 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Camera Choice: An Empirical Study on Fisheye Camera Properties in Robotic Manipulation
Mar 02, 2026The adoption of fisheye cameras in robotic manipulation, driven by their exceptionally wide Field of View (FoV), is rapidly outpacing a systematic understanding of their downstream effects on policy learning. This paper presents the first comprehensive empirical study to bridge this gap, rigorously analyzing the properties of wrist-mounted fisheye cameras for imitation learning. Through extensive experiments in both simulation and the real world, we investigate three critical research questions: spatial localization, scene generalization, and hardware generalization. Our investigation reveals that: (1) The wide FoV significantly enhances spatial localization, but this benefit is critically contingent on the visual complexity of the environment. (2) Fisheye-trained policies, while prone to overfitting in simple scenes, unlock superior scene generalization when trained with sufficient environmental diversity. (3) While naive cross-camera transfer leads to failures, we identify the root cause as scale overfitting and demonstrate that hardware generalization performance can be improved with a simple Random Scale Augmentation (RSA) strategy. Collectively, our findings provide concrete, actionable guidance for the large-scale collection and effective use of fisheye datasets in robotic learning. More results and videos are available on https://robo-fisheye.github.io/
UrbanGraphEmbeddings: Learning and Evaluating Spatially Grounded Multimodal Embeddings for Urban Science
Feb 09, 2026Learning transferable multimodal embeddings for urban environments is challenging because urban understanding is inherently spatial, yet existing datasets and benchmarks lack explicit alignment between street-view images and urban structure. We introduce UGData, a spatially grounded dataset that anchors street-view images to structured spatial graphs and provides graph-aligned supervision via spatial reasoning paths and spatial context captions, exposing distance, directionality, connectivity, and neighborhood context beyond image content. Building on UGData, we propose UGE, a two-stage training strategy that progressively and stably aligns images, text, and spatial structures by combining instruction-guided contrastive learning with graph-based spatial encoding. We finally introduce UGBench, a comprehensive benchmark to evaluate how spatially grounded embeddings support diverse urban understanding tasks -- including geolocation ranking, image retrieval, urban perception, and spatial grounding. We develop UGE on multiple state-of-the-art VLM backbones, including Qwen2-VL, Qwen2.5-VL, Phi-3-Vision, and LLaVA1.6-Mistral, and train fixed-dimensional spatial embeddings with LoRA tuning. UGE built upon Qwen2.5-VL-7B backbone achieves up to 44% improvement in image retrieval and 30% in geolocation ranking on training cities, and over 30% and 22% gains respectively on held-out cities, demonstrating the effectiveness of explicit spatial grounding for spatially intensive urban tasks.
Prompt Tuning without Labeled Samples for Zero-Shot Node Classification in Text-Attributed Graphs
Jan 07, 2026Node classification is a fundamental problem in information retrieval with many real-world applications, such as community detection in social networks, grouping articles published online and product categorization in e-commerce. Zero-shot node classification in text-attributed graphs (TAGs) presents a significant challenge, particularly due to the absence of labeled data. In this paper, we propose a novel Zero-shot Prompt Tuning (ZPT) framework to address this problem by leveraging a Universal Bimodal Conditional Generator (UBCG). Our approach begins with pre-training a graph-language model to capture both the graph structure and the associated textual descriptions of each node. Following this, a conditional generative model is trained to learn the joint distribution of nodes in both graph and text modalities, enabling the generation of synthetic samples for each class based solely on the class name. These synthetic node and text embeddings are subsequently used to perform continuous prompt tuning, facilitating effective node classification in a zero-shot setting. Furthermore, we conduct extensive experiments on multiple benchmark datasets, demonstrating that our framework performs better than existing state-of-the-art baselines. We also provide ablation studies to validate the contribution of the bimodal generator. The code is provided at: https://github.com/Sethup123/ZPT.
Time-Aware Adaptive Side Information Fusion for Sequential Recommendation
Dec 30, 2025Incorporating item-side information, such as category and brand, into sequential recommendation is a well-established and effective approach for improving performance. However, despite significant advancements, current models are generally limited by three key challenges: they often overlook the fine-grained temporal dynamics inherent in timestamps, exhibit vulnerability to noise in user interaction sequences, and rely on computationally expensive fusion architectures. To systematically address these challenges, we propose the Time-Aware Adaptive Side Information Fusion (TASIF) framework. TASIF integrates three synergistic components: (1) a simple, plug-and-play time span partitioning mechanism to capture global temporal patterns; (2) an adaptive frequency filter that leverages a learnable gate to denoise feature sequences adaptively, thereby providing higher-quality inputs for subsequent fusion modules; and (3) an efficient adaptive side information fusion layer, this layer employs a "guide-not-mix" architecture, where attributes guide the attention mechanism without being mixed into the content-representing item embeddings, ensuring deep interaction while ensuring computational efficiency. Extensive experiments on four public datasets demonstrate that TASIF significantly outperforms state-of-the-art baselines while maintaining excellent efficiency in training. Our source code is available at https://github.com/jluo00/TASIF.
