 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSO3UFormer: Learning Intrinsic Spherical Features for Rotation-Robust Panoramic Segmentation
Feb 26, 2026Panoramic semantic segmentation models are typically trained under a strict gravity-aligned assumption. However, real-world captures often deviate from this canonical orientation due to unconstrained camera motions, such as the rotational jitter of handheld devices or the dynamic attitude shifts of aerial platforms. This discrepancy causes standard spherical Transformers to overfit global latitude cues, leading to performance collapse under 3D reorientations. To address this, we introduce SO3UFormer, a rotation-robust architecture designed to learn intrinsic spherical features that are less sensitive to the underlying coordinate frame. Our approach rests on three geometric pillars: (1) an intrinsic feature formulation that decouples the representation from the gravity vector by removing absolute latitude encoding; (2) quadrature-consistent spherical attention that accounts for non-uniform sampling densities; and (3) a gauge-aware relative positional mechanism that encodes local angular geometry using tangent-plane projected angles and discrete gauge pooling, avoiding reliance on global axes. We further use index-based spherical resampling together with a logit-level SO(3)-consistency regularizer during training. To rigorously benchmark robustness, we introduce Pose35, a dataset variant of Stanford2D3D perturbed by random rotations within $\pm 35^\circ$. Under the extreme test of arbitrary full SO(3) rotations, existing SOTAs fail catastrophically: the baseline SphereUFormer drops from 67.53 mIoU to 25.26 mIoU. In contrast, SO3UFormer demonstrates remarkable stability, achieving 72.03 mIoU on Pose35 and retaining 70.67 mIoU under full SO(3) rotations.
From Landslide Conditioning Factors to Satellite Embeddings: Evaluating the Utilisation of Google AlphaEarth for Landslide Susceptibility Mapping using Deep Learning
Jan 12, 2026Data-driven landslide susceptibility mapping (LSM) typically relies on landslide conditioning factors (LCFs), whose availability, heterogeneity, and preprocessing-related uncertainties can constrain mapping reliability. Recently, Google AlphaEarth (AE) embeddings, derived from multi-source geospatial observations, have emerged as a unified representation of Earth surface conditions. This study evaluated the potential of AE embeddings as alternative predictors for LSM. Two AE representations, including retained principal components and the full set of 64 embedding bands, were systematically compared with conventional LCFs across three study areas (Nantou County, Taiwan; Hong Kong; and part of Emilia-Romagna, Italy) using three deep learning models (CNN1D, CNN2D, and Vision Transformer). Performance was assessed using multiple evaluation metrics, ROC-AUC analysis, error statistics, and spatial pattern assessment. Results showed that AE-based models consistently outperformed LCFs across all regions and models, yielding higher F1-scores, AUC values, and more stable error distributions. Such improvement was most pronounced when using the full 64-band AE representation, with F1-score improvements of approximately 4% to 15% and AUC increased ranging from 0.04 to 0.11, depending on the study area and model. AE-based susceptibility maps also exhibited clearer spatial correspondence with observed landslide occurrences and enhanced sensitivity to localised landslide-prone conditions. Performance improvements were more evident in Nantou and Emilia than in Hong Kong, revealing that closer temporal alignment between AE embeddings and landslide inventories may lead to more effective LSM outcomes. These findings highlight the strong potential of AE embeddings as a standardised and information-rich alternative to conventional LCFs for LSM.
