 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023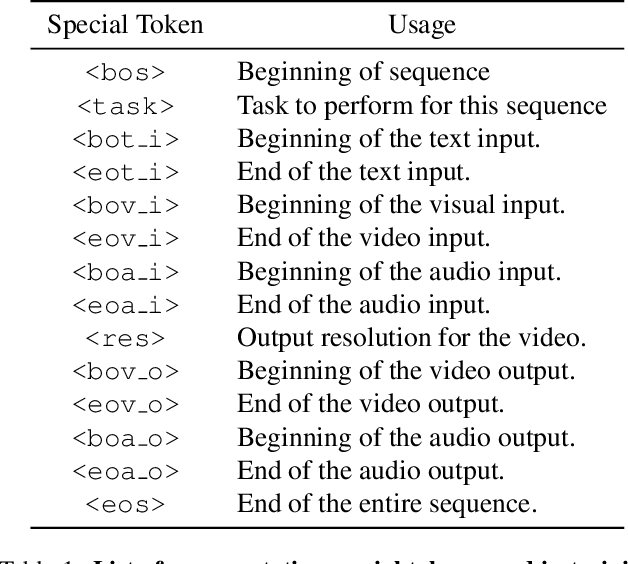



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Alternating Gradient Descent and Mixture-of-Experts for Integrated Multimodal Perception
May 10, 2023



We present Integrated Multimodal Perception (IMP), a simple and scalable multimodal multi-task training and modeling approach. IMP integrates multimodal inputs including image, video, text, and audio into a single Transformer encoder with minimal modality-specific components. IMP makes use of a novel design that combines Alternating Gradient Descent (AGD) and Mixture-of-Experts (MoE) for efficient model \& task scaling. We conduct extensive empirical studies about IMP and reveal the following key insights: 1) performing gradient descent updates by alternating on diverse heterogeneous modalities, loss functions, and tasks, while also varying input resolutions, efficiently improves multimodal understanding. 2) model sparsification with MoE on a single modality-agnostic encoder substantially improves the performance, outperforming dense models that use modality-specific encoders or additional fusion layers and greatly mitigating the conflicts between modalities. IMP achieves competitive performance on a wide range of downstream tasks including image classification, video classification, image-text, and video-text retrieval. Most notably, we train a sparse IMP-MoE-L focusing on video tasks that achieves new state-of-the-art in zero-shot video classification. Our model achieves 77.0% on Kinetics-400, 76.8% on Kinetics-600, and 76.8% on Kinetics-700 zero-shot classification accuracy, improving the previous state-of-the-art by +5%, +6.7%, and +5.8%, respectively, while using only 15% of their total training computational cost.
Scaling Multimodal Pre-Training via Cross-Modality Gradient Harmonization
Nov 03, 2022



Self-supervised pre-training recently demonstrates success on large-scale multimodal data, and state-of-the-art contrastive learning methods often enforce the feature consistency from cross-modality inputs, such as video/audio or video/text pairs. Despite its convenience to formulate and leverage in practice, such cross-modality alignment (CMA) is only a weak and noisy supervision, since two modalities can be semantically misaligned even they are temporally aligned. For example, even in the commonly adopted instructional videos, a speaker can sometimes refer to something that is not visually present in the current frame; and the semantic misalignment would only be more unpredictable for the raw videos from the internet. We conjecture that might cause conflicts and biases among modalities, and may hence prohibit CMA from scaling up to training with larger and more heterogeneous data. This paper first verifies our conjecture by observing that, even in the latest VATT pre-training using only instructional videos, there exist strong gradient conflicts between different CMA losses within the same video, audio, text triplet, indicating them as the noisy source of supervision. We then propose to harmonize such gradients, via two techniques: (i) cross-modality gradient realignment: modifying different CMA loss gradients for each sample triplet, so that their gradient directions are more aligned; and (ii) gradient-based curriculum learning: leveraging the gradient conflict information on an indicator of sample noisiness, to develop a curriculum learning strategy to prioritize training on less noisy sample triplets. Applying those techniques to pre-training VATT on the HowTo100M dataset, we consistently improve its performance on different downstream tasks. Moreover, we are able to scale VATT pre-training to more complicated non-narrative Youtube8M dataset to further improve the state-of-the-arts.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022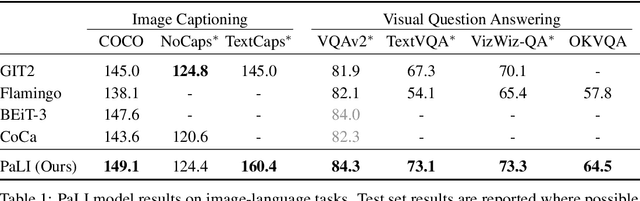