A Surrogate-Augmented Symbolic CFD-Driven Training Framework for Accelerating Multi-objective Physical Model Development
Dec 22, 2025Computational Fluid Dynamics (CFD)-driven training combines machine learning (ML) with CFD solvers to develop physically consistent closure models with improved predictive accuracy. In the original framework, each ML-generated candidate model is embedded in a CFD solver and evaluated against reference data, requiring hundreds to thousands of high-fidelity simulations and resulting in prohibitive computational cost for complex flows. To overcome this limitation, we propose an extended framework that integrates surrogate modeling into symbolic CFD-driven training in real time to reduce training cost. The surrogate model learns to approximate the errors of ML-generated models based on previous CFD evaluations and is continuously refined during training. Newly generated models are first assessed using the surrogate, and only those predicted to yield small errors or high uncertainty are subsequently evaluated with full CFD simulations. Discrete expressions generated by symbolic regression are mapped into a continuous space using averaged input-symbol values as inputs to a probabilistic surrogate model. To support multi-objective model training, particularly when fixed weighting of competing quantities is challenging, the surrogate is extended to a multi-output formulation by generalizing the kernel to a matrix form, providing one mean and variance prediction per training objective. Selection metrics based on these probabilistic outputs are used to identify an optimal training setup. The proposed surrogate-augmented CFD-driven training framework is demonstrated across a range of statistically one- and two-dimensional flows, including both single- and multi-expression model optimization. In all cases, the framework substantially reduces training cost while maintaining predictive accuracy comparable to that of the original CFD-driven approach.
CORE: Contrastive Masked Feature Reconstruction on Graphs
Dec 15, 2025In the rapidly evolving field of self-supervised learning on graphs, generative and contrastive methodologies have emerged as two dominant approaches. Our study focuses on masked feature reconstruction (MFR), a generative technique where a model learns to restore the raw features of masked nodes in a self-supervised manner. We observe that both MFR and graph contrastive learning (GCL) aim to maximize agreement between similar elements. Building on this observation, we reveal a novel theoretical insight: under specific conditions, the objectives of MFR and node-level GCL converge, despite their distinct operational mechanisms. This theoretical connection suggests these approaches are complementary rather than fundamentally different, prompting us to explore their integration to enhance self-supervised learning on graphs. Our research presents Contrastive Masked Feature Reconstruction (CORE), a novel graph self-supervised learning framework that integrates contrastive learning into MFR. Specifically, we form positive pairs exclusively between the original and reconstructed features of masked nodes, encouraging the encoder to prioritize contextual information over the node's own features. Additionally, we leverage the masked nodes themselves as negative samples, combining MFR's reconstructive power with GCL's discriminative ability to better capture intrinsic graph structures. Empirically, our proposed framework CORE significantly outperforms MFR across node and graph classification tasks, demonstrating state-of-the-art results. In particular, CORE surpasses GraphMAE and GraphMAE2 by up to 2.80% and 3.72% on node classification tasks, and by up to 3.82% and 3.76% on graph classification tasks.
Unified Molecule Pre-training with Flexible 2D and 3D Modalities: Single and Paired Modality Integration
Oct 08, 2025Molecular representation learning plays a crucial role in advancing applications such as drug discovery and material design. Existing work leverages 2D and 3D modalities of molecular information for pre-training, aiming to capture comprehensive structural and geometric insights. However, these methods require paired 2D and 3D molecular data to train the model effectively and prevent it from collapsing into a single modality, posing limitations in scenarios where a certain modality is unavailable or computationally expensive to generate. To overcome this limitation, we propose FlexMol, a flexible molecule pre-training framework that learns unified molecular representations while supporting single-modality input. Specifically, inspired by the unified structure in vision-language models, our approach employs separate models for 2D and 3D molecular data, leverages parameter sharing to improve computational efficiency, and utilizes a decoder to generate features for the missing modality. This enables a multistage continuous learning process where both modalities contribute collaboratively during training, while ensuring robustness when only one modality is available during inference. Extensive experiments demonstrate that FlexMol achieves superior performance across a wide range of molecular property prediction tasks, and we also empirically demonstrate its effectiveness with incomplete data. Our code and data are available at https://github.com/tewiSong/FlexMol.
