 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Impact of Point Cloud Colorization on Semantic Segmentation Accuracy
Oct 09, 2024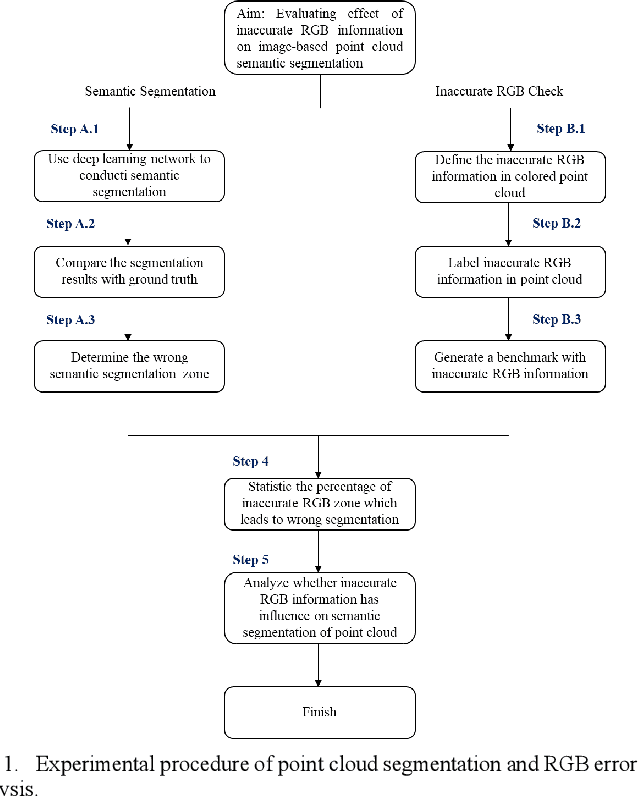
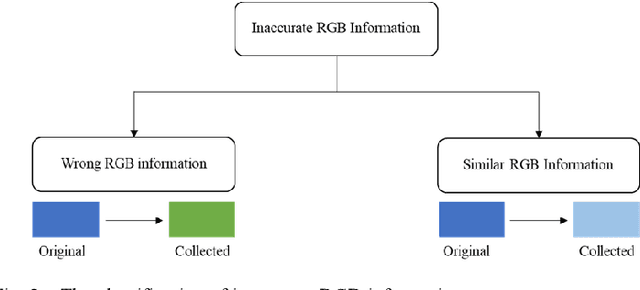


Point cloud semantic segmentation, the process of classifying each point into predefined categories, is essential for 3D scene understanding. While image-based segmentation is widely adopted due to its maturity, methods relying solely on RGB information often suffer from degraded performance due to color inaccuracies. Recent advancements have incorporated additional features such as intensity and geometric information, yet RGB channels continue to negatively impact segmentation accuracy when errors in colorization occur. Despite this, previous studies have not rigorously quantified the effects of erroneous colorization on segmentation performance. In this paper, we propose a novel statistical approach to evaluate the impact of inaccurate RGB information on image-based point cloud segmentation. We categorize RGB inaccuracies into two types: incorrect color information and similar color information. Our results demonstrate that both types of color inaccuracies significantly degrade segmentation accuracy, with similar color errors particularly affecting the extraction of geometric features. These findings highlight the critical need to reassess the role of RGB information in point cloud segmentation and its implications for future algorithm design.
