 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeon: News Entity-Interaction Extraction for Enhanced Question Answering
Nov 20, 2024



Capturing fresh information in near real-time and using it to augment existing large language models (LLMs) is essential to generate up-to-date, grounded, and reliable output. This problem becomes particularly challenging when LLMs are used for informational tasks in rapidly evolving fields, such as Web search related to recent or unfolding events involving entities, where generating temporally relevant responses requires access to up-to-the-hour news sources. However, the information modeled by the parametric memory of LLMs is often outdated, and Web results from prototypical retrieval systems may fail to capture the latest relevant information and struggle to handle conflicting reports in evolving news. To address this challenge, we present the NEON framework, designed to extract emerging entity interactions -- such as events or activities -- as described in news articles. NEON constructs an entity-centric timestamped knowledge graph that captures such interactions, thereby facilitating enhanced QA capabilities related to news events. Our framework innovates by integrating open Information Extraction (openIE) style tuples into LLMs to enable in-context retrieval-augmented generation. This integration demonstrates substantial improvements in QA performance when tackling temporal, entity-centric search queries. Through NEON, LLMs can deliver more accurate, reliable, and up-to-date responses.
Knowledge-Centric Templatic Views of Documents
Jan 13, 2024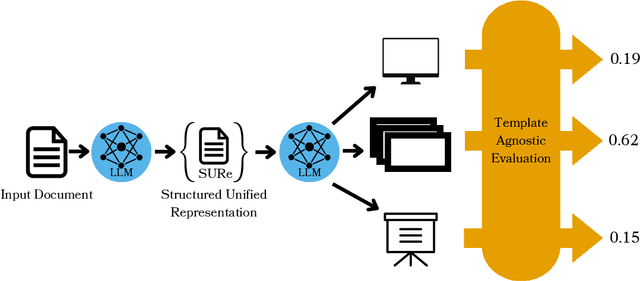

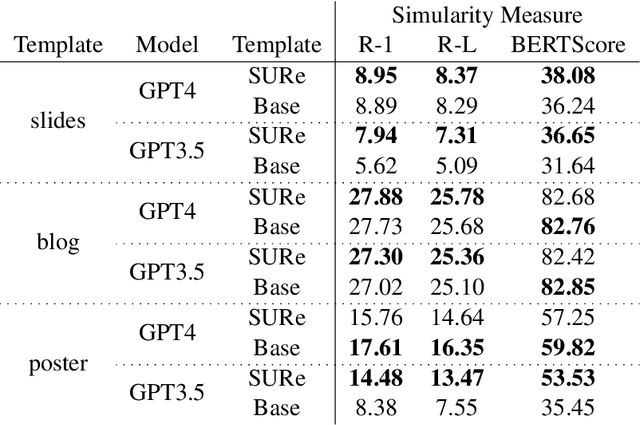
Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.