 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes AI See like Art Historians? Interpreting How Vision Language Models Recognize Artistic Style
Mar 11, 2026VLMs have become increasingly proficient at a range of computer vision tasks, such as visual question answering and object detection. This includes increasingly strong capabilities in the domain of art, from analyzing artwork to generation of art. In an interdisciplinary collaboration between computer scientists and art historians, we characterize the mechanisms underlying VLMs' ability to predict artistic style and assess the extent to which they align with the criteria art historians use to reason about artistic style. We employ a latent-space decomposition approach to identify concepts that drive art style prediction and conduct quantitative evaluations, causal analysis and assessment by art historians. Our findings indicate that 73% of the extracted concepts are judged by art historians to exhibit a coherent and semantically meaningful visual feature and 90% of concepts used to predict style of a given artwork were judged relevant. In cases where an irrelevant concept was used to successfully predict style, art historians identified possible reasons for its success; for example, the model might "understand" a concept in more formal terms, such as dark/light contrasts.
PoSh: Using Scene Graphs To Guide LLMs-as-a-Judge For Detailed Image Descriptions
Oct 21, 2025While vision-language models (VLMs) have advanced into detailed image description, evaluation remains a challenge. Standard metrics (e.g. CIDEr, SPICE) were designed for short texts and tuned to recognize errors that are now uncommon, such as object misidentification. In contrast, long texts require sensitivity to attribute and relation attachments and scores that localize errors to particular text spans. In this work, we introduce PoSh, a metric for detailed image description that uses scene graphs as structured rubrics to guide LLMs-as-a-Judge, producing aggregate scores grounded in fine-grained errors (e.g. mistakes in compositional understanding). PoSh is replicable, interpretable and a better proxy for human raters than existing metrics (including GPT4o-as-a-Judge). To validate PoSh, we introduce a challenging new dataset, DOCENT. This novel benchmark contains artwork, paired with expert-written references, and model-generated descriptions, augmented with granular and coarse judgments of their quality from art history students. Thus, DOCENT enables evaluating both detailed image description metrics and detailed image description itself in a challenging new domain. We show that PoSh achieves stronger correlations (+0.05 Spearman $\rho$) with the human judgments in DOCENT than the best open-weight alternatives, is robust to image type (using CapArena, an existing dataset of web imagery) and is a capable reward function, outperforming standard supervised fine-tuning. Then, using PoSh, we characterize the performance of open and closed models in describing the paintings, sketches and statues in DOCENT and find that foundation models struggle to achieve full, error-free coverage of images with rich scene dynamics, establishing a demanding new task to gauge VLM progress. Through both PoSh and DOCENT, we hope to enable advances in important areas such as assistive text generation.
Data Caricatures: On the Representation of African American Language in Pretraining Corpora
Mar 13, 2025With a combination of quantitative experiments, human judgments, and qualitative analyses, we evaluate the quantity and quality of African American Language (AAL) representation in 12 predominantly English, open-source pretraining corpora. We specifically focus on the sources, variation, and naturalness of included AAL texts representing the AAL-speaking community. We find that AAL is underrepresented in all evaluated pretraining corpora compared to US demographics, constituting as little as 0.007% of documents. We also find that more than 25% of AAL texts in C4 may be inappropriate for LLMs to generate and reinforce harmful stereotypes. Finally, we find that most automated language, toxicity, and quality filters are more likely to conserve White Mainstream English (WME) texts over AAL in pretraining corpora.
