 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Centric Templatic Views of Documents
Jan 13, 2024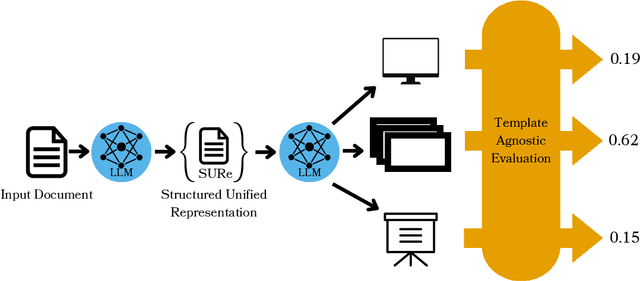

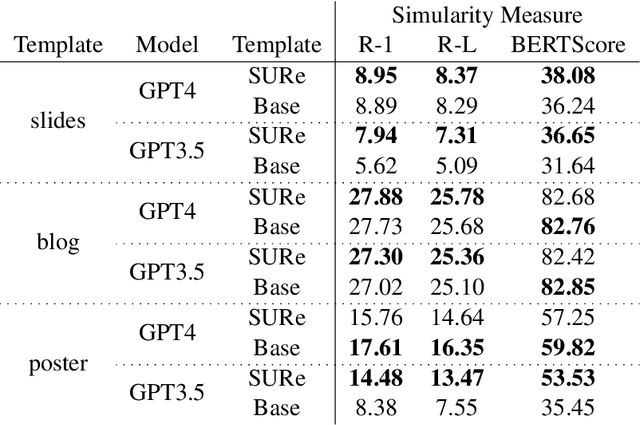
Authors seeking to communicate with broader audiences often compose their ideas about the same underlying knowledge in different documents and formats -- for example, as slide decks, newsletters, reports, brochures, etc. Prior work in document generation has generally considered the creation of each separate format to be different a task, developing independent methods for generation and evaluation. This approach is suboptimal for the advancement of AI-supported content authoring from both research and application perspectives because it leads to fragmented learning processes, redundancy in models and methods, and disjointed evaluation. Thus, in our work, we consider each of these documents to be templatic views of the same underlying knowledge, and we aim to unify the generation and evaluation of these templatic views of documents. We begin by introducing an LLM-powered method to extract the most important information from an input document and represent this information in a structured format. We show that this unified representation can be used to generate multiple templatic views with no supervision and with very little guidance, improving over strong baselines. We additionally introduce a unified evaluation method that is template agnostic, and can be adapted to building document generators for heterogeneous downstream applications. Finally, we conduct a human evaluation, which shows that humans prefer 82% of the downstream documents generated with our method. Furthermore, the newly proposed evaluation metric correlates more highly with human judgement than prior metrics, while providing a unified evaluation method.
UniLayout: Taming Unified Sequence-to-Sequence Transformers for Graphic Layout Generation
Aug 17, 2022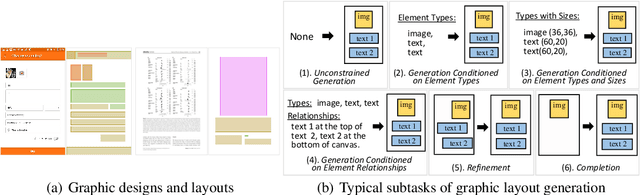

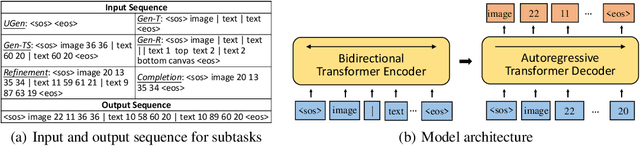
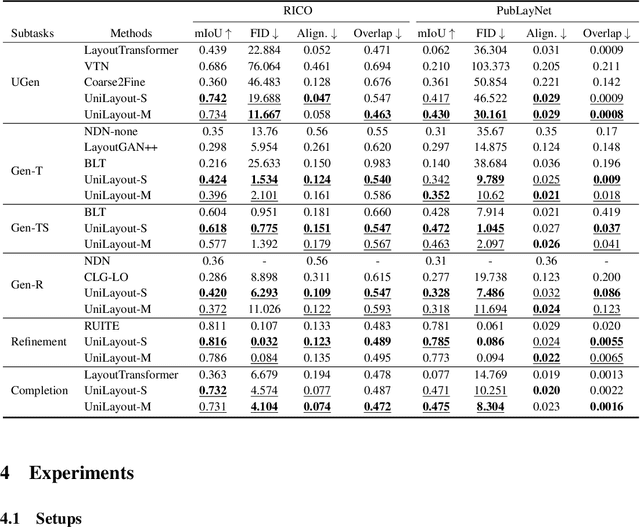
To satisfy various user needs, different subtasks of graphic layout generation have been explored intensively in recent years. Existing studies usually propose task-specific methods with diverse input-output formats, dedicated model architectures, and different learning methods. However, those specialized approaches make the adaption to unseen subtasks difficult, hinder the knowledge sharing between different subtasks, and are contrary to the trend of devising general-purpose models. In this work, we propose UniLayout, which handles different subtasks for graphic layout generation in a unified manner. First, we uniformly represent diverse inputs and outputs of subtasks as the sequences of tokens. Then, based on the unified sequence format, we naturally leverage an identical encoder-decoder architecture with Transformers for different subtasks. Moreover, based on the above two kinds of unification, we further develop a single model that supports all subtasks concurrently. Experiments on two public datasets demonstrate that while simple, UniLayout significantly outperforms the previous task-specific methods.