 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Utilizing High Sampling Rate ADCs for Cost Efficient MIMO Radios
Mar 10, 2025In the past decade, $>$1 Gsps ADCs have become commonplace and are used in many modern 5G base station chips. A major driving force behind this adoption is the benefits of digital up/down-conversion and improved digital filtering. Recent works have also advocated for utilizing this high sampling bandwidth to fit-in multiple MIMO streams, and reduce the number of ADCs required to build MIMO base-stations. This can potentially reduce the cost of Massive MIMO RUs, since ADCs are the most expensive electronics in the base-station radio chain. However, these recent works do not model the necessary decimation filters that exist in the signal path of these high sampling rate ADCs. We show in this short paper that because of the decimation filters, there can be introduction of cross-talks which can hinder the performance of these shared ADC interfaces. We simulate the shared ADC interface with Matlab 5G toolbox for uplink MIMO, and show that these cross-talks can be mitigated by performing MMSE equalization atop the PUSCH estimated channels.
MALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
PhaseMO: Future-Proof, Energy-efficient, Adaptive Massive MIMO
Jan 08, 2025



The rapid proliferation of devices and increasing data traffic in cellular networks necessitate advanced solutions to meet these escalating demands. Massive MIMO (Multiple Input Multiple Output) technology offers a promising approach, significantly enhancing throughput, coverage, and spatial multi-plexing. Despite its advantages, massive MIMO systems often lack flexible software controls over hardware, limiting their ability to optimize operational expenditure (OpEx) by reducing power consumption while maintaining performance. Current software-controlled methods, such as antenna muting combined with digital beamforming and hybrid beamforming, have notable limitations. Antenna muting struggles to maintain throughput and coverage, while hybrid beamforming faces hardware constraints that restrict scalability and future-proofing. This work presents PhaseMO, a versatile approach that adapts to varying network loads. PhaseMO effectively reduces power consumption in low-load scenarios without sacrificing coverage and overcomes the hardware limitations of hybrid beamforming, offering a scalable and future-proof solution. We will show that PhaseMO can achieve up to 30% improvement in energy efficiency while avoiding about 10% coverage reduction and 5dB increase in UE transmit power.
HourVideo: 1-Hour Video-Language Understanding
Nov 07, 2024
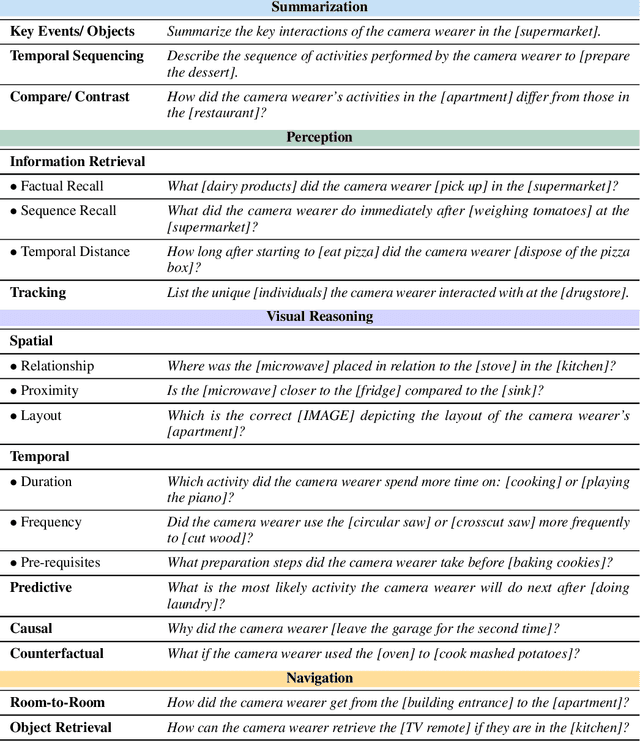