ClassWise-CRF: Category-Specific Fusion for Enhanced Semantic Segmentation of Remote Sensing Imagery
Apr 30, 2025We propose a result-level category-specific fusion architecture called ClassWise-CRF. This architecture employs a two-stage process: first, it selects expert networks that perform well in specific categories from a pool of candidate networks using a greedy algorithm; second, it integrates the segmentation predictions of these selected networks by adaptively weighting their contributions based on their segmentation performance in each category. Inspired by Conditional Random Field (CRF), the ClassWise-CRF architecture treats the segmentation predictions from multiple networks as confidence vector fields. It leverages segmentation metrics (such as Intersection over Union) from the validation set as priors and employs an exponential weighting strategy to fuse the category-specific confidence scores predicted by each network. This fusion method dynamically adjusts the weights of each network for different categories, achieving category-specific optimization. Building on this, the architecture further optimizes the fused results using unary and pairwise potentials in CRF to ensure spatial consistency and boundary accuracy. To validate the effectiveness of ClassWise-CRF, we conducted experiments on two remote sensing datasets, LoveDA and Vaihingen, using eight classic and advanced semantic segmentation networks. The results show that the ClassWise-CRF architecture significantly improves segmentation performance: on the LoveDA dataset, the mean Intersection over Union (mIoU) metric increased by 1.00% on the validation set and by 0.68% on the test set; on the Vaihingen dataset, the mIoU improved by 0.87% on the validation set and by 0.91% on the test set. These results fully demonstrate the effectiveness and generality of the ClassWise-CRF architecture in semantic segmentation of remote sensing images. The full code is available at https://github.com/zhuqinfeng1999/ClassWise-CRF.
MSCrackMamba: Leveraging Vision Mamba for Crack Detection in Fused Multispectral Imagery
Dec 09, 2024Crack detection is a critical task in structural health monitoring, aimed at assessing the structural integrity of bridges, buildings, and roads to prevent potential failures. Vision-based crack detection has become the mainstream approach due to its ease of implementation and effectiveness. Fusing infrared (IR) channels with red, green and blue (RGB) channels can enhance feature representation and thus improve crack detection. However, IR and RGB channels often differ in resolution. To align them, higher-resolution RGB images typically need to be downsampled to match the IR image resolution, which leads to the loss of fine details. Moreover, crack detection performance is restricted by the limited receptive fields and high computational complexity of traditional image segmentation networks. Inspired by the recently proposed Mamba neural architecture, this study introduces a two-stage paradigm called MSCrackMamba, which leverages Vision Mamba along with a super-resolution