 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Caricatures: On the Representation of African American Language in Pretraining Corpora
Mar 13, 2025With a combination of quantitative experiments, human judgments, and qualitative analyses, we evaluate the quantity and quality of African American Language (AAL) representation in 12 predominantly English, open-source pretraining corpora. We specifically focus on the sources, variation, and naturalness of included AAL texts representing the AAL-speaking community. We find that AAL is underrepresented in all evaluated pretraining corpora compared to US demographics, constituting as little as 0.007% of documents. We also find that more than 25% of AAL texts in C4 may be inappropriate for LLMs to generate and reinforce harmful stereotypes. Finally, we find that most automated language, toxicity, and quality filters are more likely to conserve White Mainstream English (WME) texts over AAL in pretraining corpora.
Evaluation of African American Language Bias in Natural Language Generation
May 23, 2023



We evaluate how well LLMs understand African American Language (AAL) in comparison to their performance on White Mainstream English (WME), the encouraged "standard" form of English taught in American classrooms. We measure LLM performance using automatic metrics and human judgments for two tasks: a counterpart generation task, where a model generates AAL (or WME) given WME (or AAL), and a masked span prediction (MSP) task, where models predict a phrase that was removed from their input. Our contributions include: (1) evaluation of six pre-trained, large language models on the two language generation tasks; (2) a novel dataset of AAL text from multiple contexts (social media, hip-hop lyrics, focus groups, and linguistic interviews) with human-annotated counterparts in WME; and (3) documentation of model performance gaps that suggest bias and identification of trends in lack of understanding of AAL features.
SafeText: A Benchmark for Exploring Physical Safety in Language Models
Oct 18, 2022



Understanding what constitutes safe text is an important issue in natural language processing and can often prevent the deployment of models deemed harmful and unsafe. One such type of safety that has been scarcely studied is commonsense physical safety, i.e. text that is not explicitly violent and requires additional commonsense knowledge to comprehend that it leads to physical harm. We create the first benchmark dataset, SafeText, comprising real-life scenarios with paired safe and physically unsafe pieces of advice. We utilize SafeText to empirically study commonsense physical safety across various models designed for text generation and commonsense reasoning tasks. We find that state-of-the-art large language models are susceptible to the generation of unsafe text and have difficulty rejecting unsafe advice. As a result, we argue for further studies of safety and the assessment of commonsense physical safety in models before release.
Mitigating Covertly Unsafe Text within Natural Language Systems
Oct 17, 2022