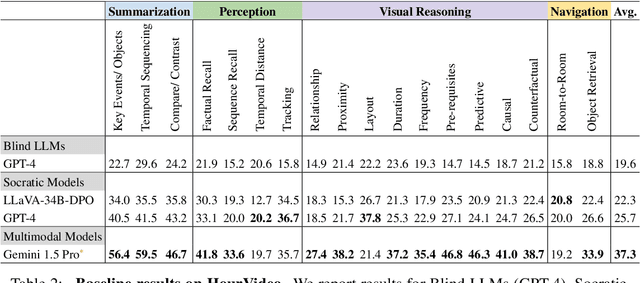
We present HourVideo, a benchmark dataset for hour-long video-language understanding. Our dataset consists of a novel task suite comprising summarization, perception (recall, tracking), visual reasoning (spatial, temporal, predictive, causal, counterfactual), and navigation (room-to-room, object retrieval) tasks. HourVideo includes 500 manually curated egocentric videos from the Ego4D dataset, spanning durations of 20 to 120 minutes, and features 12,976 high-quality, five-way multiple-choice questions. Benchmarking results reveal that multimodal models, including GPT-4 and LLaVA-NeXT, achieve marginal improvements over random chance. In stark contrast, human experts significantly outperform the state-of-the-art long-context multimodal model, Gemini Pro 1.5 (85.0% vs. 37.3%), highlighting a substantial gap in multimodal capabilities. Our benchmark, evaluation toolkit, prompts, and documentation are available at https://hourvideo.stanford.edu
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
May 22, 2024



Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
Densify & Conquer: Densified, smaller base-stations can conquer the increasing carbon footprint problem in nextG wireless
Mar 20, 2024



Connectivity on-the-go has been one of the most impressive technological achievements in the 2010s decade. However, multiple studies show that this has come at an expense of increased carbon footprint, that also rivals the entire aviation sector's carbon footprint. The two major contributors of this increased footprint are (a) smartphone batteries which affect the embodied footprint and (b) base-stations that occupy ever-increasing energy footprint to provide the last mile wireless connectivity to smartphones. The root-cause of both these turn out to be the same, which is communicating over the last-mile lossy wireless medium. We show in this paper, titled DensQuer, how base-station densification, which is to replace a single larger base-station with multiple smaller ones, reduces the effect of the last-mile wireless, and in effect conquers both these adverse sources of increased carbon footprint. Backed by a open-source ray-tracing computation framework (Sionna), we show how a strategic densification strategy can minimize the number of required smaller base-stations to practically achievable numbers, which lead to about 3x power-savings in the base-station network. Also, DensQuer is able to also reduce the required deployment height of base-stations to as low as 15m, that makes the smaller cells easily deployable on trees/street poles instead of requiring a dedicated tower. Further, by utilizing newly introduced hardware power rails in Google Pixel 7a and above phones, we also show that this strategic densified network leads to reduction in mobile transmit power by 10-15 dB, leading to about 3x reduction in total cellular power consumption, and about 50% increase in smartphone battery life when it communicates data via the cellular network.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Photorealistic Video Generation with Diffusion Models
Dec 11, 2023We present W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. Our approach has two key design decisions. First, we use a causal encoder to jointly compress images and videos within a unified latent space, enabling training and generation across modalities. Second, for memory and training efficiency, we use a window attention architecture tailored for joint spatial and spatiotemporal generative modeling. Taken together these design decisions enable us to achieve state-of-the-art performance on established video (UCF-101 and Kinetics-600) and image (ImageNet) generation benchmarks without using classifier free guidance. Finally, we also train a cascade of three models for the task of text-to-video generation consisting of a base latent video diffusion model, and two video super-resolution diffusion models to generate videos of $512 \times 896$ resolution at $8$ frames per second.
Holistic Evaluation of Text-To-Image Models
Nov 07, 2023



The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at https://crfm.stanford.edu/heim/v1.1.0 and the code at https://github.com/stanford-crfm/helm, which is integrated with the HELM codebase.