 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Representations of Character Significance in Novels
Jan 21, 2026Characters in novels have typically been modeled based on their presence in scenes in narrative, considering aspects like their actions, named mentions, and dialogue. This conception of character places significant emphasis on the main character who is present in the most scenes. In this work, we instead adopt a framing developed from a new literary theory proposing a six-component structural model of character. This model enables a comprehensive approach to character that accounts for the narrator-character distinction and includes a component neglected by prior methods, discussion by other characters. We compare general-purpose LLMs with task-specific transformers for operationalizing this model of character on major 19th-century British realist novels. Our methods yield both component-level and graph representations of character discussion. We then demonstrate that these representations allow us to approach literary questions at scale from a new computational lens. Specifically, we explore Woloch's classic "the one vs the many" theory of character centrality and the gendered dynamics of character discussion.
Guiding LLM Decision-Making with Fairness Reward Models
Jul 15, 2025



Large language models are increasingly used to support high-stakes decisions, potentially influencing who is granted bail or receives a loan. Naive chain-of-thought sampling can improve average decision accuracy, but has also been shown to amplify unfair bias. To address this challenge and enable the trustworthy use of reasoning models in high-stakes decision-making, we propose a framework for training a generalizable Fairness Reward Model (FRM). Our model assigns a fairness score to LLM reasoning, enabling the system to down-weight biased trajectories and favor equitable ones when aggregating decisions across reasoning chains. We show that a single Fairness Reward Model, trained on weakly supervised, LLM-annotated examples of biased versus unbiased reasoning, transfers across tasks, domains, and model families without additional fine-tuning. Applied to real-world decision-making tasks including recidivism prediction and social media moderation, we show that our approach consistently improves fairness while matching, or even surpassing, baseline accuracy.
AdvSumm: Adversarial Training for Bias Mitigation in Text Summarization
Jun 06, 2025Large Language Models (LLMs) have achieved impressive performance in text summarization and are increasingly deployed in real-world applications. However, these systems often inherit associative and framing biases from pre-training data, leading to inappropriate or unfair outputs in downstream tasks. In this work, we present AdvSumm (Adversarial Summarization), a domain-agnostic training framework designed to mitigate bias in text summarization through improved generalization. Inspired by adversarial robustness, AdvSumm introduces a novel Perturber component that applies gradient-guided perturbations at the embedding level of Sequence-to-Sequence models, enhancing the model's robustness to input variations. We empirically demonstrate that AdvSumm effectively reduces different types of bias in summarization-specifically, name-nationality bias and political framing bias-without compromising summarization quality. Compared to standard transformers and data augmentation techniques like back-translation, AdvSumm achieves stronger bias mitigation performance across benchmark datasets.
Counterfactual Simulatability of LLM Explanations for Generation Tasks
May 27, 2025LLMs can be unpredictable, as even slight alterations to the prompt can cause the output to change in unexpected ways. Thus, the ability of models to accurately explain their behavior is critical, especially in high-stakes settings. One approach for evaluating explanations is counterfactual simulatability, how well an explanation allows users to infer the model's output on related counterfactuals. Counterfactual simulatability has been previously studied for yes/no question answering tasks. We provide a general framework for extending this method to generation tasks, using news summarization and medical suggestion as example use cases. We find that while LLM explanations do enable users to better predict LLM outputs on counterfactuals in the summarization setting, there is significant room for improvement for medical suggestion. Furthermore, our results suggest that the evaluation for counterfactual simulatability may be more appropriate for skill-based tasks as opposed to knowledge-based tasks.
Is the Top Still Spinning? Evaluating Subjectivity in Narrative Understanding
Apr 01, 2025

