 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Multimodal Diffusion Transformers for Enhanced Prompt-based Image Editing
Aug 11, 2025Transformer-based diffusion models have recently superseded traditional U-Net architectures, with multimodal diffusion transformers (MM-DiT) emerging as the dominant approach in state-of-the-art models like Stable Diffusion 3 and Flux.1. Previous approaches have relied on unidirectional cross-attention mechanisms, with information flowing from text embeddings to image latents. In contrast, MMDiT introduces a unified attention mechanism that concatenates input projections from both modalities and performs a single full attention operation, allowing bidirectional information flow between text and image branches. This architectural shift presents significant challenges for existing editing techniques. In this paper, we systematically analyze MM-DiT's attention mechanism by decomposing attention matrices into four distinct blocks, revealing their inherent characteristics. Through these analyses, we propose a robust, prompt-based image editing method for MM-DiT that supports global to local edits across various MM-DiT variants, including few-step models. We believe our findings bridge the gap between existing U-Net-based methods and emerging architectures, offering deeper insights into MMDiT's behavioral patterns.
InstantDrag: Improving Interactivity in Drag-based Image Editing
Sep 13, 2024
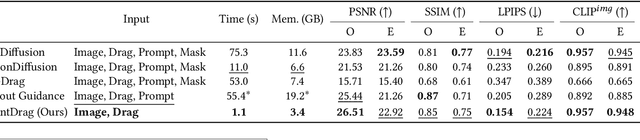

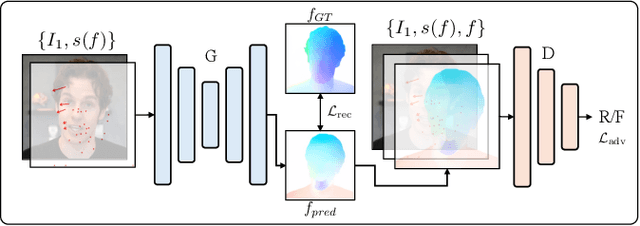
Drag-based image editing has recently gained popularity for its interactivity and precision. However, despite the ability of text-to-image models to generate samples within a second, drag editing still lags behind due to the challenge of accurately reflecting user interaction while maintaining image content. Some existing approaches rely on computationally intensive per-image optimization or intricate guidance-based methods, requiring additional inputs such as masks for movable regions and text prompts, thereby compromising the interactivity of the editing process. We introduce InstantDrag, an optimization-free pipeline that enhances interactivity and speed, requiring only an image and a drag instruction as input. InstantDrag consists of two carefully designed networks: a drag-conditioned optical flow generator (FlowGen) and an optical flow-conditioned diffusion model (FlowDiffusion). InstantDrag learns motion dynamics for drag-based image editing in real-world video datasets by decomposing the task into motion generation and motion-conditioned image generation. We demonstrate InstantDrag's capability to perform fast, photo-realistic edits without masks or text prompts through experiments on facial video datasets and general scenes. These results highlight the efficiency of our approach in handling drag-based image editing, making it a promising solution for interactive, real-time applications.
Fill-Up: Balancing Long-Tailed Data with Generative Models
Jun 12, 2023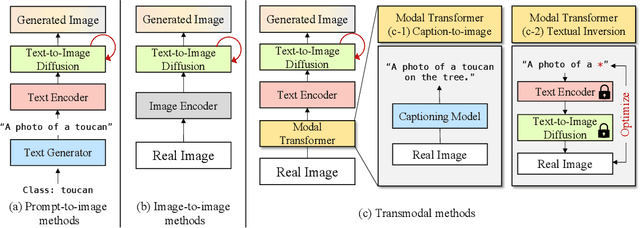

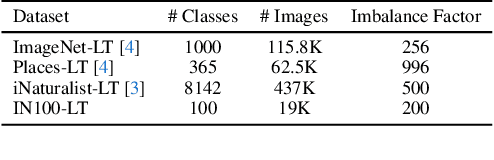
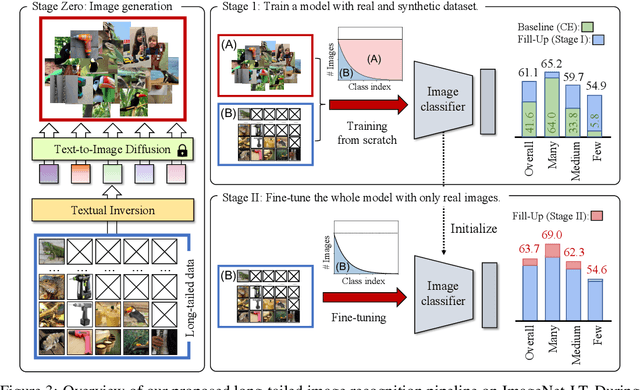
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.
StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis
Jun 19, 2022

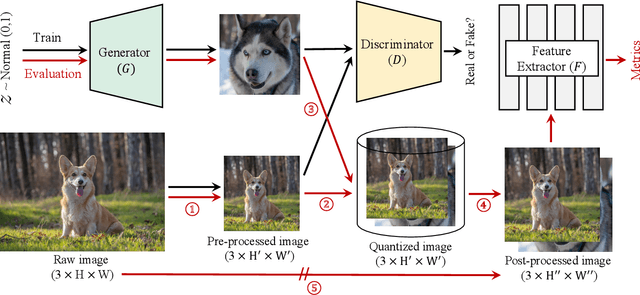

Generative Adversarial Network (GAN) is one of the state-of-the-art generative models for realistic image synthesis. While training and evaluating GAN becomes increasingly important, the current GAN research ecosystem does not provide reliable benchmarks for which the evaluation is conducted consistently and fairly. Furthermore, because there are few validated GAN implementations, researchers devote considerable time to reproducing baselines. We study the taxonomy of GAN approaches and present a new open-source library named StudioGAN. StudioGAN supports 7 GAN architectures, 9 conditioning methods, 4 adversarial losses, 13 regularization modules, 3 differentiable augmentations, 7 evaluation metrics, and 5 evaluation backbones. With our training and evaluation protocol, we present a large-scale benchmark using various datasets (CIFAR10, ImageNet, AFHQv2, FFHQ, and Baby/Papa/Granpa-ImageNet) and 3 different evaluation backbones (InceptionV3, SwAV, and Swin Transformer). Unlike other benchmarks used in the GAN community, we train representative GANs, including BigGAN, StyleGAN2, and StyleGAN3, in a unified training pipeline and quantify generation performance with 7 evaluation metrics. The benchmark evaluates other cutting-edge generative models(e.g., StyleGAN-XL, ADM, MaskGIT, and RQ-Transformer). StudioGAN provides GAN implementations, training, and evaluation scripts with the pre-trained weights. StudioGAN is available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.