 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO2: The Desktop AgentOS
Apr 20, 2025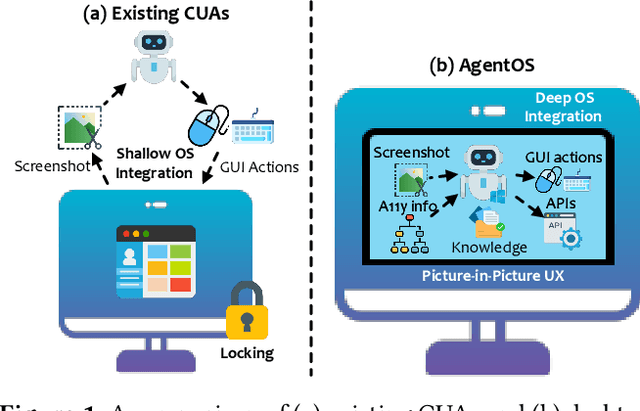
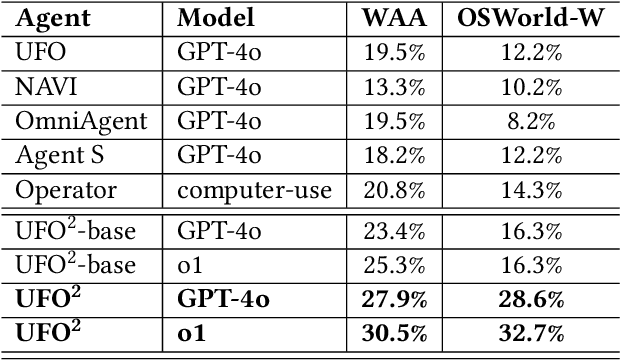
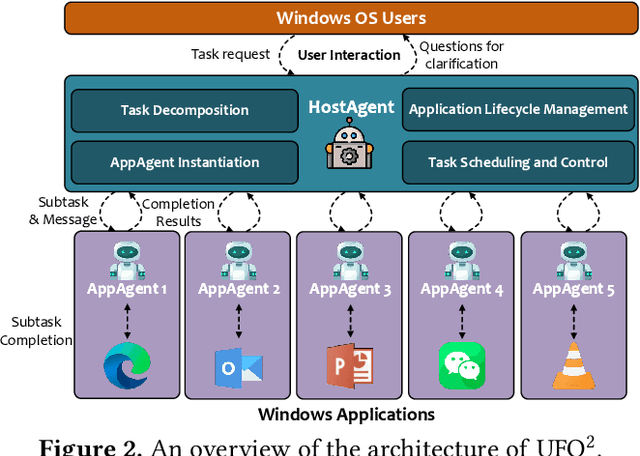
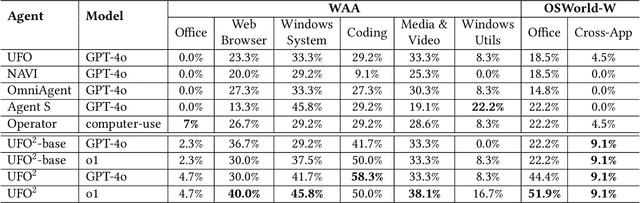
Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
Dehallucinating Parallel Context Extension for Retrieval-Augmented Generation
Dec 19, 2024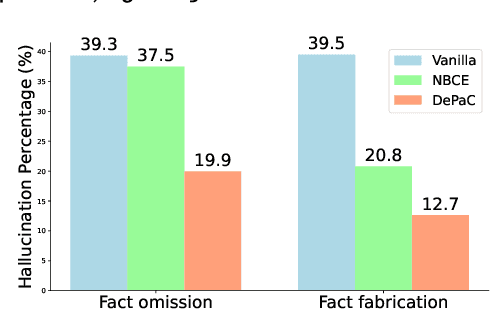
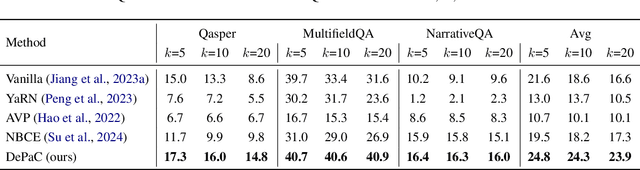

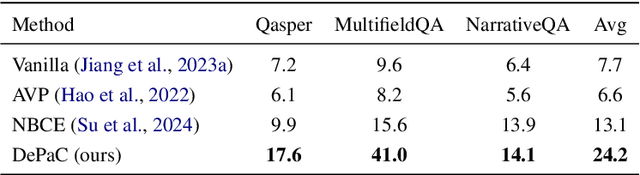
Large language models (LLMs) are susceptible to generating hallucinated information, despite the integration of retrieval-augmented generation (RAG). Parallel context extension (PCE) is a line of research attempting to effectively integrating parallel (unordered) contexts, while it still suffers from hallucinations when adapted to RAG scenarios. In this paper, we propose DePaC (Dehallucinating Parallel Context Extension), which alleviates the hallucination problem with context-aware negative training and information-calibrated aggregation. DePaC is designed to alleviate two types of in-context hallucination: fact fabrication (i.e., LLMs present claims that are not supported by the contexts) and fact omission (i.e., LLMs fail to present claims that can be supported by the contexts). Specifically, (1) for