network to address these challenges. Specifically, to align IR and RGB channels, we first apply super-resolution to IR channels to match the resolution of RGB channels for data fusion. Vision Mamba is then adopted as the backbone network, while UperNet is employed as the decoder for crack detection. Our approach is validated on the large-scale Crack Detection dataset Crack900, demonstrating an improvement of 3.55% in mIoU compared to the best-performing baseline methods.
Evaluating the Impact of Point Cloud Colorization on Semantic Segmentation Accuracy
Oct 09, 2024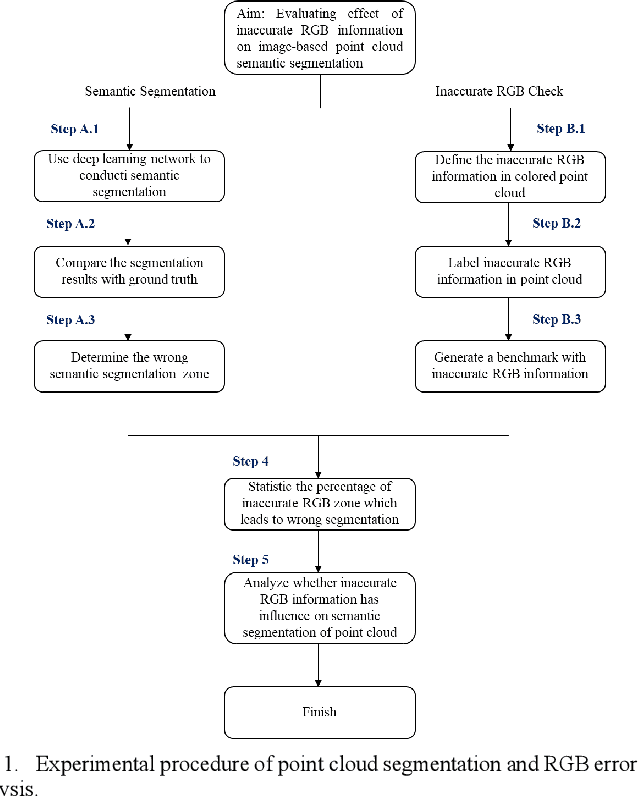
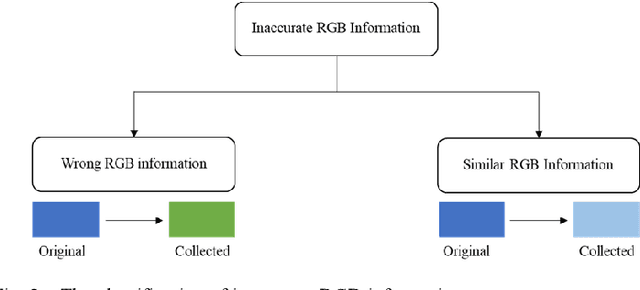


Point cloud semantic segmentation, the process of classifying each point into predefined categories, is essential for 3D scene understanding. While image-based segmentation is widely adopted due to its maturity, methods relying solely on RGB information often suffer from degraded performance due to color inaccuracies. Recent advancements have incorporated additional features such as intensity and geometric information, yet RGB channels continue to negatively impact segmentation accuracy when errors in colorization occur. Despite this, previous studies have not rigorously quantified the effects of erroneous colorization on segmentation performance. In this paper, we propose a novel statistical approach to evaluate the impact of inaccurate RGB information on image-based point cloud segmentation. We categorize RGB inaccuracies into two types: incorrect color information and similar color information. Our results demonstrate that both types of color inaccuracies significantly degrade segmentation accuracy, with similar color errors particularly affecting the extraction of geometric features. These findings highlight the critical need to reassess the role of RGB information in point cloud segmentation and its implications for future algorithm design.
Enhancing Environmental Monitoring through Multispectral Imaging: The WasteMS Dataset for Semantic Segmentation of Lakeside Waste
Jul 25, 2024

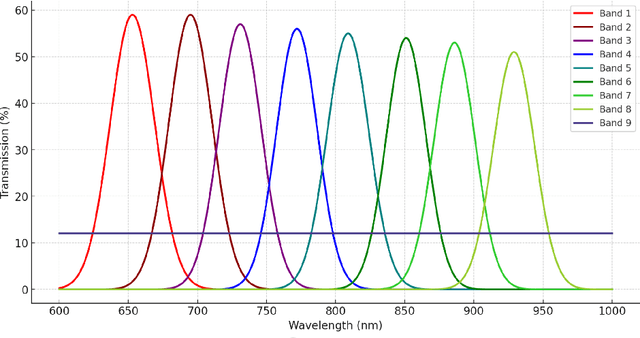
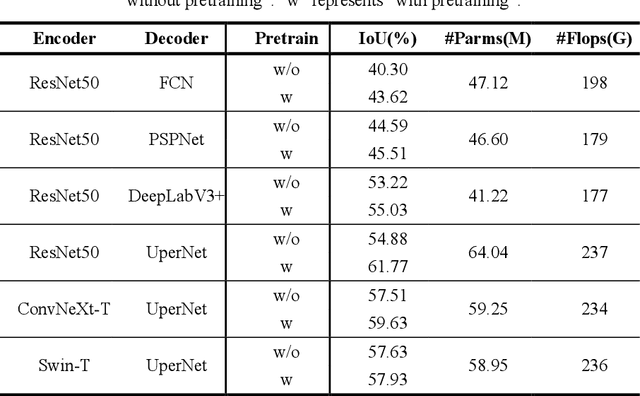
Environmental monitoring of lakeside green areas is crucial for environmental protection. Compared to manual inspections, computer vision technologies offer a more efficient solution when deployed on-site. Multispectral imaging provides diverse information about objects under different spectrums, aiding in the differentiation between waste and lakeside lawn environments. This study introduces WasteMS, the first multispectral dataset established for the semantic segmentation of lakeside waste. WasteMS includes a diverse range of waste types in lawn environments, captured under various lighting conditions. We implemented a rigorous annotation process to label waste in images. Representative semantic segmentation frameworks were used to evaluate segmentation accuracy using WasteMS. Challenges encountered when using WasteMS for segmenting waste on lakeside lawns were discussed. The WasteMS dataset is available at https://github.com/zhuqinfeng1999/WasteMS.
