 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Diffusion Models into Conditional GANs
May 09, 2024


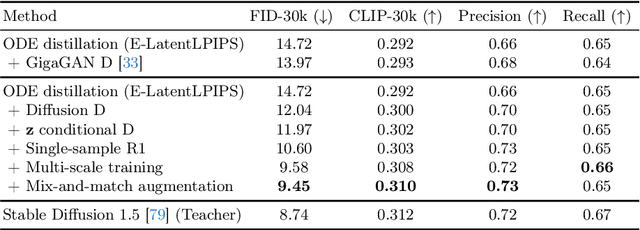
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models - DMD, SDXL-Turbo, and SDXL-Lightning - on the zero-shot COCO benchmark.
Holistic Evaluation of Text-To-Image Models
Nov 07, 2023



The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase.
RISCLIP: Referring Image Segmentation Framework using CLIP
Jun 14, 2023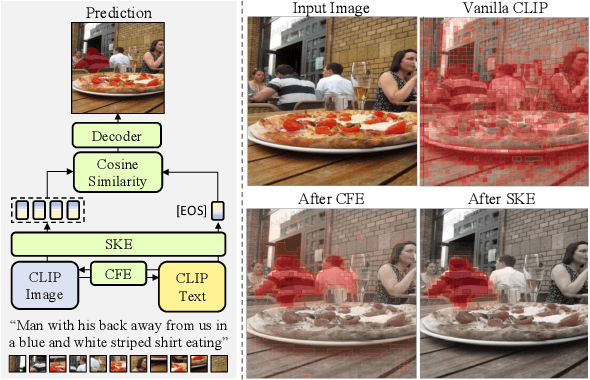



Recent advances in computer vision and natural language processing have naturally led to active research in multi-modal tasks, including Referring Image Segmentation (RIS). Recent approaches have advanced the frontier of RIS by impressive margins, but they require an additional pretraining stage on external visual grounding datasets to achieve the state-of-the-art performances. We attempt to break free from this requirement by effectively adapting Contrastive Language-Image Pretraining (CLIP) to RIS. We propose a novel framework that residually adapts frozen CLIP features to RIS with Fusion Adapters and Backbone Adapters. Freezing CLIP preserves the backbone's rich, general image-text alignment knowledge, whilst Fusion Adapters introduce multi-modal communication and Backbone Adapters inject new knowledge useful in solving RIS. Our method reaches a new state of the art on three major RIS benchmarks. We attain such performance without additional pretraining and thereby absolve the necessity of extra training and data preparation. Source code and model weights will be available upon publication.
Fill-Up: Balancing Long-Tailed Data with Generative Models
Jun 12, 2023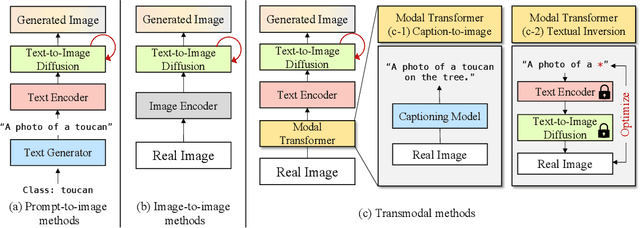

