 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee It from My Perspective: Diagnosing the Western Cultural Bias of Large Vision-Language Models in Image Understanding
Paper and Code
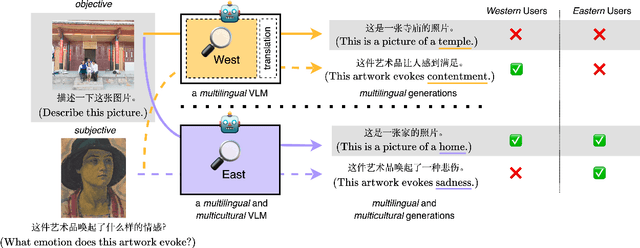



Vision-language models (VLMs) can respond to queries about images in many languages. However, beyond language, culture affects how we see things. For example, individuals from Western cultures focus more on the central figure in an image while individuals from Eastern cultures attend more to scene context. In this work, we present a novel investigation that demonstrates and localizes VLMs' Western bias in image understanding. We evaluate large VLMs across subjective and objective visual tasks with culturally diverse images and annotations. We find that VLMs perform better on the Western subset than the Eastern subset of each task. Controlled experimentation tracing the source of this bias highlights the importance of a diverse language mix in text-only pre-training for building equitable VLMs, even when inference is performed in English. Moreover, while prompting in the language of a target culture can lead to reductions in bias, it is not a substitute for building AI more representative of the world's languages.