MolGA: Molecular Graph Adaptation with Pre-trained 2D Graph Encoder
Oct 08, 2025Molecular graph representation learning is widely used in chemical and biomedical research. While pre-trained 2D graph encoders have demonstrated strong performance, they overlook the rich molecular domain knowledge associated with submolecular instances (atoms and bonds). While molecular pre-training approaches incorporate such knowledge into their pre-training objectives, they typically employ designs tailored to a specific type of knowledge, lacking the flexibility to integrate diverse knowledge present in molecules. Hence, reusing widely available and well-validated pre-trained 2D encoders, while incorporating molecular domain knowledge during downstream adaptation, offers a more practical alternative. In this work, we propose MolGA, which adapts pre-trained 2D graph encoders to downstream molecular applications by flexibly incorporating diverse molecular domain knowledge. First, we propose a molecular alignment strategy that bridge the gap between pre-trained topological representations with domain-knowledge representations. Second, we introduce a conditional adaptation mechanism that generates instance-specific tokens to enable fine-grained integration of molecular domain knowledge for downstream tasks. Finally, we conduct extensive experiments on eleven public datasets, demonstrating the effectiveness of MolGA.
DF-LLaVA: Unlocking MLLM's potential for Synthetic Image Detection via Prompt-Guided Knowledge Injection
Sep 18, 2025With the increasing prevalence of synthetic images, evaluating image authenticity and locating forgeries accurately while maintaining human interpretability remains a challenging task. Existing detection models primarily focus on simple authenticity classification, ultimately providing only a forgery probability or binary judgment, which offers limited explanatory insights into image authenticity. Moreover, while MLLM-based detection methods can provide more interpretable results, they still lag behind expert models in terms of pure authenticity classification accuracy. To address this, we propose DF-LLaVA, a simple yet effective framework that unlocks the intrinsic discrimination potential of MLLMs. Our approach first extracts latent knowledge from MLLMs and then injects it into training via prompts. This framework allows LLaVA to achieve outstanding detection accuracy exceeding expert models while still maintaining the interpretability offered by MLLMs. Extensive experiments confirm the superiority of our DF-LLaVA, achieving both high accuracy and explainability in synthetic image detection. Code is available online at: https://github.com/Eliot-Shen/DF-LLaVA.
CubeDN: Real-time Drone Detection in 3D Space from Dual mmWave Radar Cubes
Aug 25, 2025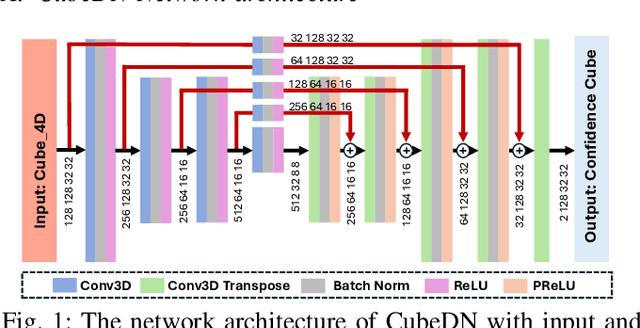
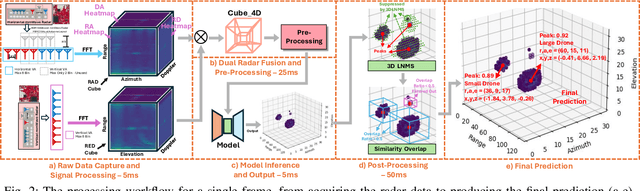


As drone use has become more widespread, there is a critical need to ensure safety and security. A key element of this is robust and accurate drone detection and localization. While cameras and other optical sensors like LiDAR are commonly used for object detection, their performance degrades under adverse lighting and environmental conditions. Therefore, this has generated interest in finding more reliable alternatives, such as millimeter-wave (mmWave) radar. Recent research on mmWave radar object detection has predominantly focused on 2D detection of road users. Although these systems demonstrate excellent performance for 2D problems, they lack the sensing capability to measure elevation, which is essential for 3D drone detection. To address this gap, we propose CubeDN, a single-stage end-to-end radar object detection network specifically designed for flying drones. CubeDN overcomes challenges such as poor elevation resolution by utilizing a dual radar configuration and a novel deep learning pipeline. It simultaneously detects, localizes, and classifies drones of two sizes, achieving decimeter-level tracking accuracy at closer ranges with overall $95\%$ average precision (AP) and $85\%$ average recall (AR). Furthermore, CubeDN completes data processing and inference at 10Hz, making it highly suitable for practical applications.