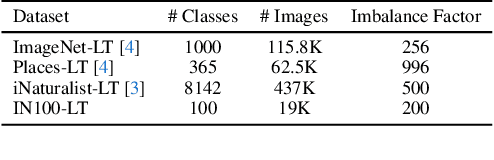
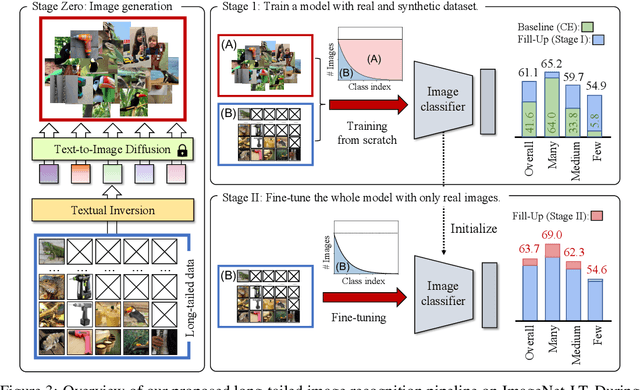
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.
Scaling up GANs for Text-to-Image Synthesis
Mar 09, 2023The recent success of text-to-image synthesis has taken the world by storm and captured the general public's imagination. From a technical standpoint, it also marked a drastic change in the favored architecture to design generative image models. GANs used to be the de facto choice, with techniques like StyleGAN. With DALL-E 2, auto-regressive and diffusion models became the new standard for large-scale generative models overnight. This rapid shift raises a fundamental question: can we scale up GANs to benefit from large datasets like LAION? We find that na\"Ively increasing the capacity of the StyleGAN architecture quickly becomes unstable. We introduce GigaGAN, a new GAN architecture that far exceeds this limit, demonstrating GANs as a viable option for text-to-image synthesis. GigaGAN offers three major advantages. First, it is orders of magnitude faster at inference time, taking only 0.13 seconds to synthesize a 512px image. Second, it can synthesize high-resolution images, for example, 16-megapixel pixels in 3.66 seconds. Finally, GigaGAN supports various latent space editing applications such as latent interpolation, style mixing, and vector arithmetic operations.
StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis
Jun 19, 2022