Enhancing Environmental Monitoring through Multispectral Imaging: The WasteMS Dataset for Semantic Segmentation of Lakeside Waste
Jul 25, 2024

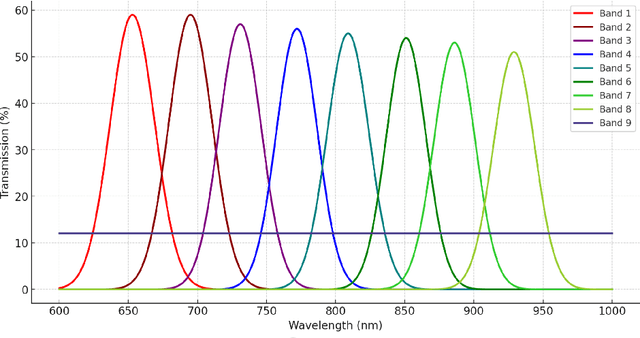
Environmental monitoring of lakeside green areas is crucial for environmental protection. Compared to manual inspections, computer vision technologies offer a more efficient solution when deployed on-site. Multispectral imaging provides diverse information about objects under different spectrums, aiding in the differentiation between waste and lakeside lawn environments. This study introduces WasteMS, the first multispectral dataset established for the semantic segmentation of lakeside waste. WasteMS includes a diverse range of waste types in lawn environments, captured under various lighting conditions. We implemented a rigorous annotation process to label waste in images. Representative semantic segmentation frameworks were used to evaluate segmentation accuracy using WasteMS. Challenges encountered when using WasteMS for segmenting waste on lakeside lawns were discussed. The WasteMS dataset is available at https://github.com/zhuqinfeng1999/WasteMS.
Seg-LSTM: Performance of xLSTM for Semantic Segmentation of Remotely Sensed Images
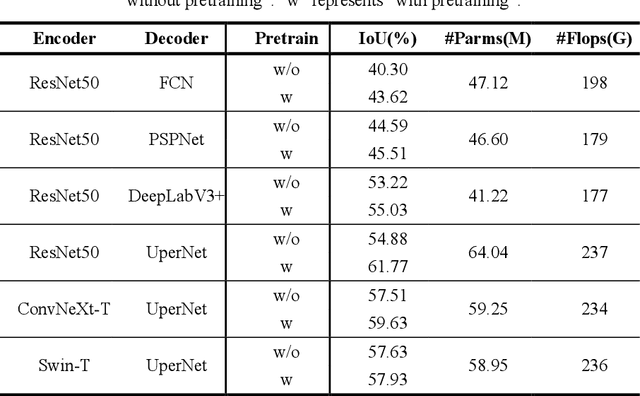
Jun 20, 2024Recent advancements in autoregressive networks with linear complexity have driven significant research progress, demonstrating exceptional performance in large language models. A representative model is the Extended Long Short-Term Memory (xLSTM), which incorporates gating mechanisms and memory structures, performing comparably to Transformer architectures in long-sequence language tasks. Autoregressive networks such as xLSTM can utilize image serialization to extend their application to visual tasks such as classification and segmentation. Although existing studies have demonstrated Vision-LSTM's impressive results in image classification, its performance in image semantic segmentation remains unverified. Our study represents the first attempt to evaluate the effectiveness of Vision-LSTM in the semantic segmentation of remotely sensed images. This evaluation is based on a specifically designed encoder-decoder architecture named Seg-LSTM, and comparisons with state-of-the-art segmentation networks. Our study found that Vision-LSTM's performance in semantic segmentation was limited and generally inferior to Vision-Transformers-based and Vision-Mamba-based models in most comparative tests. Future research directions for enhancing Vision-LSTM are recommended. The source code is available from https://github.com/zhuqinfeng1999/Seg-LSTM.