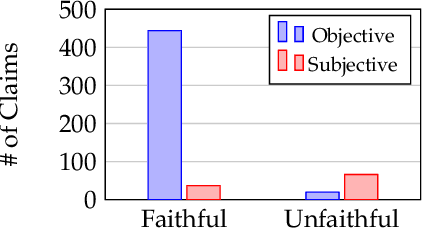
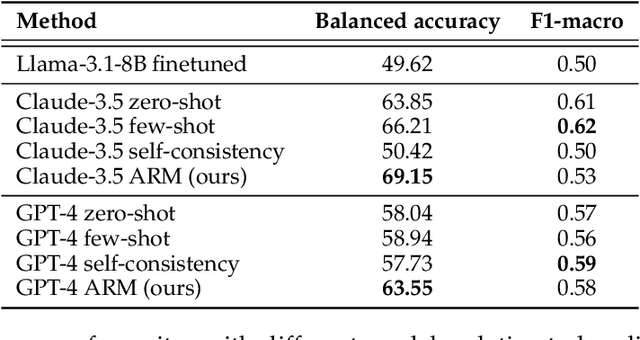
Determining faithfulness of a claim to a source document is an important problem across many domains. This task is generally treated as a binary judgment of whether the claim is supported or unsupported in relation to the source. In many cases, though, whether a claim is supported can be ambiguous. For instance, it may depend on making inferences from given evidence, and different people can reasonably interpret the claim as either supported or unsupported based on their agreement with those inferences. Forcing binary labels upon such claims lowers the reliability of evaluation. In this work, we reframe the task to manage the subjectivity involved with factuality judgments of ambiguous claims. We introduce LLM-generated edits of summaries as a method of providing a nuanced evaluation of claims: how much does a summary need to be edited to be unambiguous? Whether a claim gets rewritten and how much it changes can be used as an automatic evaluation metric, the Ambiguity Rewrite Metric (ARM), with a much richer feedback signal than a binary judgment of faithfulness. We focus on the area of narrative summarization as it is particularly rife with ambiguity and subjective interpretation. We show that ARM produces a 21% absolute improvement in annotator agreement on claim faithfulness, indicating that subjectivity is reduced.
STORYSUMM: Evaluating Faithfulness in Story Summarization
Jul 09, 2024
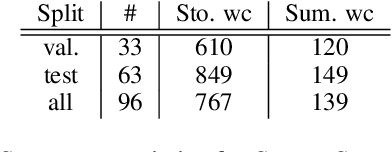
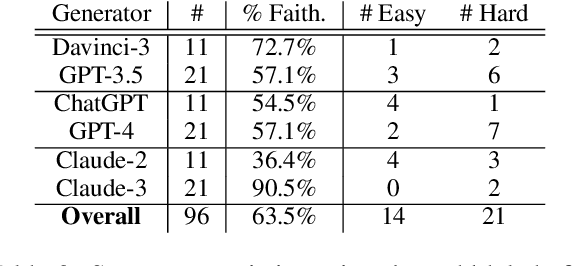

Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, STORYSUMM, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers
Mar 02, 2024We evaluate recent Large language Models (LLMs) on the challenging task of summarizing short stories, which can be lengthy, and include nuanced subtext or scrambled timelines. Importantly, we work directly with authors to ensure that the stories have not been shared online (and therefore are unseen by the models), and to obtain informed evaluations of summary quality using judgments from the authors themselves. Through quantitative and qualitative analysis grounded in narrative theory, we compare GPT-4, Claude-2.1, and LLama-2-70B. We find that all three models make faithfulness mistakes in over 50% of summaries and struggle to interpret difficult subtext. However, at their best, the models can provide thoughtful thematic analysis of stories. We additionally demonstrate that LLM judgments of summary quality do not match the feedback from the writers.
Check-COVID: Fact-Checking COVID-19 News Claims with Scientific Evidence
May 29, 2023



We present a new fact-checking benchmark, Check-COVID, that requires systems to verify claims about COVID-19 from news using evidence from scientific articles. This approach to fact-checking is particularly challenging as it requires checking internet text written in everyday language against evidence from journal articles written in formal academic language. Check-COVID contains 1, 504 expert-annotated news claims about the coronavirus paired with sentence-level evidence from scientific journal articles and veracity labels. It includes both extracted (journalist-written) and composed (annotator-written) claims. Experiments using both a fact-checking specific system and GPT-3.5, which respectively achieve F1 scores of 76.99 and 69.90 on this task, reveal the difficulty of automatically fact-checking both claim types and the importance of in-domain data for good performance. Our data and models are released publicly at https://github.com/posuer/Check-COVID.
Unsupervised Selective Rationalization with Noise Injection
May 27, 2023A major issue with using deep learning models in sensitive applications is that they provide no explanation for their output. To address this problem, unsupervised selective rationalization produces rationales alongside predictions by chaining two jointly-trained components, a rationale generator and a predictor. Although this architecture guarantees that the prediction relies solely on the rationale, it does not ensure that the rationale contains a plausible explanation for the prediction. We introduce a novel training technique that effectively limits generation of implausible rationales by injecting noise between the generator and the predictor. Furthermore, we propose a new benchmark for evaluating unsupervised selective rationalization models using movie reviews from existing datasets. We achieve sizeable improvements in rationale plausibility and task accuracy over the state-of-the-art across a variety of tasks, including our new benchmark, while maintaining or improving model faithfulness.
Detecting Harmful Agendas in News Articles
Jan 31, 2023Manipulated news online is a growing problem which necessitates the use of automated systems to curtail its spread. We argue that while misinformation and disinformation detection have been studied, there has been a lack of investment in the important open challenge of detecting harmful agendas in news articles; identifying harmful agendas is critical to flag news campaigns with the greatest potential for real world harm. Moreover, due to real concerns around censorship, harmful agenda detectors must be interpretable to be effective. In this work, we propose this new task and release a dataset, NewsAgendas, of annotated news articles for agenda identification. We show how interpretable systems can be effective on this task and demonstrate that they can perform comparably to black-box models.