shot method for generating images in arbitrary spaces (e.g., a sphere for 360{\deg} panoramas and a mesh surface for texture) using a pretrained image diffusion model. The zero-shot generation of various visual content using a pretrained image diffusion model has been explored mainly in two directions. First, Diffusion Synchronization-performing reverse diffusion processes jointly across different projected spaces while synchronizing them in the target space-generates high-quality outputs when enough conditioning is provided, but it struggles in its absence. Second, Score Distillation Sampling-gradually updating the target space data through gradient descent-results in better coherence but often lacks detail. In this paper, we reveal for the first time the interconnection between these two methods while highlighting their differences. To this end, we propose StochSync, a novel approach that combines the strengths of both, enabling effective performance with weak conditioning. Our experiments demonstrate that StochSync provides the best performance in 360{\deg} panorama generation (where image conditioning is not given), outperforming previous finetuning-based methods, and also delivers comparable results in 3D mesh texturing (where depth conditioning is provided) with previous methods.
Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses
Jun 14, 2024



We propose a novel method for learning representations of poses for 3D deformable objects, which specializes in 1) disentangling pose information from the object's identity, 2) facilitating the learning of pose variations, and 3) transferring pose information to other object identities. Based on these properties, our method enables the generation of 3D deformable objects with diversity in both identities and poses, using variations of a single object. It does not require explicit shape parameterization such as skeletons or joints, point-level or shape-level correspondence supervision, or variations of the target object for pose transfer. To achieve pose disentanglement, compactness for generative models, and transferability, we first design the pose extractor to represent the pose as a keypoint-based hybrid representation and the pose applier to learn an implicit deformation field. To better distill pose information from the object's geometry, we propose the implicit pose applier to output an intrinsic mesh property, the face Jacobian. Once the extracted pose information is transferred to the target object, the pose applier is fine-tuned in a self-supervised manner to better describe the target object's shapes with pose variations. The extracted poses are also used to train a cascaded diffusion model to enable the generation of novel poses. Our experiments with the DeformThings4D and Human datasets demonstrate state-of-the-art performance in pose transfer and the ability to generate diverse deformed shapes with various objects and poses.
SyncTweedies: A General Generative Framework Based on Synchronized Diffusions
Mar 22, 2024



We introduce a general framework for generating diverse visual content, including ambiguous images, panorama images, mesh textures, and Gaussian splat textures, by synchronizing multiple diffusion processes. We present exhaustive investigation into all possible scenarios for synchronizing multiple diffusion processes through a canonical space and analyze their characteristics across applications. In doing so, we reveal a previously unexplored case: averaging the outputs of Tweedie's formula while conducting denoising in multiple instance spaces. This case also provides the best quality with the widest applicability to downstream tasks. We name this case SyncTweedies. In our experiments generating visual content aforementioned, we demonstrate the superior quality of generation by SyncTweedies compared to other synchronization methods, optimization-based and iterative-update-based methods.