Enhancing Multimodal Affective Analysis with Learned Live Comment Features
Oct 21, 2024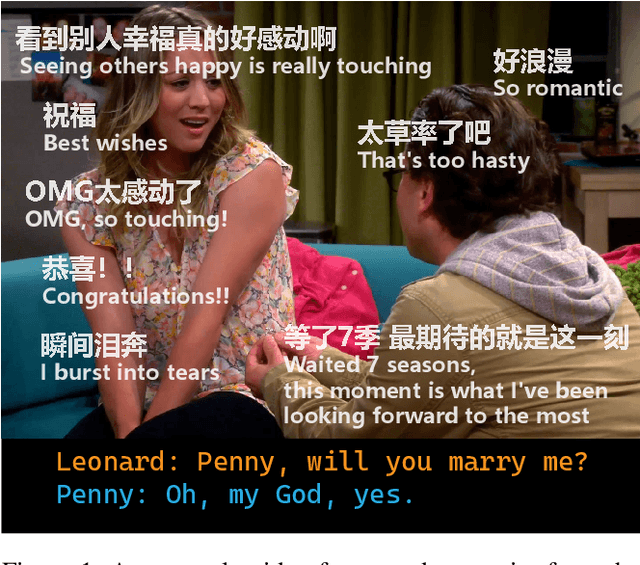
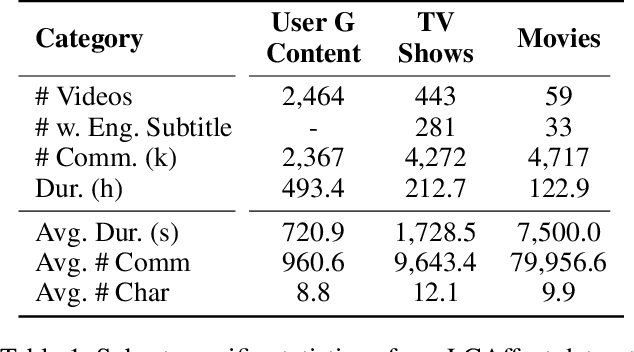
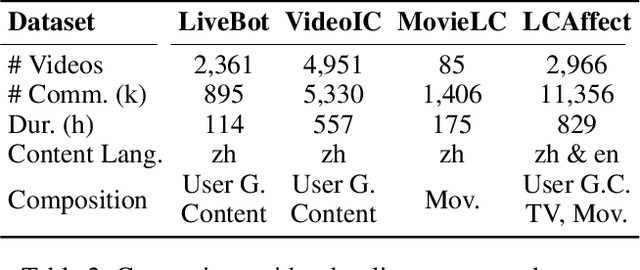

Live comments, also known as Danmaku, are user-generated messages that are synchronized with video content. These comments overlay directly onto streaming videos, capturing viewer emotions and reactions in real-time. While prior work has leveraged live comments in affective analysis, its use has been limited due to the relative rarity of live comments across different video platforms. To address this, we first construct the Live Comment for Affective Analysis (LCAffect) dataset which contains live comments for English and Chinese videos spanning diverse genres that elicit a wide spectrum of emotions. Then, using this dataset, we use contrastive learning to train a video encoder to produce synthetic live comment features for enhanced multimodal affective content analysis. Through comprehensive experimentation on a wide range of affective analysis tasks (sentiment, emotion recognition, and sarcasm detection) in both English and Chinese, we demonstrate that these synthetic live comment features significantly improve performance over state-of-the-art methods.
See It from My Perspective: Diagnosing the Western Cultural Bias of Large Vision-Language Models in Image Understanding
Jun 17, 2024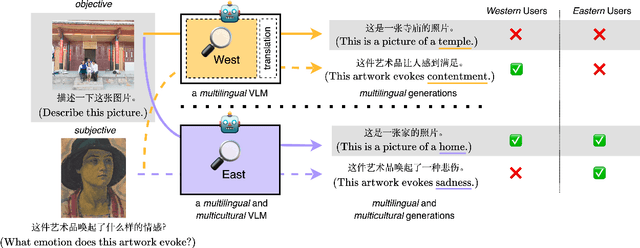



Vision-language models (VLMs) can respond to queries about images in many languages. However, beyond language, culture affects how we see things. For example, individuals from Western cultures focus more on the central figure in an image while individuals from Eastern cultures attend more to scene context. In this work, we present a novel investigation that demonstrates and localizes VLMs' Western bias in image understanding. We evaluate large VLMs across subjective and objective visual tasks with culturally diverse images and annotations. We find that VLMs perform better on the Western subset than the Eastern subset of each task. Controlled experimentation tracing the source of this bias highlights the importance of a diverse language mix in text-only pre-training for building equitable VLMs, even when inference is performed in English. Moreover, while prompting in the language of a target culture can lead to reductions in bias, it is not a substitute for building AI more representative of the world's languages.
