 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Evaluators: Are readability metrics good measures of readability?
Aug 26, 2025Plain Language Summarization (PLS) aims to distill complex documents into accessible summaries for non-expert audiences. In this paper, we conduct a thorough survey of PLS literature, and identify that the current standard practice for readability evaluation is to use traditional readability metrics, such as Flesch-Kincaid Grade Level (FKGL). However, despite proven utility in other fields, these metrics have not been compared to human readability judgments in PLS. We evaluate 8 readability metrics and show that most correlate poorly with human judgments, including the most popular metric, FKGL. We then show that Language Models (LMs) are better judges of readability, with the best-performing model achieving a Pearson correlation of 0.56 with human judgments. Extending our analysis to PLS datasets, which contain summaries aimed at non-expert audiences, we find that LMs better capture deeper measures of readability, such as required background knowledge, and lead to different conclusions than the traditional metrics. Based on these findings, we offer recommendations for best practices in the evaluation of plain language summaries. We release our analysis code and survey data.
Making FETCH! Happen: Finding Emergent Dog Whistles Through Common Habitats
Dec 16, 2024WARNING: This paper contains content that maybe upsetting or offensive to some readers. Dog whistles are coded expressions with dual meanings: one intended for the general public (outgroup) and another that conveys a specific message to an intended audience (ingroup). Often, these expressions are used to convey controversial political opinions while maintaining plausible deniability and slip by content moderation filters. Identification of dog whistles relies on curated lexicons, which have trouble keeping up to date. We introduce \textbf{FETCH!}, a task for finding novel dog whistles in massive social media corpora. We find that state-of-the-art systems fail to achieve meaningful results across three distinct social media case studies. We present \textbf{EarShot}, a novel system that combines the strengths of vector databases and Large Language Models (LLMs) to efficiently and effectively identify new dog whistles.
Knowledge-Centric Templatic Views of Documents
Jan 13, 2024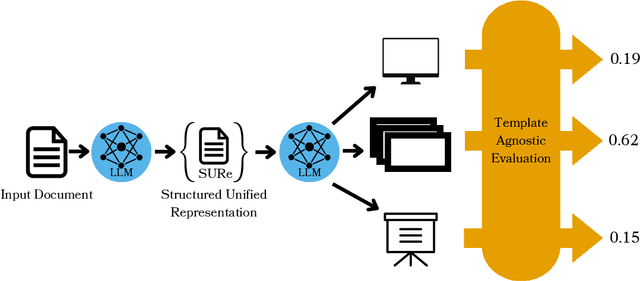

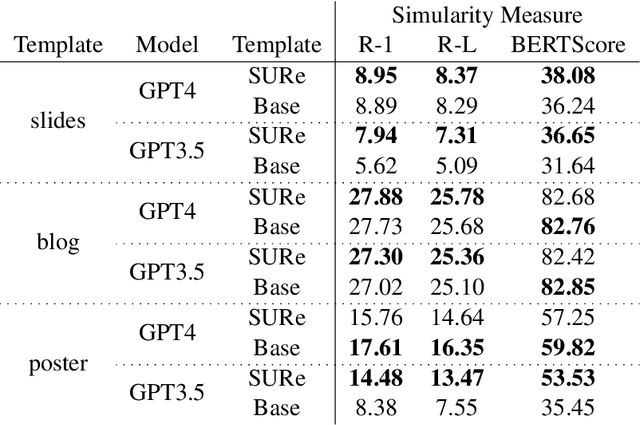
Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.
