 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
Apr 13, 2026Frontier coding agents solve complex tasks when given complete context but collapse when specifications are incomplete or ambiguous. The bottleneck is not raw capability, but judgment: knowing when to act autonomously and when to ask for help. Current benchmarks are blind to this failure mode. They supply unambiguous detailed instructions and solely reward execution correctness, so an agent that makes a lucky guess for a missing requirement will score identically to one that would have asked to be certain. We present HiL-Bench (Human-in-the-Loop Benchmark) to measure this selective escalation skill. Each task contains human-validated blockers (missing information, ambiguous requests, contradictory information) that surface only through progressive exploration, not upfront inspection. Our core metric, Ask-F1, the harmonic mean of question precision and blocker recall, captures the tension between over-asking and silent guessing; its structure architecturally prevents gaming through question spam. Evaluation across SWE and text-to-SQL domains reveals a large universal judgment gap: no frontier model recovers more than a fraction of its full-information performance when deciding whether to ask. Failure analysis identifies three key help-seeking patterns: overconfident wrong beliefs with no gap detection; high uncertainty detection yet persistent errors; broad, imprecise escalation without self-correction. These consistent patterns confirm poor help-seeking is a model-level flaw, not task-specific. RL training on shaped Ask-F1 reward shows judgment is trainable: a 32B model improves both help-seeking quality and task pass rate, with gains that transfer across domains. The model does not learn domain-specific heuristics for when to ask; it learns to detect unresolvable uncertainty and act on it.
Time Waits for No One! Analysis and Challenges of Temporal Misalignment
Nov 14, 2021
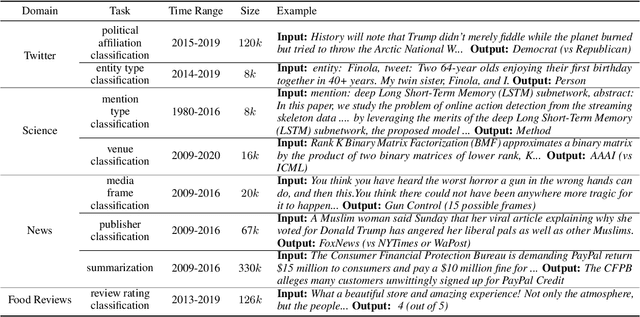
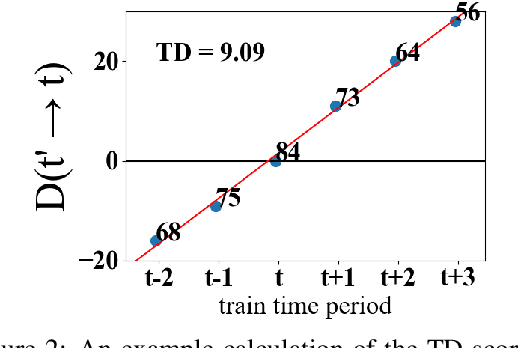
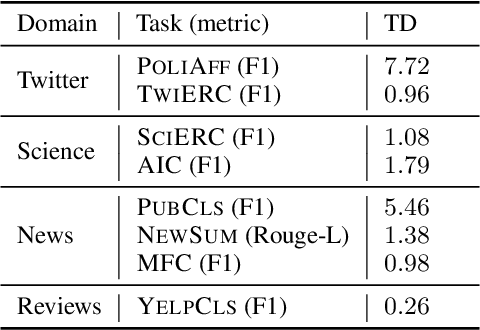
When an NLP model is trained on text data from one time period and tested or deployed on data from another, the resulting temporal misalignment can degrade end-task performance. In this work, we establish a suite of eight diverse tasks across different domains (social media, science papers, news, and reviews) and periods of time (spanning five years or more) to quantify the effects of temporal misalignment. Our study is focused on the ubiquitous setting where a pretrained model is optionally adapted through continued domain-specific pretraining, followed by task-specific finetuning. We establish a suite of tasks across multiple domains to study temporal misalignment in modern NLP systems. We find stronger effects of temporal misalignment on task performance than have been previously reported. We also find that, while temporal adaptation through continued pretraining can help, these gains are small compared to task-specific finetuning on data from the target time period. Our findings motivate continued research to improve temporal robustness of NLP models.
Citation Text Generation
Feb 02, 2020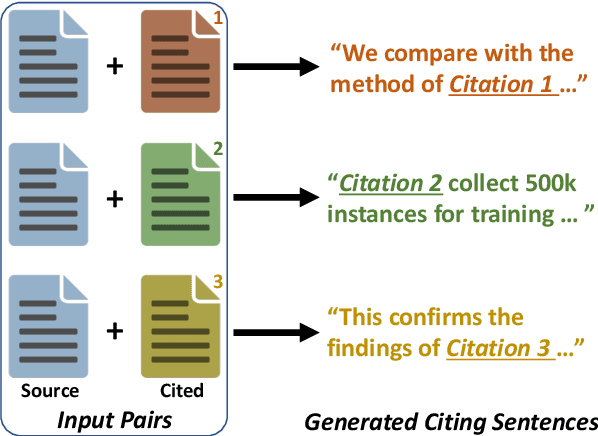
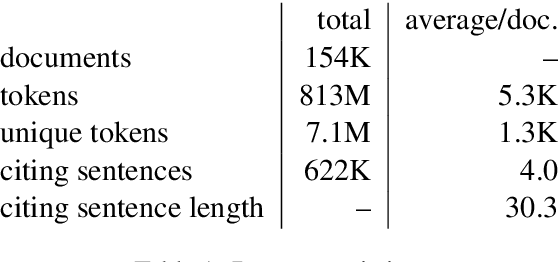
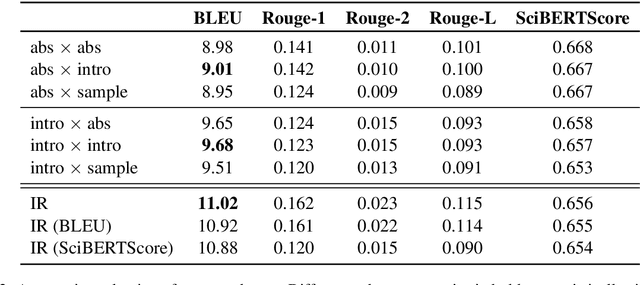
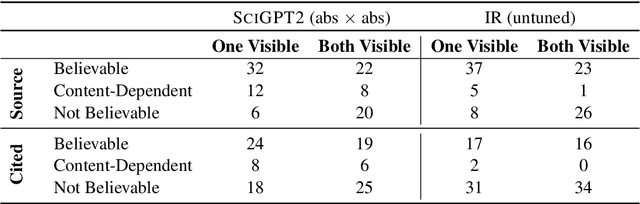
We introduce the task of citation text generation: given a pair of scientific documents, explain their relationship in natural language text in the manner of a citation from one text to the other. This task encourages systems to learn rich relationships between scientific texts and to express them concretely in natural language. Models for citation text generation will require robust document understanding including the capacity to quickly adapt to new vocabulary and to reason about document content. We believe this challenging direction of research will benefit high-impact applications such as automatic literature review or scientific writing assistance systems. In this paper we establish the task of citation text generation with a standard evaluation corpus and explore several baseline models.