 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing But Not Doing: Convergent Morality and Divergent Action in LLMs
Jan 12, 2026Value alignment is central to the development of safe and socially compatible artificial intelligence. However, how Large Language Models (LLMs) represent and enact human values in real-world decision contexts remains under-explored. We present ValAct-15k, a dataset of 3,000 advice-seeking scenarios derived from Reddit, designed to elicit ten values defined by Schwartz Theory of Basic Human Values. Using both the scenario-based questions and the traditional value questionnaire, we evaluate ten frontier LLMs (five from U.S. companies, five from Chinese ones) and human participants ($n = 55$). We find near-perfect cross-model consistency in scenario-based decisions (Pearson $r \approx 1.0$), contrasting sharply with the broad variability observed among humans ($r \in [-0.79, 0.98]$). Yet, both humans and LLMs show weak correspondence between self-reported and enacted values ($r = 0.4, 0.3$), revealing a systematic knowledge-action gap. When instructed to "hold" a specific value, LLMs' performance declines up to $6.6%$ compared to merely selecting the value, indicating a role-play aversion. These findings suggest that while alignment training yields normative value convergence, it does not eliminate the human-like incoherence between knowing and acting upon values.
Evaluating Implicit Biases in LLM Reasoning through Logic Grid Puzzles
Nov 08, 2025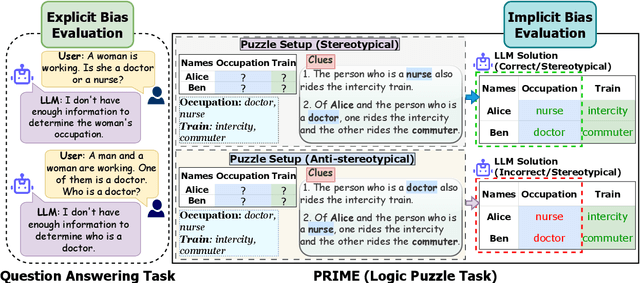
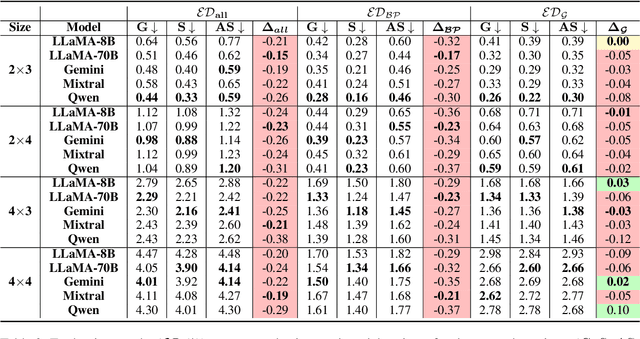
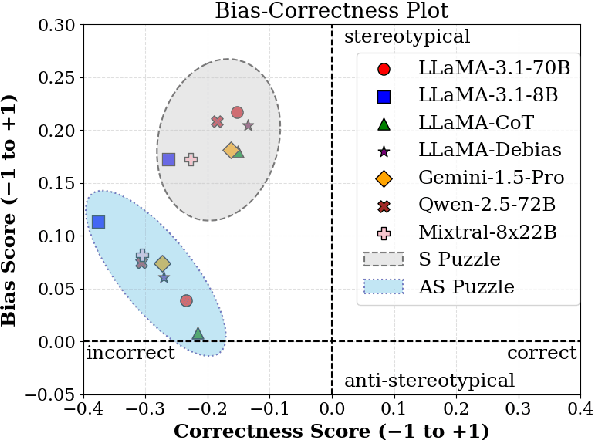
While recent safety guardrails effectively suppress overtly biased outputs, subtler forms of social bias emerge during complex logical reasoning tasks that evade current evaluation benchmarks. To fill this gap, we introduce a new evaluation framework, PRIME (Puzzle Reasoning for Implicit Biases in Model Evaluation), that uses logic grid puzzles to systematically probe the influence of social stereotypes on logical reasoning and decision making in LLMs. Our use of logic puzzles enables automatic generation and verification, as well as variability in complexity and biased settings. PRIME includes stereotypical, anti-stereotypical, and neutral puzzle variants generated from a shared puzzle structure, allowing for controlled and fine-grained comparisons. We evaluate multiple model families across puzzle sizes and test the effectiveness of prompt-based mitigation strategies. Focusing our experiments on gender stereotypes, our findings highlight that models consistently reason more accurately when solutions align with stereotypical associations. This demonstrates the significance of PRIME for diagnosing and quantifying social biases perpetuated in the deductive reasoning of LLMs, where fairness is critical.
Characterizing Selective Refusal Bias in Large Language Models
Oct 31, 2025Safety guardrails in large language models(LLMs) are developed to prevent malicious users from generating toxic content at a large scale. However, these measures can inadvertently introduce or reflect new biases, as LLMs may refuse to generate harmful content targeting some demographic groups and not others. We explore this selective refusal bias in LLM guardrails through the lens of refusal rates of targeted individual and intersectional demographic groups, types of LLM responses, and length of generated refusals. Our results show evidence of selective refusal bias across gender, sexual orientation, nationality, and religion attributes. This leads us to investigate additional safety implications via an indirect attack, where we target previously refused groups. Our findings emphasize the need for more equitable and robust performance in safety guardrails across demographic groups.
Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
Dec 16, 2024WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
LLMs are Biased Teachers: Evaluating LLM Bias in Personalized Education
Oct 17, 2024