Selecting Shots for Demographic Fairness in Few-Shot Learning with Large Language Models
Nov 14, 2023Recently, work in NLP has shifted to few-shot (in-context) learning, with large language models (LLMs) performing well across a range of tasks. However, while fairness evaluations have become a standard for supervised methods, little is known about the fairness of LLMs as prediction systems. Further, common standard methods for fairness involve access to models weights or are applied during finetuning, which are not applicable in few-shot learning. Do LLMs exhibit prediction biases when used for standard NLP tasks? In this work, we explore the effect of shots, which directly affect the performance of models, on the fairness of LLMs as NLP classification systems. We consider how different shot selection strategies, both existing and new demographically sensitive methods, affect model fairness across three standard fairness datasets. We discuss how future work can include LLM fairness evaluations.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Faithful and Plausible Explanations of Medical Code Predictions
Apr 16, 2021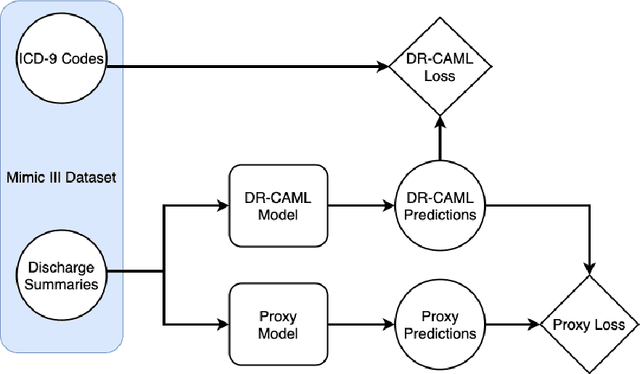

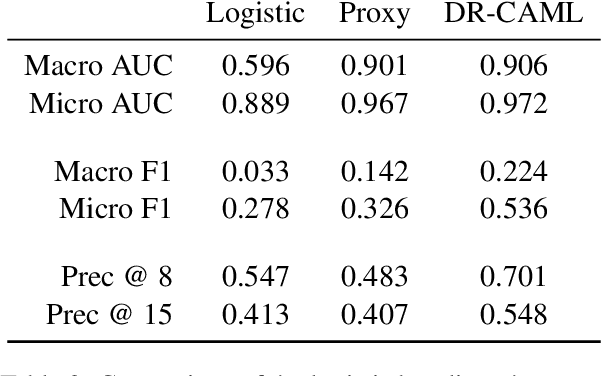
Machine learning models that offer excellent predictive performance often lack the interpretability necessary to support integrated human machine decision-making. In clinical medicine and other high-risk settings, domain experts may be unwilling to trust model predictions without explanations. Work in explainable AI must balance competing objectives along two different axes: 1) Explanations must balance faithfulness to the model's decision-making with their plausibility to a domain expert. 2) Domain experts desire local explanations of individual predictions and global explanations of behavior in aggregate. We propose to train a proxy model that mimics the behavior of the trained model and provides fine-grained control over these trade-offs. We evaluate our approach on the task of assigning ICD codes to clinical notes to demonstrate that explanations from the proxy model are faithful and replicate the trained model behavior.
TLDR: Extreme Summarization of Scientific Documents
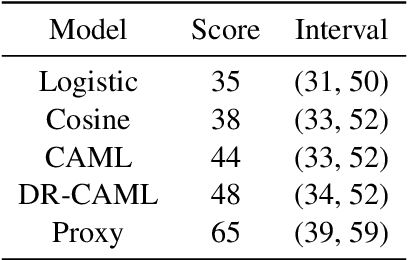
May 02, 2020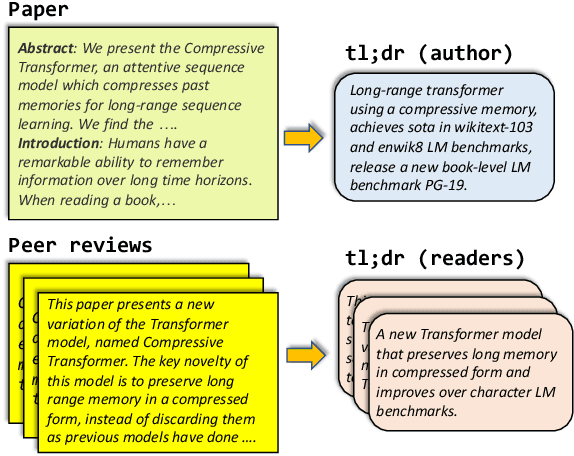


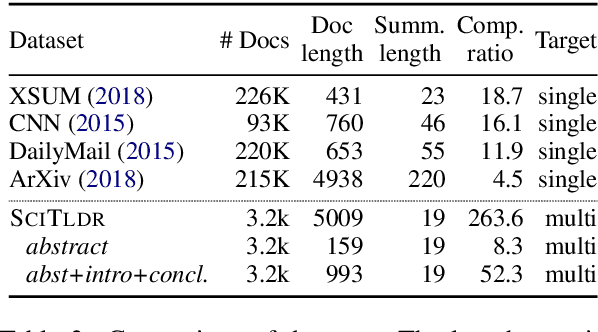
We introduce TLDR generation for scientific papers, a new automatic summarization task with high source compression, requiring expert background knowledge and complex language understanding. To facilitate research on this task, we introduce SciTLDR, a dataset of 3.9K TLDRs. Furthermore, we introduce a novel annotation protocol for scalably curating additional gold summaries by rewriting peer review comments. We use this protocol to augment our test set, yielding multiple gold TLDRs for evaluation, which is unlike most recent summarization datasets that assume only one valid gold summary. We present a training strategy for adapting pretrained language models that exploits similarities between TLDR generation and the related task of title generation, which outperforms strong extractive and abstractive summarization baselines.