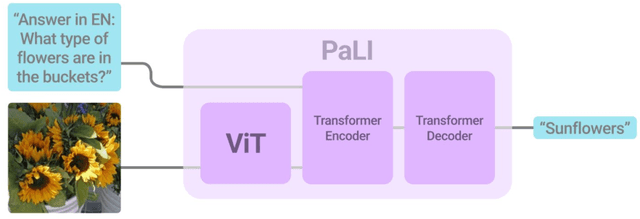

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Apr 22, 2021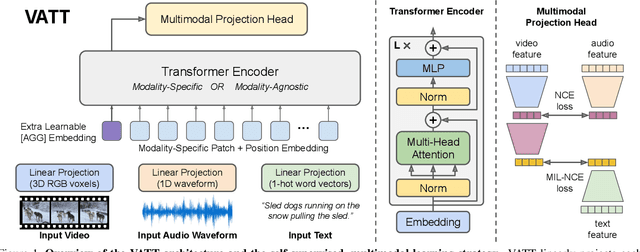
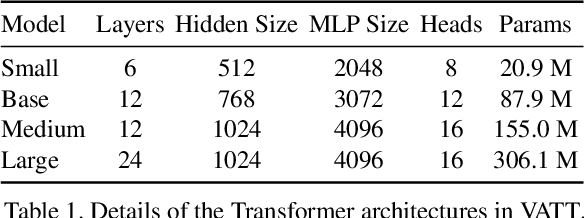
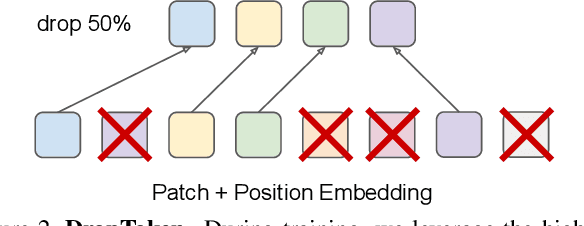
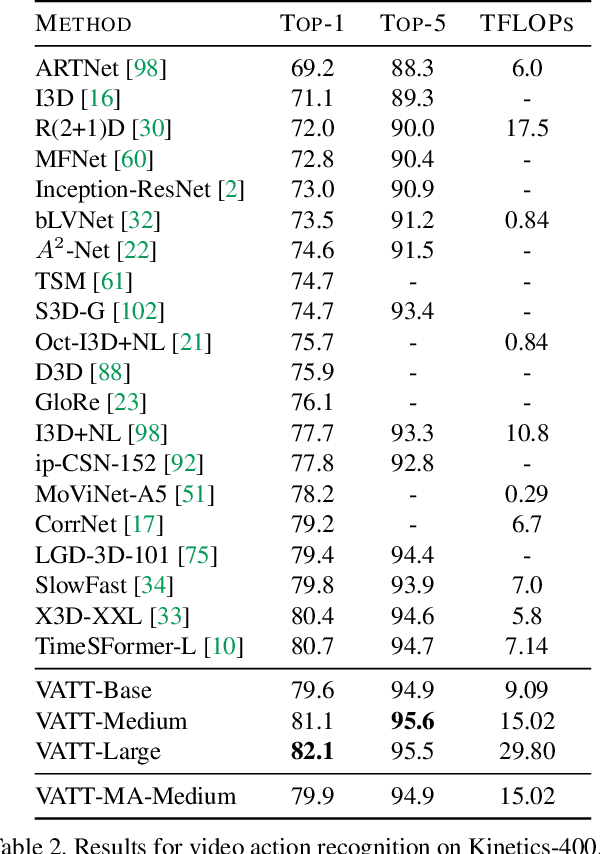
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT's vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT's audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Nov 18, 2020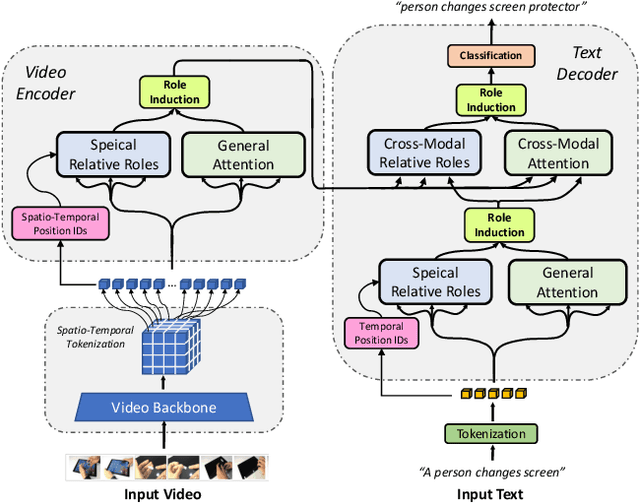
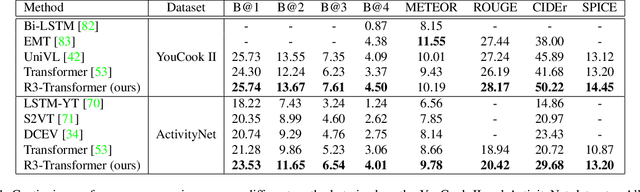
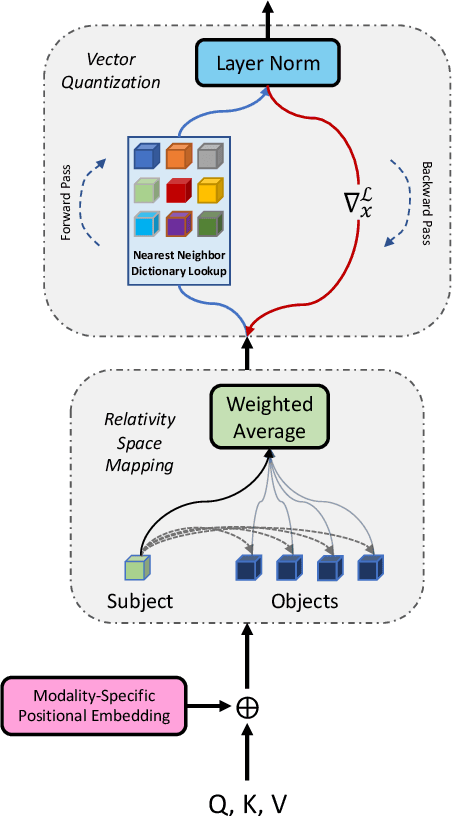
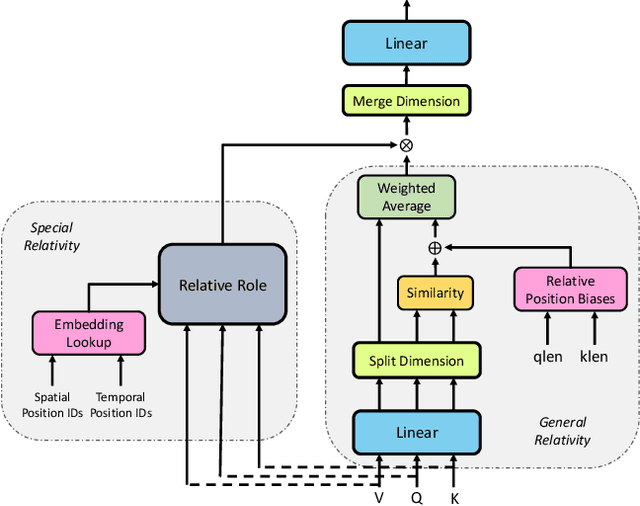
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding
Nov 28, 2018