fact fabrication, we apply the context-aware negative training that fine-tunes the LLMs with negative supervisions, thus explicitly guiding the LLMs to refuse to answer when contexts are not related to questions; (2) for fact omission, we propose the information-calibrated aggregation which prioritizes context windows with higher information increment from their contexts. The experimental results on nine RAG tasks demonstrate that DePaC significantly alleviates the two types of hallucination and consistently achieves better performances on these tasks.
Large Action Models: From Inception to Implementation
Dec 13, 2024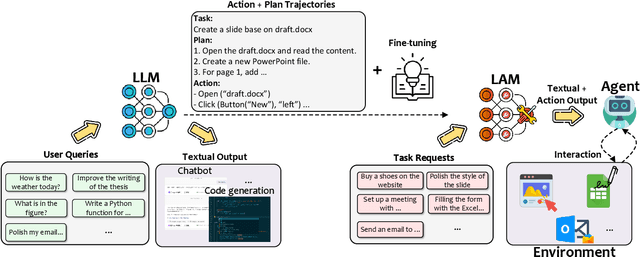

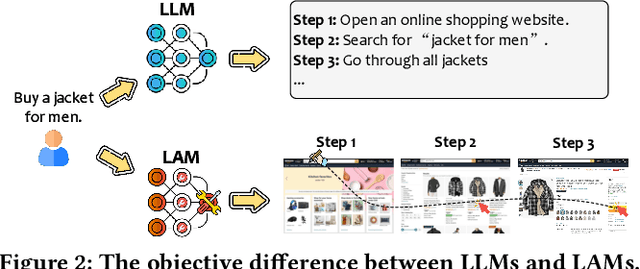

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions. This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments. Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence. In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment. We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation. This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications. The code for the data collection process utilized in this paper is publicly available at: https://github.com/microsoft/UFO/tree/main/dataflow, and comprehensive documentation can be found at https://microsoft.github.io/UFO/dataflow/overview/.