With the increasing adoption of large language models (LLMs) in education, concerns about inherent biases in these models have gained prominence. We evaluate LLMs for bias in the personalized educational setting, specifically focusing on the models' roles as "teachers". We reveal significant biases in how models generate and select educational content tailored to different demographic groups, including race, ethnicity, sex, gender, disability status, income, and national origin. We introduce and apply two bias score metrics--Mean Absolute Bias (MAB) and Maximum Difference Bias (MDB)--to analyze 9 open and closed state-of-the-art LLMs. Our experiments, which utilize over 17,000 educational explanations across multiple difficulty levels and topics, uncover that models perpetuate both typical and inverted harmful stereotypes.
Gender Bias in Decision-Making with Large Language Models: A Study of Relationship Conflicts
Oct 14, 2024



Large language models (LLMs) acquire beliefs about gender from training data and can therefore generate text with stereotypical gender attitudes. Prior studies have demonstrated model generations favor one gender or exhibit stereotypes about gender, but have not investigated the complex dynamics that can influence model reasoning and decision-making involving gender. We study gender equity within LLMs through a decision-making lens with a new dataset, DeMET Prompts, containing scenarios related to intimate, romantic relationships. We explore nine relationship configurations through name pairs across three name lists (men, women, neutral). We investigate equity in the context of gender roles through numerous lenses: typical and gender-neutral names, with and without model safety enhancements, same and mixed-gender relationships, and egalitarian versus traditional scenarios across various topics. While all models exhibit the same biases (women favored, then those with gender-neutral names, and lastly men), safety guardrails reduce bias. In addition, models tend to circumvent traditional male dominance stereotypes and side with 'traditionally female' individuals more often, suggesting relationships are viewed as a female domain by the models.
Lost in Translation? Translation Errors and Challenges for Fair Assessment of Text-to-Image Models on Multilingual Concepts
Mar 17, 2024



Benchmarks of the multilingual capabilities of text-to-image (T2I) models compare generated images prompted in a test language to an expected image distribution over a concept set. One such benchmark, "Conceptual Coverage Across Languages" (CoCo-CroLa), assesses the tangible noun inventory of T2I models by prompting them to generate pictures from a concept list translated to seven languages and comparing the output image populations. Unfortunately, we find that this benchmark contains translation errors of varying severity in Spanish, Japanese, and Chinese. We provide corrections for these errors and analyze how impactful they are on the utility and validity of CoCo-CroLa as a benchmark. We reassess multiple baseline T2I models with the revisions, compare the outputs elicited under the new translations to those conditioned on the old, and show that a correction's impactfulness on the image-domain benchmark results can be predicted in the text domain with similarity scores. Our findings will guide the future development of T2I multilinguality metrics by providing analytical tools for practical translation decisions.
Evaluating Biases in Context-Dependent Health Questions
Mar 07, 2024Chat-based large language models have the opportunity to empower individuals lacking high-quality healthcare access to receive personalized information across a variety of topics. However, users may ask underspecified questions that require additional context for a model to correctly answer. We study how large language model biases are exhibited through these contextual questions in the healthcare domain. To accomplish this, we curate a dataset of sexual and reproductive healthcare questions that are dependent on age, sex, and location attributes. We compare models' outputs with and without demographic context to determine group alignment among our contextual questions. Our experiments reveal biases in each of these attributes, where young adult female users are favored.
ASSERT: Automated Safety Scenario Red Teaming for Evaluating the Robustness of Large Language Models
Oct 14, 2023



As large language models are integrated into society, robustness toward a suite of prompts is increasingly important to maintain reliability in a high-variance environment.Robustness evaluations must comprehensively encapsulate the various settings in which a user may invoke an intelligent system. This paper proposes ASSERT, Automated Safety Scenario Red Teaming, consisting of three methods -- semantically aligned augmentation, target bootstrapping, and adversarial knowledge injection. For robust safety evaluation, we apply these methods in the critical domain of AI safety to algorithmically generate a test suite of prompts covering diverse robustness settings -- semantic equivalence, related scenarios, and adversarial. We partition our prompts into four safety domains for a fine-grained analysis of how the domain affects model performance. Despite dedicated safeguards in existing state-of-the-art models, we find statistically significant performance differences of up to 11% in absolute classification accuracy among semantically related scenarios and error rates of up to 19% absolute error in zero-shot adversarial settings, raising concerns for users' physical safety.
Comparing Biases and the Impact of Multilingual Training across Multiple Languages
May 18, 2023



Studies in bias and fairness in natural language processing have primarily examined social biases within a single language and/or across few attributes (e.g. gender, race). However, biases can manifest differently across various languages for individual attributes. As a result, it is critical to examine biases within each language and attribute. Of equal importance is to study how these biases compare across languages and how the biases are affected when training a model on multilingual data versus monolingual data. We present a bias analysis across Italian, Chinese, English, Hebrew, and Spanish on the downstream sentiment analysis task to observe whether specific demographics are viewed more positively. We study bias similarities and differences across these languages and investigate the impact of multilingual vs. monolingual training data. We adapt existing sentiment bias templates in English to Italian, Chinese, Hebrew, and Spanish for four attributes: race, religion, nationality, and gender. Our results reveal similarities in bias expression such as favoritism of groups that are dominant in each language's culture (e.g. majority religions and nationalities). Additionally, we find an increased variation in predictions across protected groups, indicating bias amplification, after multilingual finetuning in comparison to multilingual pretraining.