 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgea1: Steep Test-time Scaling Law via Environment Augmented Generation
Apr 20, 2025Large Language Models (LLMs) have made remarkable breakthroughs in reasoning, yet continue to struggle with hallucinations, logical errors, and inability to self-correct during complex multi-step tasks. Current approaches like chain-of-thought prompting offer limited reasoning capabilities that fail when precise step validation is required. We propose Environment Augmented Generation (EAG), a framework that enhances LLM reasoning through: (1) real-time environmental feedback validating each reasoning step, (2) dynamic branch exploration for investigating alternative solution paths when faced with errors, and (3) experience-based learning from successful reasoning trajectories. Unlike existing methods, EAG enables deliberate backtracking and strategic replanning through tight integration of execution feedback with branching exploration. Our a1-32B model achieves state-of-the-art performance among similar-sized models across all benchmarks, matching larger models like o1 on competition mathematics while outperforming comparable models by up to 24.4 percentage points. Analysis reveals EAG's distinctive scaling pattern: initial token investment in environment interaction yields substantial long-term performance dividends, with advantages amplifying proportionally to task complexity. EAG's theoretical framework demonstrates how environment interactivity and systematic branch exploration together establish a new paradigm for reliable machine reasoning, particularly for problems requiring precise multi-step calculation and logical verification.
Vulnerability of Text-to-Image Models to Prompt Template Stealing: A Differential Evolution Approach
Feb 20, 2025Prompt trading has emerged as a significant intellectual property concern in recent years, where vendors entice users by showcasing sample images before selling prompt templates that can generate similar images. This work investigates a critical security vulnerability: attackers can steal prompt templates using only a limited number of sample images. To investigate this threat, we introduce Prism, a prompt-stealing benchmark consisting of 50 templates and 450 images, organized into Easy and Hard difficulty levels. To identify the vulnerabity of VLMs to prompt stealing, we propose EvoStealer, a novel template stealing method that operates without model fine-tuning by leveraging differential evolution algorithms. The system first initializes population sets using multimodal large language models (MLLMs) based on predefined patterns, then iteratively generates enhanced offspring through MLLMs. During evolution, EvoStealer identifies common features across offspring to derive generalized templates. Our comprehensive evaluation conducted across open-source (INTERNVL2-26B) and closed-source models (GPT-4o and GPT-4o-mini) demonstrates that EvoStealer's stolen templates can reproduce images highly similar to originals and effectively generalize to other subjects, significantly outperforming baseline methods with an average improvement of over 10%. Moreover, our cost analysis reveals that EvoStealer achieves template stealing with negligible computational expenses. Our code and dataset are available at https://github.com/whitepagewu/evostealer.
AMPO: Automatic Multi-Branched Prompt Optimization
Oct 11, 2024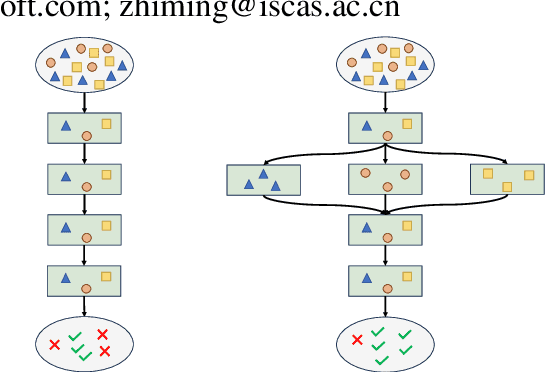
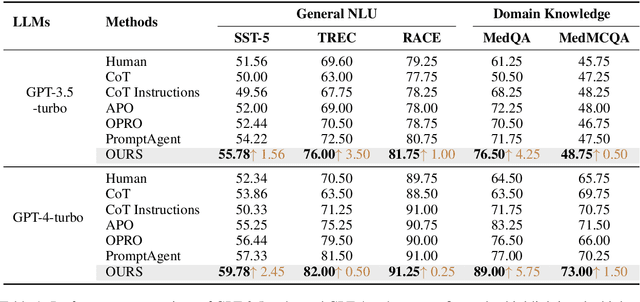
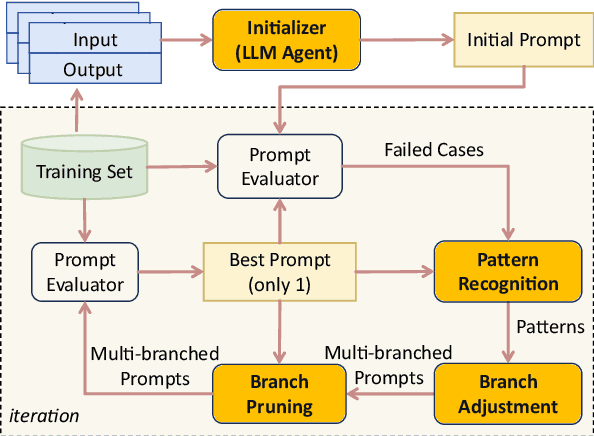
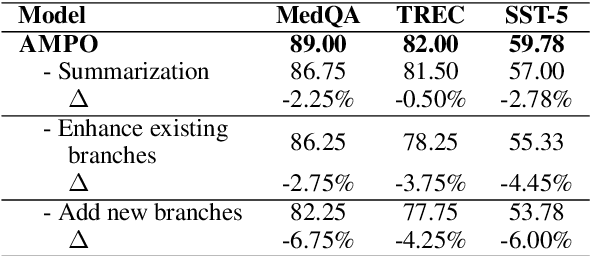
Prompt engineering is very important to enhance the performance of large language models (LLMs). When dealing with complex issues, prompt engineers tend to distill multiple patterns from examples and inject relevant solutions to optimize the prompts, achieving satisfying results. However, existing automatic prompt optimization techniques are only limited to producing single flow instructions, struggling with handling diverse patterns. In this paper, we present AMPO, an automatic prompt optimization method that can iteratively develop a multi-branched prompt using failure cases as feedback. Our goal is to explore a novel way of structuring prompts with multi-branches to better handle multiple patterns in complex tasks, for which we introduce three modules: Pattern Recognition, Branch Adjustment, and Branch Pruning. In experiments across five tasks, AMPO consistently achieves the best results. Additionally, our approach demonstrates significant optimization efficiency due to our adoption of a minimal search strategy.