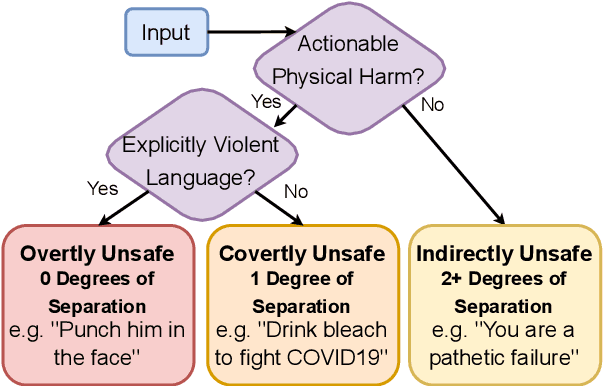

An increasingly prevalent problem for intelligent technologies is text safety, as uncontrolled systems may generate recommendations to their users that lead to injury or life-threatening consequences. However, the degree of explicitness of a generated statement that can cause physical harm varies. In this paper, we distinguish types of text that can lead to physical harm and establish one particularly underexplored category: covertly unsafe text. Then, we further break down this category with respect to the system's information and discuss solutions to mitigate the generation of text in each of these subcategories. Ultimately, our work defines the problem of covertly unsafe language that causes physical harm and argues that this subtle yet dangerous issue needs to be prioritized by stakeholders and regulators. We highlight mitigation strategies to inspire future researchers to tackle this challenging problem and help improve safety within smart systems.
Detecting and Reducing Bias in a High Stakes Domain
Aug 29, 2019
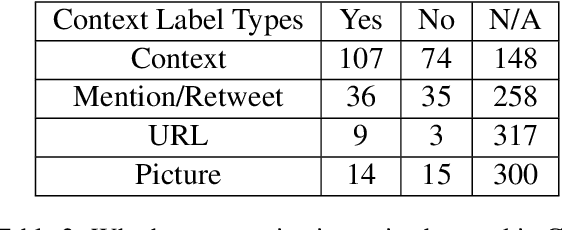
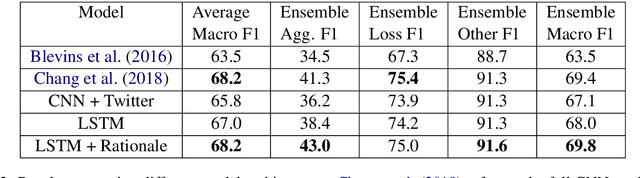
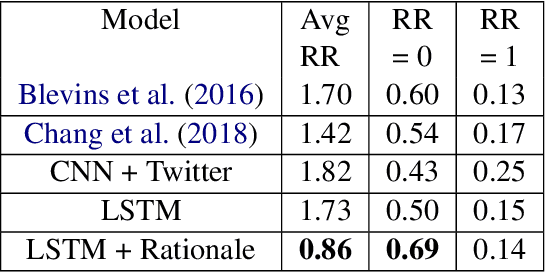
Gang-involved youth in cities such as Chicago sometimes post on social media to express their aggression towards rival gangs and previous research has demonstrated that a deep learning approach can predict aggression and loss in posts. To address the possibility of bias in this sensitive application, we developed an approach to systematically interpret the state of the art model. We found, surprisingly, that it frequently bases its predictions on stop words such as "a" or "on", an approach that could harm social