 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Pseudo-Label Generation Based on Visual Prompt Assisted Cloud Model Update
Apr 01, 2025Generating high-quality pseudo-labels on the cloud is crucial for cloud-edge object detection, especially in dynamic traffic monitoring where data distributions evolve. Existing methods often assume reliable cloud models, neglecting potential errors or struggling with complex distribution shifts. This paper proposes Cloud-Adaptive High-Quality Pseudo-label generation (CA-HQP), addressing these limitations by incorporating a learnable Visual Prompt Generator (VPG) and dual feature alignment into cloud model updates. The VPG enables parameter-efficient adaptation by injecting visual prompts, enhancing flexibility without extensive fine-tuning. CA-HQP mitigates domain discrepancies via two feature alignment techniques: global Domain Query Feature Alignment (DQFA) capturing scene-level shifts, and fine-grained Temporal Instance-Aware Feature Embedding Alignment (TIAFA) addressing instance variations. Experiments on the Bellevue traffic dataset demonstrate that CA-HQP significantly improves pseudo-label quality compared to existing methods, leading to notable performance gains for the edge model and showcasing CA-HQP's adaptation effectiveness. Ablation studies validate each component (DQFA, TIAFA, VPG) and the synergistic effect of combined alignment strategies, highlighting the importance of adaptive cloud updates and domain adaptation for robust object detection in evolving scenarios. CA-HQP provides a promising solution for enhancing cloud-edge object detection systems in real-world applications.
A Clustering Method with Graph Maximum Decoding Information
Mar 18, 2024The clustering method based on graph models has garnered increased attention for its widespread applicability across various knowledge domains. Its adaptability to integrate seamlessly with other relevant applications endows the graph model-based clustering analysis with the ability to robustly extract "natural associations" or "graph structures" within datasets, facilitating the modelling of relationships between data points. Despite its efficacy, the current clustering method utilizing the graph-based model overlooks the uncertainty associated with random walk access between nodes and the embedded structural information in the data. To address this gap, we present a novel Clustering method for Maximizing Decoding Information within graph-based models, named CMDI. CMDI innovatively incorporates two-dimensional structural information theory into the clustering process, consisting of two phases: graph structure extraction and graph vertex partitioning. Within CMDI, graph partitioning is reformulated as an abstract clustering problem, leveraging maximum decoding information to minimize uncertainty associated with random visits to vertices. Empirical evaluations on three real-world datasets demonstrate that CMDI outperforms classical baseline methods, exhibiting a superior decoding information ratio (DI-R). Furthermore, CMDI showcases heightened efficiency, particularly when considering prior knowledge (PK). These findings underscore the effectiveness of CMDI in enhancing decoding information quality and computational efficiency, positioning it as a valuable tool in graph-based clustering analyses.
A Multi-constraint and Multi-objective Allocation Model for Emergency Rescue in IoT Environment
Mar 15, 2024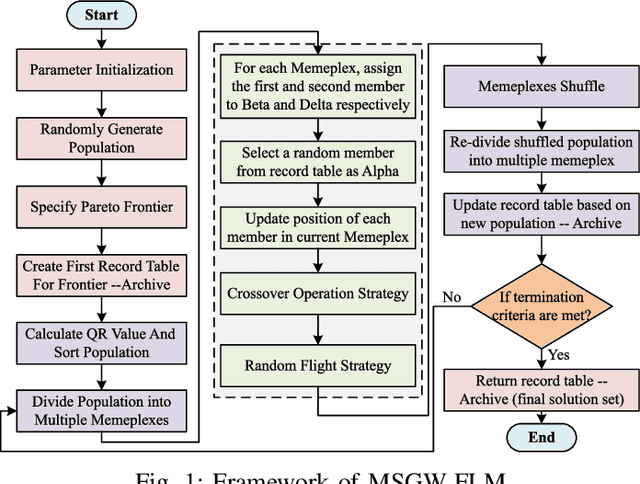
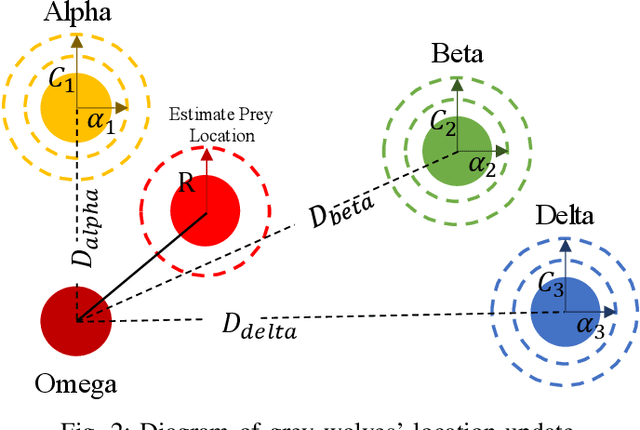
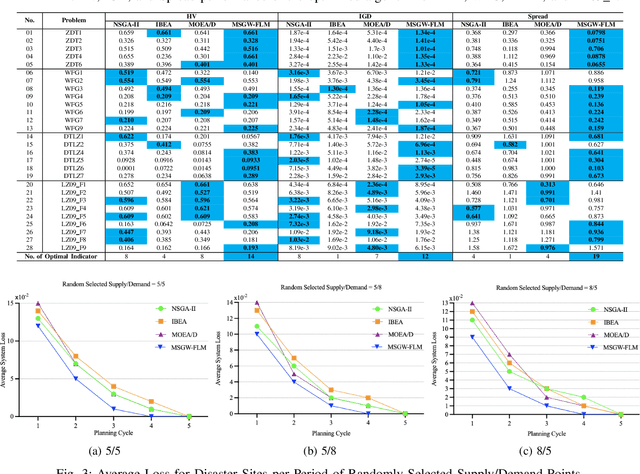
Emergency relief operations are essential in disaster aftermaths, necessitating effective resource allocation to minimize negative impacts and maximize benefits. In prolonged crises or extensive disasters, a systematic, multi-cycle approach is key for timely and informed decision-making. Leveraging advancements in IoT and spatio-temporal data analytics, we've developed the Multi-Objective Shuffled Gray-Wolf Frog Leaping Model (MSGW-FLM). This multi-constraint, multi-objective resource allocation model has been rigorously tested against 28 diverse challenges, showing superior performance in comparison to established models such as NSGA-II, IBEA, and MOEA/D. MSGW-FLM's effectiveness is particularly notable in complex, multi-cycle emergency rescue scenarios, which involve numerous constraints and objectives. This model represents a significant step forward in optimizing resource distribution in emergency response situations.