StraGo: Harnessing Strategic Guidance for Prompt Optimization
Oct 11, 2024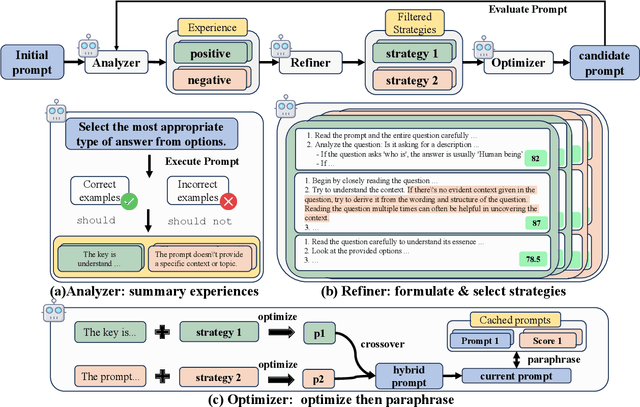
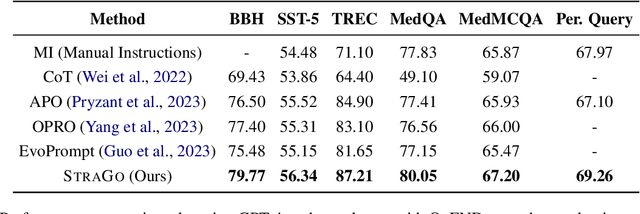
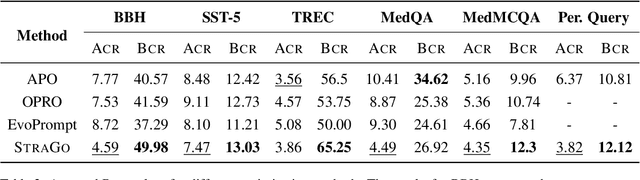
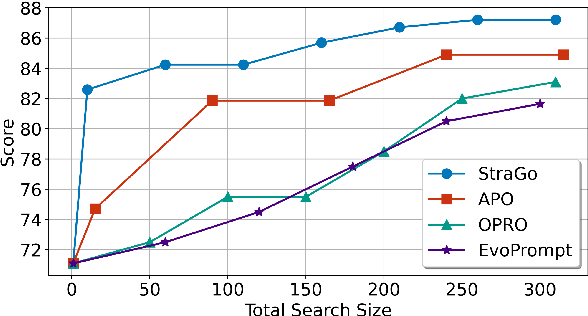
Prompt engineering is pivotal for harnessing the capabilities of large language models (LLMs) across diverse applications. While existing prompt optimization methods improve prompt effectiveness, they often lead to prompt drifting, where newly generated prompts can adversely impact previously successful cases while addressing failures. Furthermore, these methods tend to rely heavily on LLMs' intrinsic capabilities for prompt optimization tasks. In this paper, we introduce StraGo (Strategic-Guided Optimization), a novel approach designed to mitigate prompt drifting by leveraging insights from both successful and failed cases to identify critical factors for achieving optimization objectives. StraGo employs a how-to-do methodology, integrating in-context learning to formulate specific, actionable strategies that provide detailed, step-by-step guidance for prompt optimization. Extensive experiments conducted across a range of tasks, including reasoning, natural language understanding, domain-specific knowledge, and industrial applications, demonstrate StraGo's superior performance. It establishes a new state-of-the-art in prompt optimization, showcasing its ability to deliver stable and effective prompt improvements.
