 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping A Framework to Support Human Evaluation of Bias in Generated Free Response Text
May 05, 2025LLM evaluation is challenging even the case of base models. In real world deployments, evaluation is further complicated by the interplay of task specific prompts and experiential context. At scale, bias evaluation is often based on short context, fixed choice benchmarks that can be rapidly evaluated, however, these can lose validity when the LLMs' deployed context differs. Large scale human evaluation is often seen as too intractable and costly. Here we present our journey towards developing a semi-automated bias evaluation framework for free text responses that has human insights at its core. We discuss how we developed an operational definition of bias that helped us automate our pipeline and a methodology for classifying bias beyond multiple choice. We additionally comment on how human evaluation helped us uncover problematic templates in a bias benchmark.
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding
Nov 28, 2018


We address the problem of phrase grounding by learning a multi-level common semantic space shared by the textual and visual modalities. This common space is instantiated at multiple layers of a Deep Convolutional Neural Network by exploiting its feature maps, as well as contextualized word-level and sentence-level embeddings extracted from a character-based language model. Following a dedicated non-linear mapping for visual features at each level, word, and sentence embeddings, we obtain a common space in which comparisons between the target text and the visual content at any semantic level can be performed simply with cosine similarity. We guide the model by a multi-level multimodal attention mechanism which outputs attended visual features at different semantic levels. The best level is chosen to be compared with text content for maximizing the pertinence scores of image-sentence pairs of the ground truth. Experiments conducted on three publicly available benchmarks show significant performance gains (20%-60% relative) over the state-of-the-art in phrase localization and set a new performance record on those datasets. We also provide a detailed ablation study to show the contribution of each element of our approach.
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018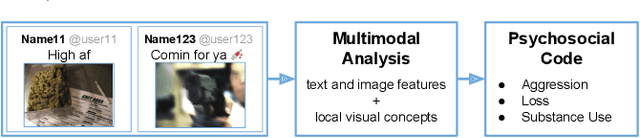
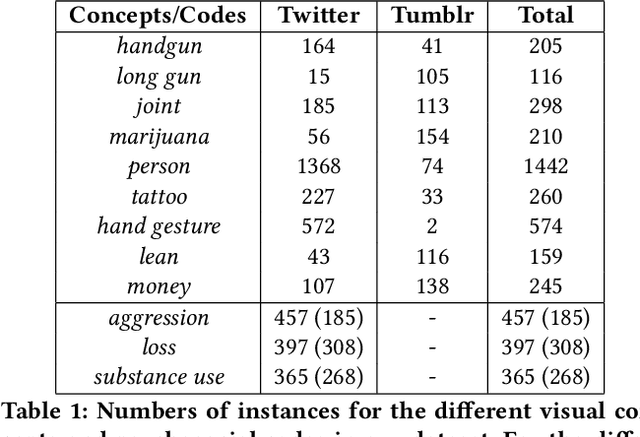

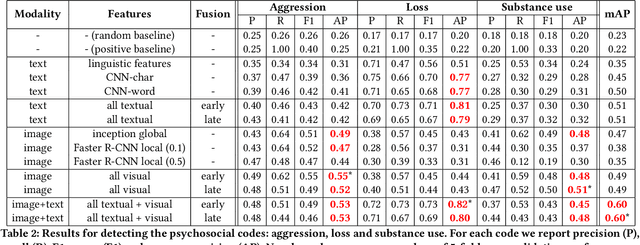
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.