StraGo: Harnessing Strategic Guidance for Prompt Optimization
Oct 11, 2024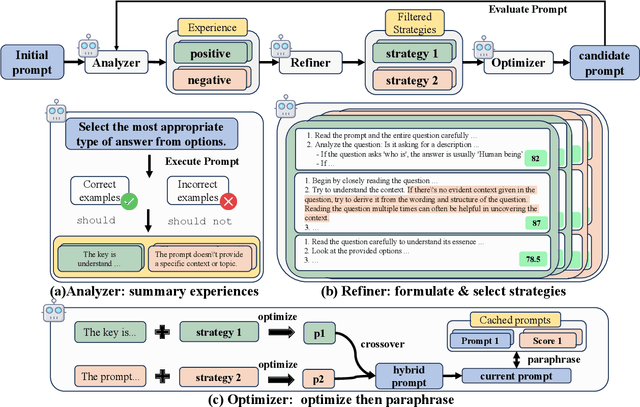
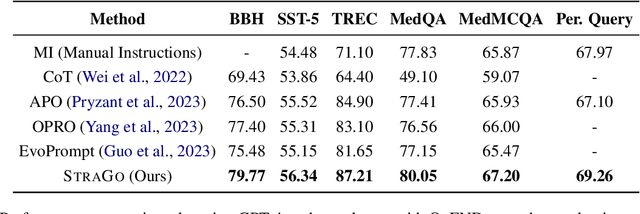
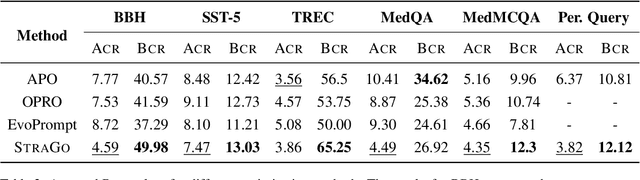
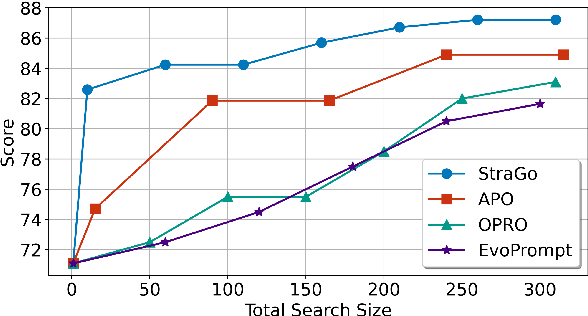
Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.
AMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024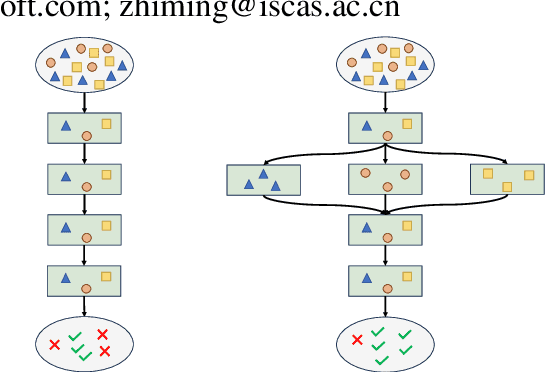
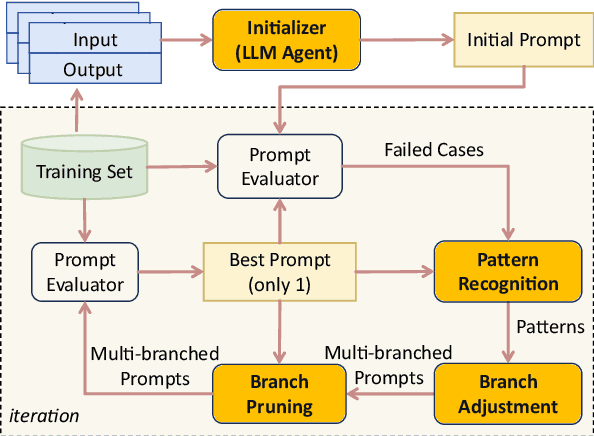
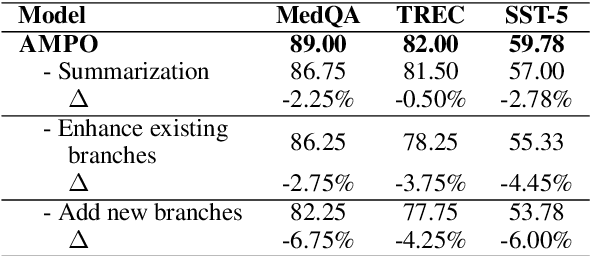
Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
Automatic Instruction Evolving for Large Language Models
Jun 02, 2024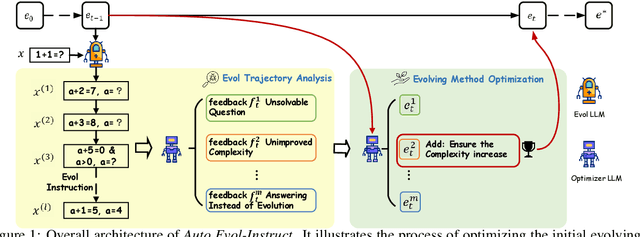
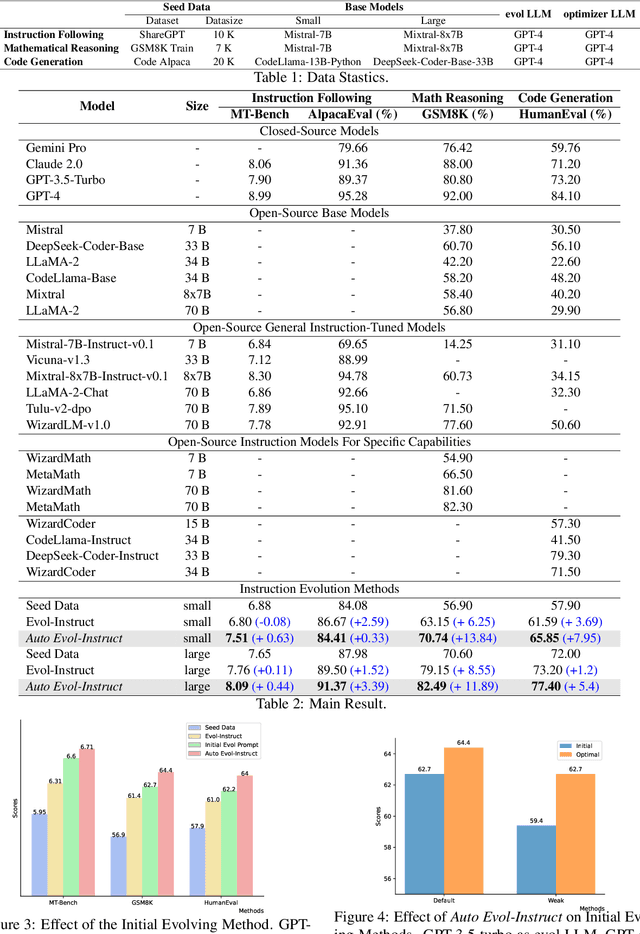
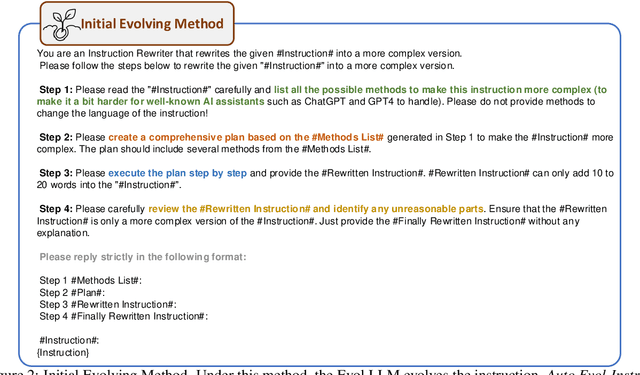

Fine-tuning large pre-trained language models with Evol-Instruct has achieved encouraging results across a wide range of tasks. However, designing effective evolving methods for instruction evolution requires substantial human expertise. This paper proposes Auto Evol-Instruct, an end-to-end framework that evolves instruction datasets using large language models without any human effort. The framework automatically analyzes and summarizes suitable evolutionary strategies for the given instruction data and iteratively improves the evolving method based on issues exposed during the instruction evolution process. Our extensive experiments demonstrate that the best method optimized by Auto Evol-Instruct outperforms human-designed methods on various benchmarks, including MT-Bench, AlpacaEval, GSM8K, and HumanEval.
