 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLayout: Taming Unified Sequence-to-Sequence Transformers for Graphic Layout Generation
Paper and Code
Aug 17, 2022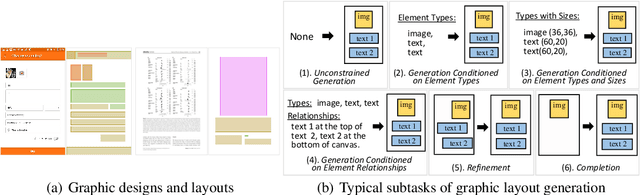

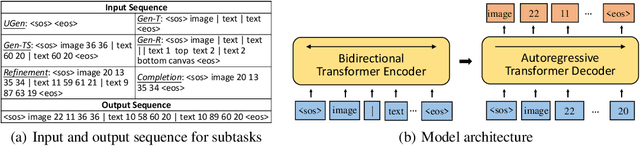
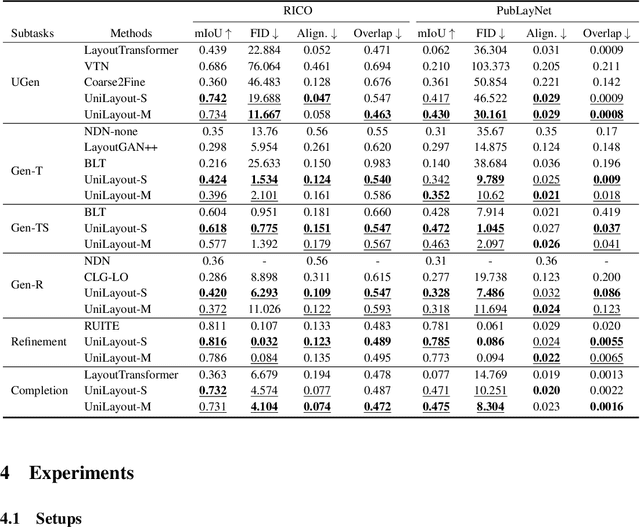
To satisfy various user needs, different subtasks of graphic layout generation have been explored intensively in recent years. Existing studies usually propose task-specific methods with diverse input-output formats, dedicated model architectures, and different learning methods. However, those specialized approaches make the adaption to unseen subtasks difficult, hinder the knowledge sharing between different subtasks, and are contrary to the trend of devising general-purpose models. In this work, we propose UniLayout, which handles different subtasks for graphic layout generation in a unified manner. First, we uniformly represent diverse inputs and outputs of subtasks as the sequences of tokens. Then, based on the unified sequence format, we naturally leverage an identical encoder-decoder architecture with Transformers for different subtasks. Moreover, based on the above two kinds of unification, we further develop a single model that supports all subtasks concurrently. Experiments on two public datasets demonstrate that while simple, UniLayout significantly outperforms the previous task-specific methods.