We address the problem of phrase grounding by learning a multi-level common semantic space shared by the textual and visual modalities. This common space is instantiated at multiple layers of a Deep Convolutional Neural Network by exploiting its feature maps, as well as contextualized word-level and sentence-level embeddings extracted from a character-based language model. Following a dedicated non-linear mapping for visual features at each level, word, and sentence embeddings, we obtain a common space in which comparisons between the target text and the visual content at any semantic level can be performed simply with cosine similarity. We guide the model by a multi-level multimodal attention mechanism which outputs attended visual features at different semantic levels. The best level is chosen to be compared with text content for maximizing the pertinence scores of image-sentence pairs of the ground truth. Experiments conducted on three publicly available benchmarks show significant performance gains (20%-60% relative) over the state-of-the-art in phrase localization and set a new performance record on those datasets. We also provide a detailed ablation study to show the contribution of each element of our approach.
Lip2AudSpec: Speech reconstruction from silent lip movements video
Oct 26, 2017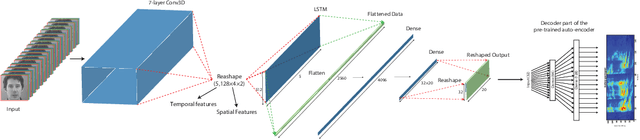
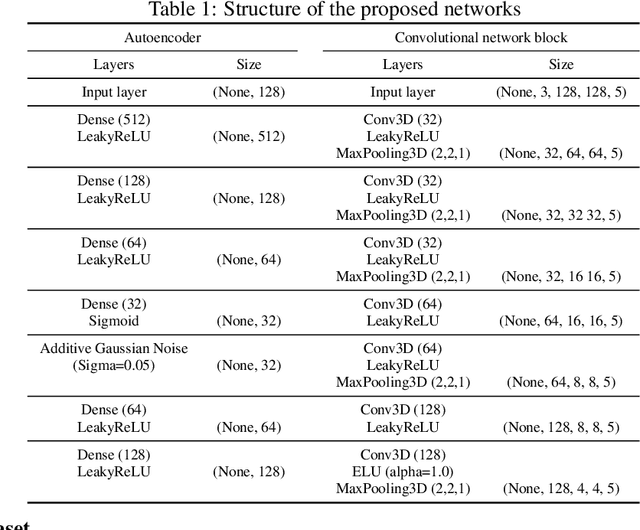

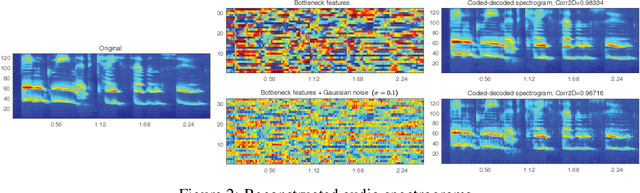
In this study, we propose a deep neural network for reconstructing intelligible speech from silent lip movement videos. We use auditory spectrogram as spectral representation of speech and its corresponding sound generation method resulting in a more natural sounding reconstructed speech. Our proposed network consists of an autoencoder to extract bottleneck features from the auditory spectrogram which is then used as target to our main lip reading network comprising of CNN, LSTM and fully connected layers. Our experiments show that the autoencoder is able to reconstruct the original auditory spectrogram with a 98% correlation and also improves the quality of reconstructed speech from the main lip reading network. Our model, trained jointly on different speakers is able to extract individual speaker characteristics and gives promising results of reconstructing intelligible speech with superior word recognition accuracy.