Citation Text Generation
Feb 02, 2020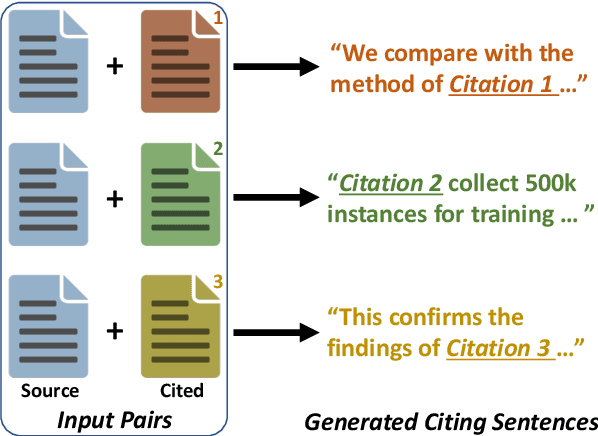
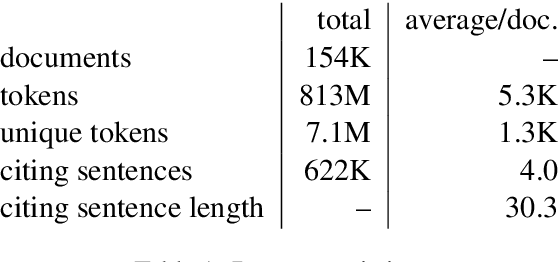
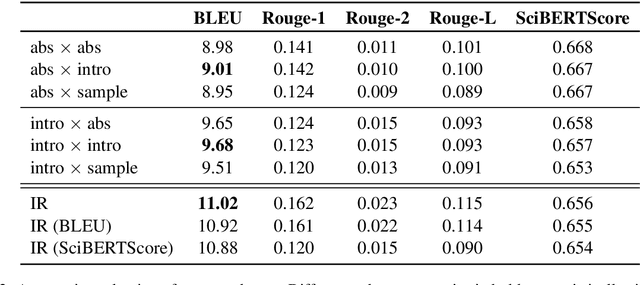
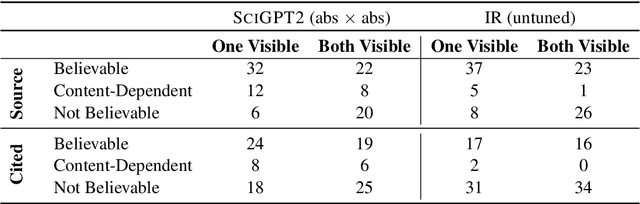
We introduce the task of citation text generation: given a pair of scientific documents, explain their relationship in natural language text in the manner of a citation from one text to the other. This task encourages systems to learn rich relationships between scientific texts and to express them concretely in natural language. Models for citation text generation will require robust document understanding including the capacity to quickly adapt to new vocabulary and to reason about document content. We believe this challenging direction of research will benefit high-impact applications such as automatic literature review or scientific writing assistance systems. In this paper we establish the task of citation text generation with a standard evaluation corpus and explore several baseline models.