Social Orientation: A New Feature for Dialogue Analysis
Feb 26, 2024



There are many settings where it is useful to predict and explain the success or failure of a dialogue. Circumplex theory from psychology models the social orientations (e.g., Warm-Agreeable, Arrogant-Calculating) of conversation participants and can be used to predict and explain the outcome of social interactions. Our work is novel in its systematic application of social orientation tags to modeling conversation outcomes. In this paper, we introduce a new data set of dialogue utterances machine-labeled with social orientation tags. We show that social orientation tags improve task performance, especially in low-resource settings, on both English and Chinese language benchmarks. We also demonstrate how social orientation tags help explain the outcomes of social interactions when used in neural models. Based on these results showing the utility of social orientation tags for dialogue outcome prediction tasks, we release our data sets, code, and models that are fine-tuned to predict social orientation tags on dialogue utterances.
Check-COVID: Fact-Checking COVID-19 News Claims with Scientific Evidence
May 29, 2023



We present a new fact-checking benchmark, Check-COVID, that requires systems to verify claims about COVID-19 from news using evidence from scientific articles. This approach to fact-checking is particularly challenging as it requires checking internet text written in everyday language against evidence from journal articles written in formal academic language. Check-COVID contains 1, 504 expert-annotated news claims about the coronavirus paired with sentence-level evidence from scientific journal articles and veracity labels. It includes both extracted (journalist-written) and composed (annotator-written) claims. Experiments using both a fact-checking specific system and GPT-3.5, which respectively achieve F1 scores of 76.99 and 69.90 on this task, reveal the difficulty of automatically fact-checking both claim types and the importance of in-domain data for good performance. Our data and models are released publicly at https://github.com/posuer/Check-COVID.
Seeded Hierarchical Clustering for Expert-Crafted Taxonomies
May 23, 2022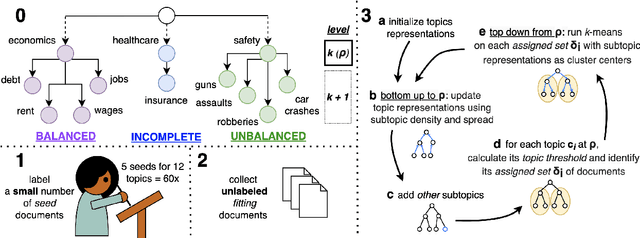
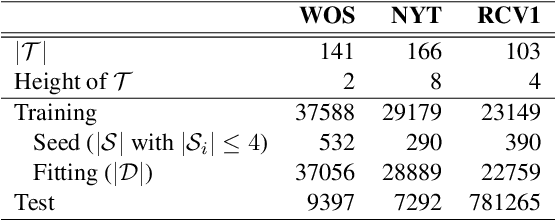
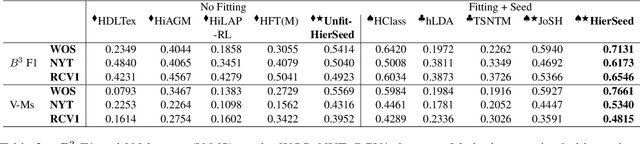
Practitioners from many disciplines (e.g., political science) use expert-crafted taxonomies to make sense of large, unlabeled corpora. In this work, we study Seeded Hierarchical Clustering (SHC): the task of automatically fitting unlabeled data to such taxonomies using only a small set of labeled examples. We propose HierSeed, a novel weakly supervised algorithm for this task that uses only a small set of labeled seed examples. It is both data and computationally efficient. HierSeed assigns documents to topics by weighing document density against topic hierarchical structure. It outperforms both unsupervised and supervised baselines for the SHC task on three real-world datasets.
Event Guided Denoising for Multilingual Relation Learning
Dec 04, 2020


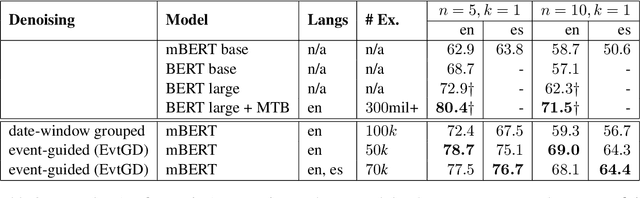
General purpose relation extraction has recently seen considerable gains in part due to a massively data-intensive distant supervision technique from Soares et al. (2019) that produces state-of-the-art results across many benchmarks. In this work, we present a methodology for collecting high quality training data for relation extraction from unlabeled text that achieves a near-recreation of their zero-shot and few-shot results at a fraction of the training cost. Our approach exploits the predictable distributional structure of date-marked news articles to build a denoised corpus -- the extraction process filters out low quality examples. We show that a smaller multilingual encoder trained on this corpus performs comparably to the current state-of-the-art (when both receive little to no fine-tuning) on few-shot and standard relation benchmarks in English and Spanish despite using many fewer examples (50k vs. 300mil+).