Seg-LSTM: Performance of xLSTM for Semantic Segmentation of Remotely Sensed Images
Jun 20, 2024Recent advancements in autoregressive networks with linear complexity have driven significant research progress, demonstrating exceptional performance in large language models. A representative model is the Extended Long Short-Term Memory (xLSTM), which incorporates gating mechanisms and memory structures, performing comparably to Transformer architectures in long-sequence language tasks. Autoregressive networks such as xLSTM can utilize image serialization to extend their application to visual tasks such as classification and segmentation. Although existing studies have demonstrated Vision-LSTM's impressive results in image classification, its performance in image semantic segmentation remains unverified. Our study represents the first attempt to evaluate the effectiveness of Vision-LSTM in the semantic segmentation of remotely sensed images. This evaluation is based on a specifically designed encoder-decoder architecture named Seg-LSTM, and comparisons with state-of-the-art segmentation networks. Our study found that Vision-LSTM's performance in semantic segmentation was limited and generally inferior to Vision-Transformers-based and Vision-Mamba-based models in most comparative tests. Future research directions for enhancing Vision-LSTM are recommended. The source code is available from https://github.com/zhuqinfeng1999/Seg-LSTM.
Rethinking Scanning Strategies with Vision Mamba in Semantic Segmentation of Remote Sensing Imagery: An Experimental Study
May 14, 2024
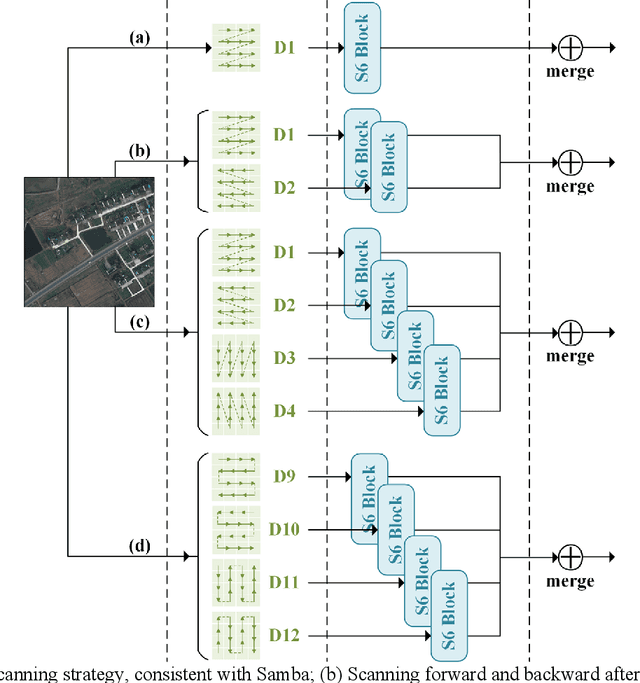
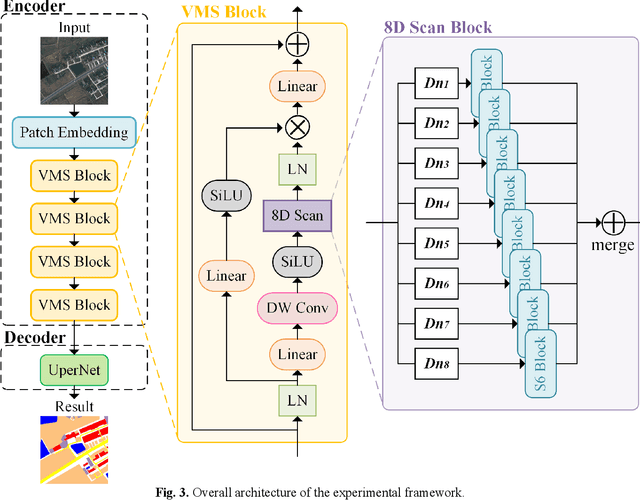
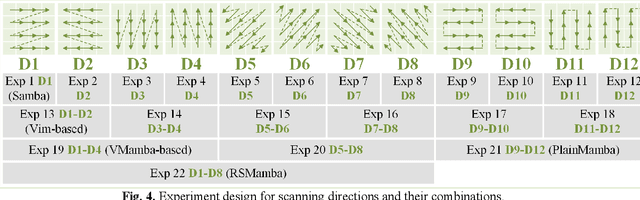
Deep learning methods, especially Convolutional Neural Networks (CNN) and Vision Transformer (ViT), are frequently employed to perform semantic segmentation of high-resolution remotely sensed images. However, CNNs are constrained by their restricted receptive fields, while ViTs face challenges due to their quadratic complexity. Recently, the Mamba model, featuring linear complexity and a global receptive field, has gained extensive attention for vision tasks. In such tasks, images need to be serialized to form sequences compatible with the Mamba model. Numerous research efforts have explored scanning strategies to serialize images, aiming to enhance the Mamba model's understanding of images. However, the effectiveness of these scanning strategies remains uncertain. In this research, we conduct a comprehensive experimental investigation on the impact of mainstream scanning directions and their combinations on semantic segmentation of remotely sensed images. Through extensive experiments on the LoveDA, ISPRS Potsdam, and ISPRS Vaihingen datasets, we demonstrate that no single scanning strategy outperforms others, regardless of their complexity or the number of scanning directions involved. A simple, single scanning direction is deemed sufficient for semantic segmentation of high-resolution remotely sensed images. Relevant directions for future research are also recommended.
Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
Apr 11, 2024
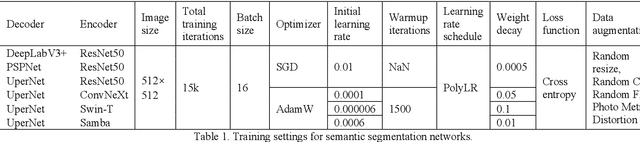
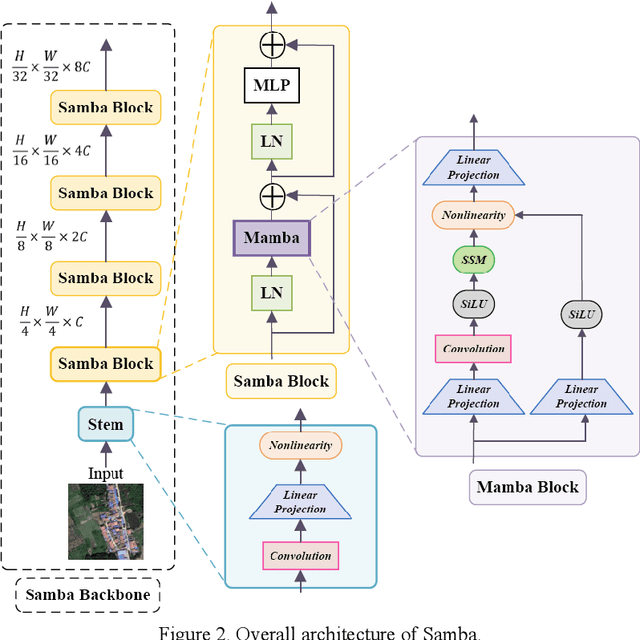
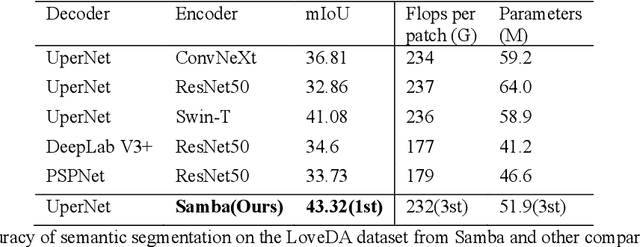
High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey
Aug 23, 2023Point cloud has a wide range of applications in areas such as autonomous driving, mapping, navigation, scene reconstruction, and medical imaging. Due to its great potentials in these applications, point cloud processing has gained great attention in the field of computer vision. Among various point cloud processing techniques, deep learning (DL) has become one of the mainstream and effective methods for tasks such as detection, segmentation and classification. To reduce overfitting during training DL models and improve model performance especially when the amount and/or diversity of training data are limited, augmentation is often crucial. Although various point cloud data augmentation methods have been widely used in different point cloud processing tasks, there are currently no published systematic surveys or reviews of these methods. Therefore, this article surveys and discusses these methods and categorizes them into a taxonomy framework. Through the comprehensive evaluation and comparison of the augmentation methods, this article identifies their potentials and limitations and suggests possible future research directions. This work helps researchers gain a holistic understanding of the current status of point cloud data augmentation and promotes its wider application and development.