Make Your LLM Fully Utilize the Context
Apr 26, 2024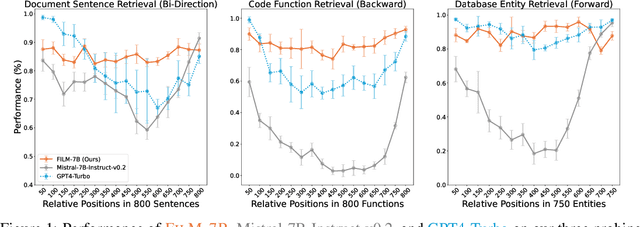
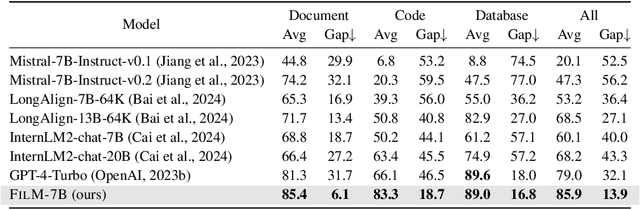
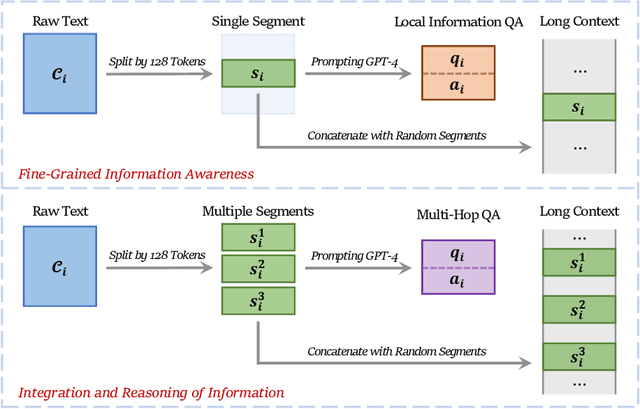
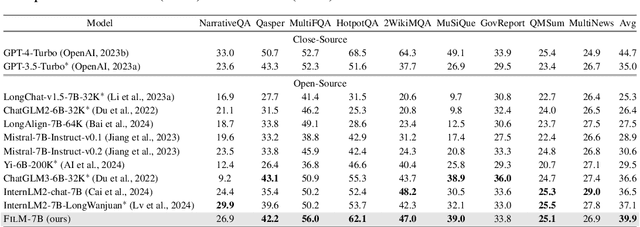
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024



Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.
Data Transformation to Construct a Dataset for Generating Entity-Relationship Model from Natural Language
Dec 21, 2023In order to reduce the manual cost of designing ER models, recent approaches have been proposed to address the task of NL2ERM, i.e., automatically generating entity-relationship (ER) models from natural language (NL) utterances such as software requirements. These approaches are typically rule-based ones, which rely on rigid heuristic rules; these approaches cannot generalize well to various linguistic ways of describing the same requirement. Despite having better generalization capability than rule-based approaches, deep-learning-based models are lacking for NL2ERM due to lacking a large-scale dataset. To address this issue, in this paper, we report our insight that there exists a high similarity between the task of NL2ERM and the increasingly popular task of text-to-SQL, and propose a data transformation algorithm that transforms the existing data of text-to-SQL into the data of NL2ERM. We apply our data transformation algorithm on Spider, one of the most popular text-to-SQL datasets, and we also collect some data entries with different NL types, to obtain a large-scale NL2ERM dataset. Because NL2ERM can be seen as a special information extraction (IE) task, we train two state-of-the-art IE models on our dataset. The experimental results show that both the two models achieve high performance and outperform existing baselines.
Thread of Thought Unraveling Chaotic Contexts
Nov 15, 2023



Large Language Models (LLMs) have ushered in a transformative era in the field of natural language processing, excelling in tasks related to text comprehension and generation. Nevertheless, they encounter difficulties when confronted with chaotic contexts (e.g., distractors rather than long irrelevant context), leading to the inadvertent omission of certain details within the chaotic context. In response to these challenges, we introduce the "Thread of Thought" (ThoT) strategy, which draws inspiration from human cognitive processes. ThoT systematically segments and analyzes extended contexts while adeptly selecting pertinent information. This strategy serves as a versatile "plug-and-play" module, seamlessly integrating with various LLMs and prompting techniques. In the experiments, we utilize the PopQA and EntityQ datasets, as well as a Multi-Turn Conversation Response dataset (MTCR) we collected, to illustrate that ThoT significantly improves reasoning performance compared to other prompting techniques.