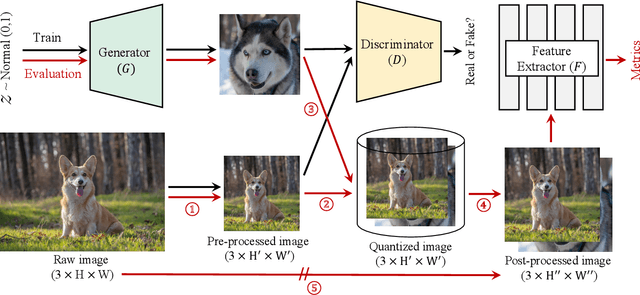

Generative Adversarial Network (GAN) is one of the state-of-the-art generative models for realistic image synthesis. While training and evaluating GAN becomes increasingly important, the current GAN research ecosystem does not provide reliable benchmarks for which the evaluation is conducted consistently and fairly. Furthermore, because there are few validated GAN implementations, researchers devote considerable time to reproducing baselines. We study the taxonomy of GAN approaches and present a new open-source library named StudioGAN. StudioGAN supports 7 GAN architectures, 9 conditioning methods, 4 adversarial losses, 13 regularization modules, 3 differentiable augmentations, 7 evaluation metrics, and 5 evaluation backbones. With our training and evaluation protocol, we present a large-scale benchmark using various datasets (CIFAR10, ImageNet, AFHQv2, FFHQ, and Baby/Papa/Granpa-ImageNet) and 3 different evaluation backbones (InceptionV3, SwAV, and Swin Transformer). Unlike other benchmarks used in the GAN community, we train representative GANs, including BigGAN, StyleGAN2, and StyleGAN3, in a unified training pipeline and quantify generation performance with 7 evaluation metrics. The benchmark evaluates other cutting-edge generative models(e.g., StyleGAN-XL, ADM, MaskGIT, and RQ-Transformer). StudioGAN provides GAN implementations, training, and evaluation scripts with the pre-trained weights. StudioGAN is available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training
Nov 01, 2021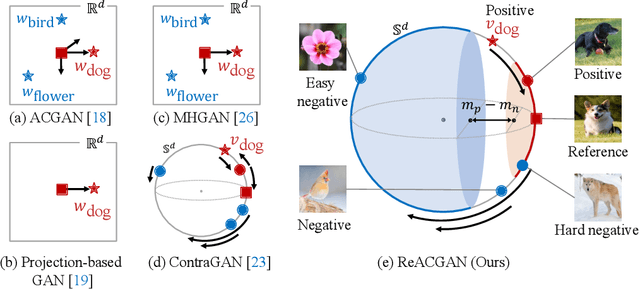
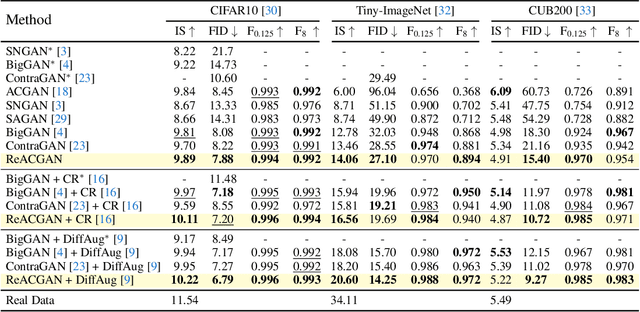
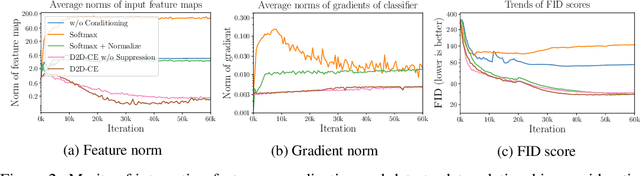
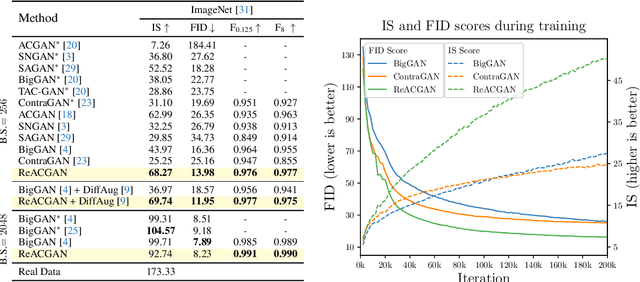
Conditional Generative Adversarial Networks (cGAN) generate realistic images by incorporating class information into GAN. While one of the most popular cGANs is an auxiliary classifier GAN with softmax cross-entropy loss (ACGAN), it is widely known that training ACGAN is challenging as the number of classes in the dataset increases. ACGAN also tends to generate easily classifiable samples with a lack of diversity. In this paper, we introduce two cures for ACGAN. First, we identify that gradient exploding in the classifier can cause an undesirable collapse in early training, and projecting input vectors onto a unit hypersphere can resolve the problem. Second, we propose the Data-to-Data Cross-Entropy loss (D2D-CE) to exploit relational information in the class-labeled dataset. On this foundation, we propose the Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). The experimental results show that ReACGAN achieves state-of-the-art generation results on CIFAR10, Tiny-ImageNet, CUB200, and ImageNet datasets. We also verify that ReACGAN benefits from differentiable augmentations and that D2D-CE harmonizes with StyleGAN2 architecture. Model weights and a software package that provides implementations of representative cGANs and all experiments in our paper are available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Contrastive Generative Adversarial Networks
Jun 23, 2020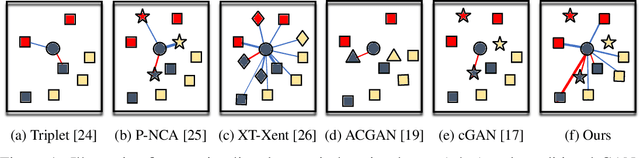



Conditional image synthesis is the task to generate high-fidelity diverse images using class label information. Although many studies have shown realistic results, there is room for improvement if the number of classes increases. In this paper, we propose a novel conditional contrastive loss to maximize a lower bound on mutual information between samples from the same class. Our framework, called Contrastive Generative Adversarial Networks (ContraGAN), learns to synthesize images using class information and data-to-data relations of training examples. The discriminator in ContraGAN discriminates the authenticity of given samples and maximizes the mutual information between embeddings of real images from the same class. Simultaneously, the generator attempts to synthesize images to fool the discriminator and to maximize the mutual information of fake images from the same class prior. The experimental results show that ContraGAN is robust to network architecture selection and outperforms state-of-the-art-models by 3.7% and 11.2% on CIFAR10 and Tiny ImageNet datasets, respectively, without any data augmentation. For the fair comparison, we re-implement the nine state-of-the-art-approaches to test various methods under the same condition. The software package that can re-produce all experiments is available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.