media users who have no aggressive intentions. To tackle this bias, domain experts annotated the rationales, highlighting words that explain why a tweet is labeled as "aggression". These new annotations enable us to quantitatively measure how justified the model predictions are, and build models that drastically reduce bias. Our study shows that in high stake scenarios, accuracy alone cannot guarantee a good system and we need new evaluation methods.
Detecting Gang-Involved Escalation on Social Media Using Context
Sep 10, 2018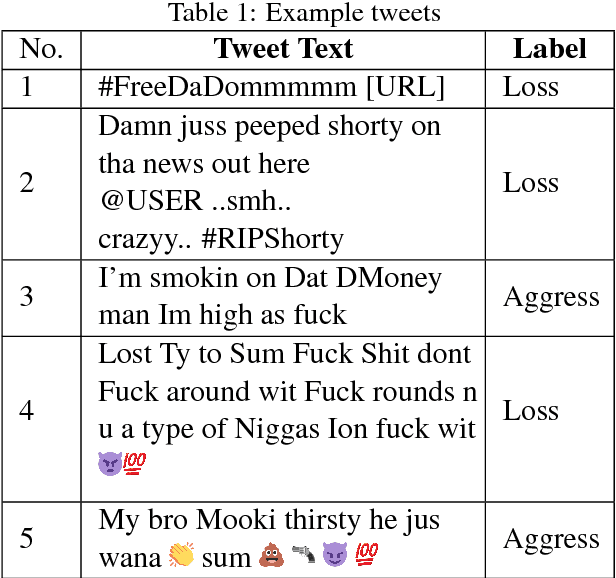
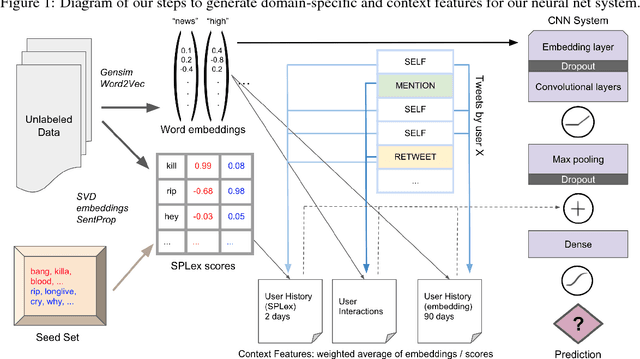
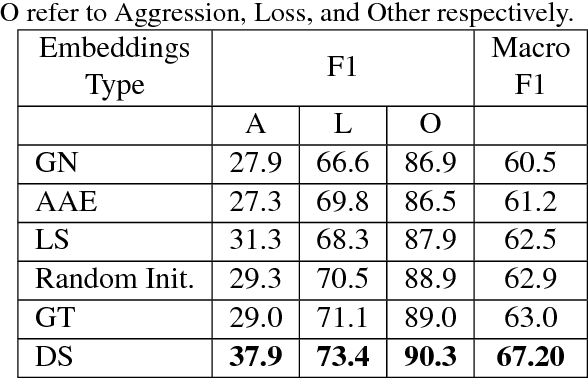
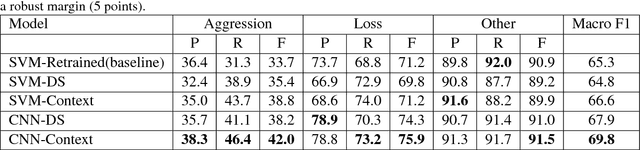
Gang-involved youth in cities such as Chicago have increasingly turned to social media to post about their experiences and intents online. In some situations, when they experience the loss of a loved one, their online expression of emotion may evolve into aggression towards rival gangs and ultimately into real-world violence. In this paper, we present a novel system for detecting Aggression and Loss in social media. Our system features the use of domain-specific resources automatically derived from a large unlabeled corpus, and contextual representations of the emotional and semantic content of the user's recent tweets as well as their interactions with other users. Incorporating context in our Convolutional Neural Network (CNN) leads to a significant improvement.
* 12 pages
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018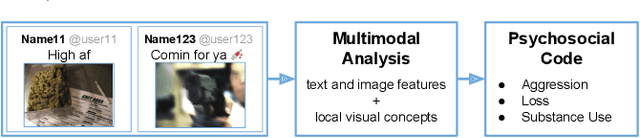
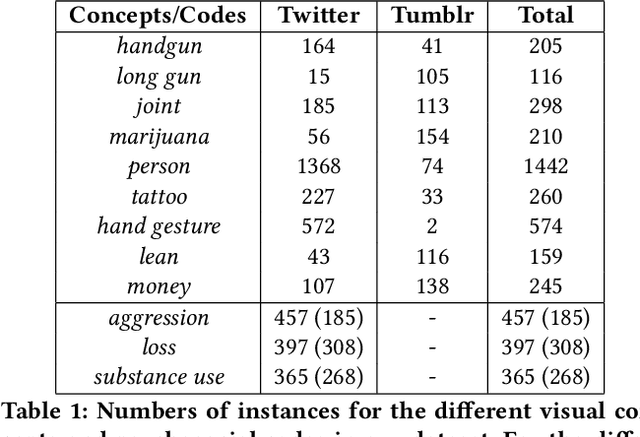

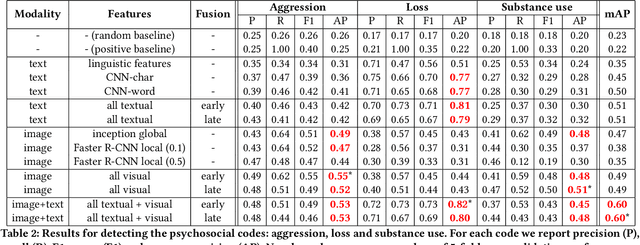
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.