 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Ambulatory Vision: Learning Visually-Grounded Active View Selection
Dec 15, 2025Vision Language Models (VLMs) excel at visual question answering (VQA) but remain limited to snapshot vision, reasoning from static images. In contrast, embodied agents require ambulatory vision, actively moving to obtain more informative views. We introduce Visually Grounded Active View Selection (VG-AVS), a task that selects the most informative next viewpoint using only the visual information in the current image, without relying on scene memory or external knowledge. To support this task, we construct a synthetic dataset with automatically generated paired query-target views and question-answer prompts. We also propose a framework that fine-tunes pretrained VLMs through supervised fine-tuning (SFT) followed by RL-based policy optimization. Our approach achieves strong question answering performance based on viewpoint selection and generalizes robustly to unseen synthetic and real scenes. Furthermore, incorporating our learned VG-AVS framework into existing scene-exploration-based EQA systems improves downstream question-answering accuracy.
ORIGEN: Zero-Shot 3D Orientation Grounding in Text-to-Image Generation
Mar 28, 2025We introduce ORIGEN, the first zero-shot method for 3D orientation grounding in text-to-image generation across multiple objects and diverse categories. While previous work on spatial grounding in image generation has mainly focused on 2D positioning, it lacks control over 3D orientation. To address this, we propose a reward-guided sampling approach using a pretrained discriminative model for 3D orientation estimation and a one-step text-to-image generative flow model. While gradient-ascent-based optimization is a natural choice for reward-based guidance, it struggles to maintain image realism. Instead, we adopt a sampling-based approach using Langevin dynamics, which extends gradient ascent by simply injecting random noise--requiring just a single additional line of code. Additionally, we introduce adaptive time rescaling based on the reward function to accelerate convergence. Our experiments show that ORIGEN outperforms both training-based and test-time guidance methods across quantitative metrics and user studies.
InstantDrag: Improving Interactivity in Drag-based Image Editing
Sep 13, 2024
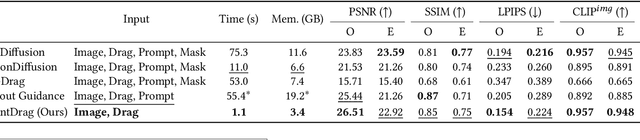

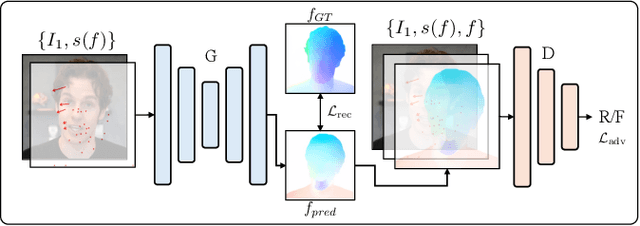
Drag-based image editing has recently gained popularity for its interactivity and precision. However, despite the ability of text-to-image models to generate samples within a second, drag editing still lags behind due to the challenge of accurately reflecting user interaction while maintaining image content. Some existing approaches rely on computationally intensive per-image optimization or intricate guidance-based methods, requiring additional inputs such as masks for movable regions and text prompts, thereby compromising the interactivity of the editing process. We introduce InstantDrag, an optimization-free pipeline that enhances interactivity and speed, requiring only an image and a drag instruction as input. InstantDrag consists of two carefully designed networks: a drag-conditioned optical flow generator (FlowGen) and an optical flow-conditioned diffusion model (FlowDiffusion). InstantDrag learns motion dynamics for drag-based image editing in real-world video datasets by decomposing the task into motion generation and motion-conditioned image generation. We demonstrate InstantDrag's capability to perform fast, photo-realistic edits without masks or text prompts through experiments on facial video datasets and general scenes. These results highlight the efficiency of our approach in handling drag-based image editing, making it a promising solution for interactive, real-time applications.