A Clustering Method with Graph Maximum Decoding Information
Mar 18, 2024The clustering method based on graph models has garnered increased attention for its widespread applicability across various knowledge domains. Its adaptability to integrate seamlessly with other relevant applications endows the graph model-based clustering analysis with the ability to robustly extract "natural associations" or "graph structures" within datasets, facilitating the modelling of relationships between data points. Despite its efficacy, the current clustering method utilizing the graph-based model overlooks the uncertainty associated with random walk access between nodes and the embedded structural information in the data. To address this gap, we present a novel Clustering method for Maximizing Decoding Information within graph-based models, named CMDI. CMDI innovatively incorporates two-dimensional structural information theory into the clustering process, consisting of two phases: graph structure extraction and graph vertex partitioning. Within CMDI, graph partitioning is reformulated as an abstract clustering problem, leveraging maximum decoding information to minimize uncertainty associated with random visits to vertices. Empirical evaluations on three real-world datasets demonstrate that CMDI outperforms classical baseline methods, exhibiting a superior decoding information ratio (DI-R). Furthermore, CMDI showcases heightened efficiency, particularly when considering prior knowledge (PK). These findings underscore the effectiveness of CMDI in enhancing decoding information quality and computational efficiency, positioning it as a valuable tool in graph-based clustering analyses.
A Multi-constraint and Multi-objective Allocation Model for Emergency Rescue in IoT Environment
Mar 15, 2024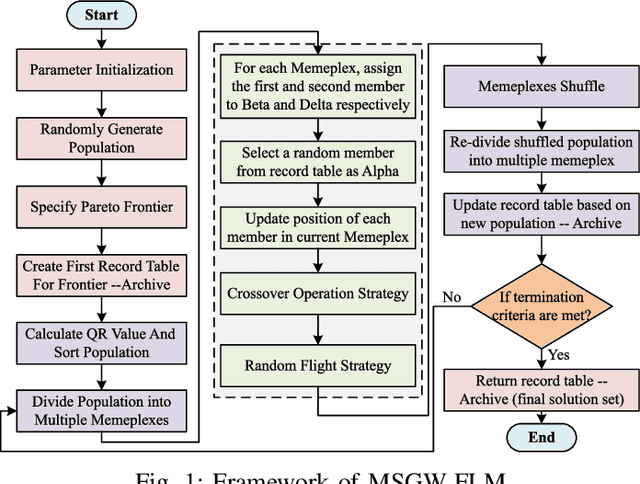
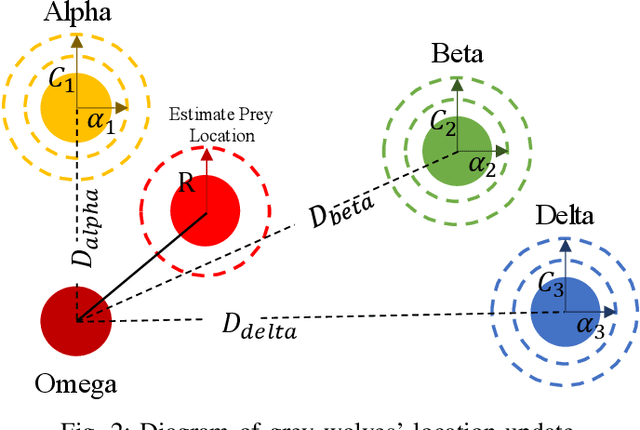
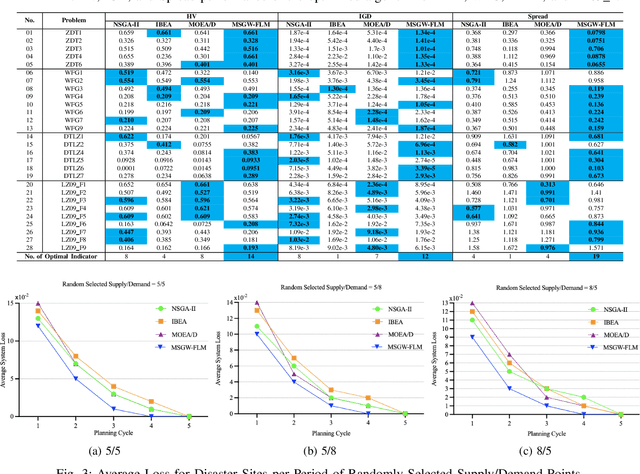
Emergency relief operations are essential in disaster aftermaths, necessitating effective resource allocation to minimize negative impacts and maximize benefits. In prolonged crises or extensive disasters, a systematic, multi-cycle approach is key for timely and informed decision-making. Leveraging advancements in IoT and spatio-temporal data analytics, we've developed the Multi-Objective Shuffled Gray-Wolf Frog Leaping Model (MSGW-FLM). This multi-constraint, multi-objective resource allocation model has been rigorously tested against 28 diverse challenges, showing superior performance in comparison to established models such as NSGA-II, IBEA, and MOEA/D. MSGW-FLM's effectiveness is particularly notable in complex, multi-cycle emergency rescue scenarios, which involve numerous constraints and objectives. This model represents a significant step forward in optimizing resource distribution in emergency response situations.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024



Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.