Multi-Modal Emotion Detection with Transfer Learning
Nov 13, 2020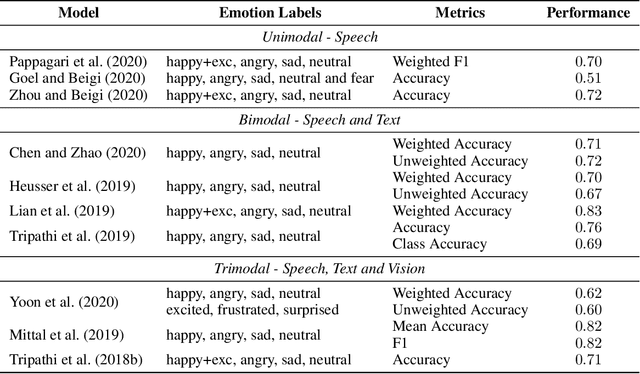
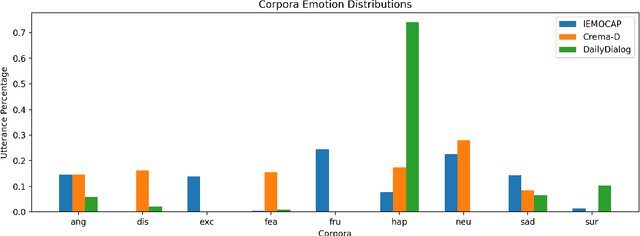

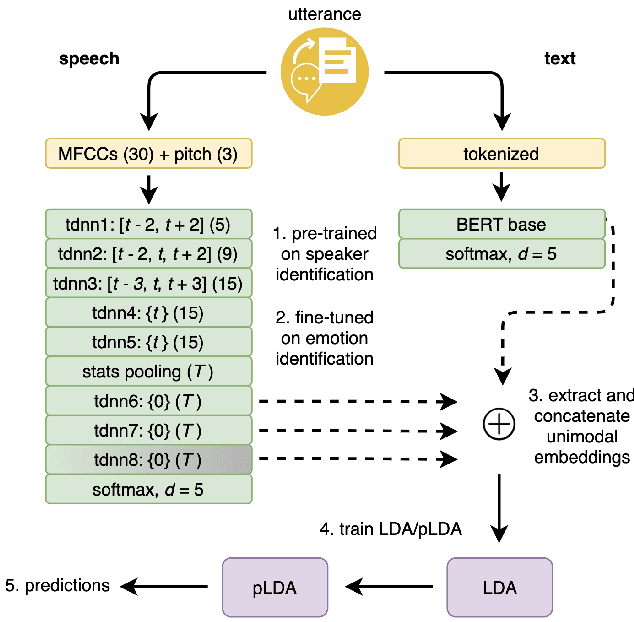
Automated emotion detection in speech is a challenging task due to the complex interdependence between words and the manner in which they are spoken. It is made more difficult by the available datasets; their small size and incompatible labeling idiosyncrasies make it hard to build generalizable emotion detection systems. To address these two challenges, we present a multi-modal approach that first transfers learning from related tasks in speech and text to produce robust neural embeddings and then uses these embeddings to train a pLDA classifier that is able to adapt to previously unseen emotions and domains. We begin by training a multilayer TDNN on the task of speaker identification with the VoxCeleb corpora and then fine-tune it on the task of emotion identification with the Crema-D corpus. Using this network, we extract speech embeddings for Crema-D from each of its layers, generate and concatenate text embeddings for the accompanying transcripts using a fine-tuned BERT model and then train an LDA - pLDA classifier on the resulting dense representations. We exhaustively evaluate the predictive power of every component: the TDNN alone, speech embeddings from each of its layers alone, text embeddings alone and every combination thereof. Our best variant, trained on only VoxCeleb and Crema-D and evaluated on IEMOCAP, achieves an EER of 38.05%. Including a portion of IEMOCAP during training produces a 5-fold averaged EER of 25.72% (For comparison, 44.71% of the gold-label annotations include at least one annotator who disagrees).