Rethinking Scanning Strategies with Vision Mamba in Semantic Segmentation of Remote Sensing Imagery: An Experimental Study
May 14, 2024
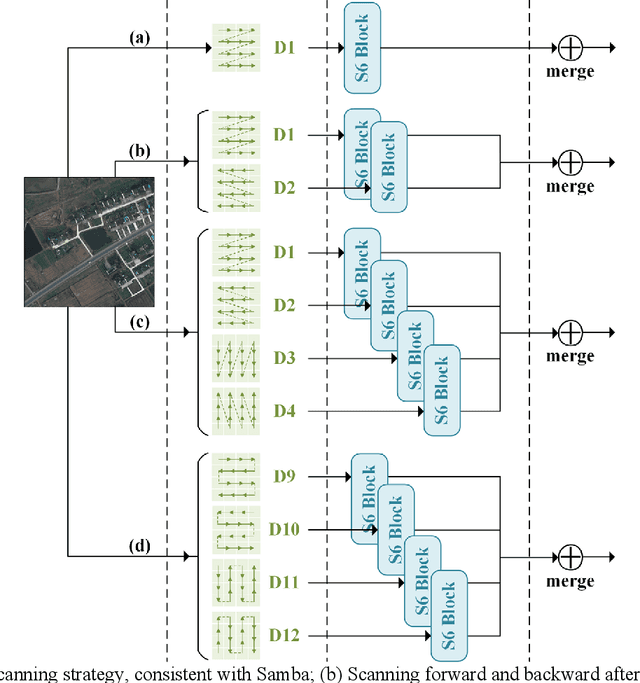
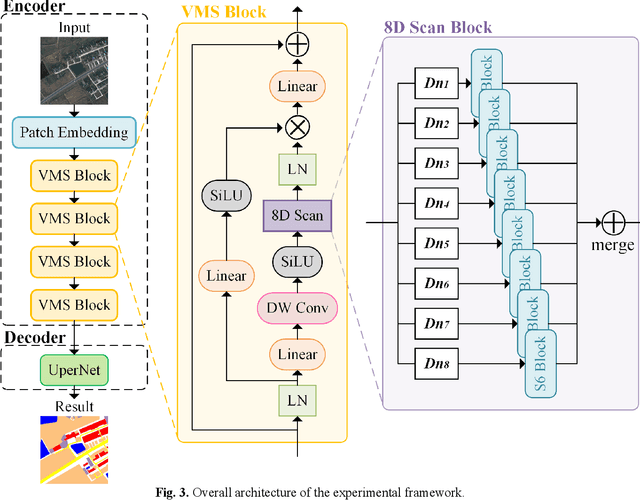
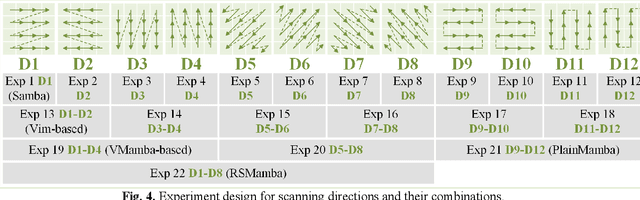
Deep learning methods, especially Convolutional Neural Networks (CNN) and Vision Transformer (ViT), are frequently employed to perform semantic segmentation of high-resolution remotely sensed images. However, CNNs are constrained by their restricted receptive fields, while ViTs face challenges due to their quadratic complexity. Recently, the Mamba model, featuring linear complexity and a global receptive field, has gained extensive attention for vision tasks. In such tasks, images need to be serialized to form sequences compatible with the Mamba model. Numerous research efforts have explored scanning strategies to serialize images, aiming to enhance the Mamba model's understanding of images. However, the effectiveness of these scanning strategies remains uncertain. In this research, we conduct a comprehensive experimental investigation on the impact of mainstream scanning directions and their combinations on semantic segmentation of remotely sensed images. Through extensive experiments on the LoveDA, ISPRS Potsdam, and ISPRS Vaihingen datasets, we demonstrate that no single scanning strategy outperforms others, regardless of their complexity or the number of scanning directions involved. A simple, single scanning direction is deemed sufficient for semantic segmentation of high-resolution remotely sensed images. Relevant directions for future research are also recommended.
Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
Apr 11, 2024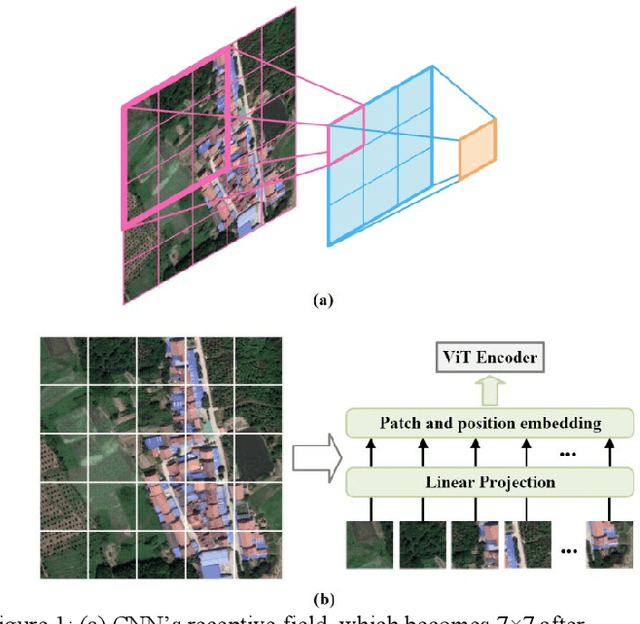
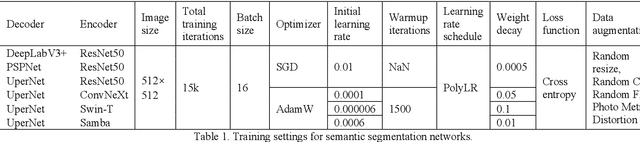
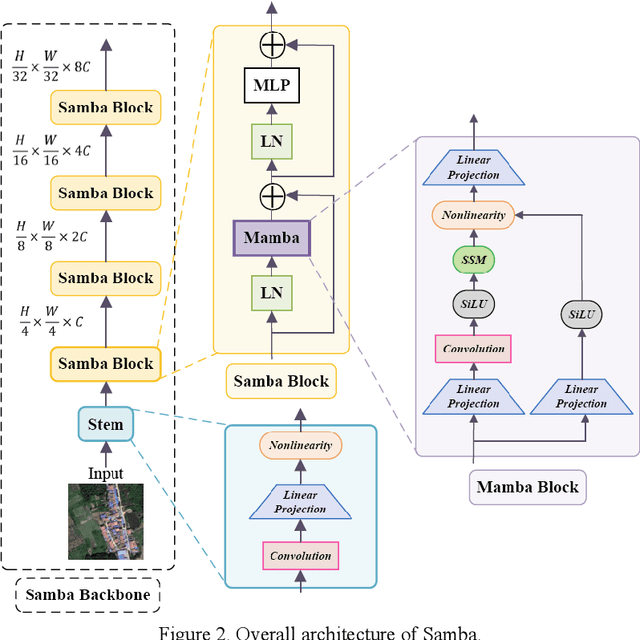
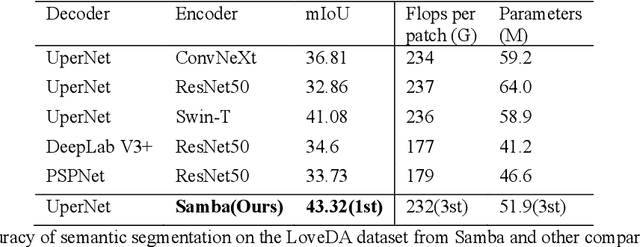
High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
SDRCNN: A single-scale dense residual connected convolutional neural network for pansharpening
Jul 01, 2023Pansharpening is a process of fusing a high spatial resolution panchromatic image and a low spatial resolution multispectral image to create a high-resolution multispectral image. A novel single-branch, single-scale lightweight convolutional neural network, named SDRCNN, is developed in this study. By using a novel dense residual connected structure and convolution block, SDRCNN achieved a better trade-off between accuracy and efficiency. The performance of SDRCNN was tested using four datasets from the WorldView-3, WorldView-2 and QuickBird satellites. The compared methods include eight traditional methods (i.e., GS, GSA, PRACS, BDSD, SFIM, GLP-CBD, CDIF and LRTCFPan) and five lightweight deep learning methods (i.e., PNN, PanNet, BayesianNet, DMDNet and FusionNet). Based on a visual inspection of the pansharpened images created and the associated absolute residual maps, SDRCNN exhibited least spatial detail blurring and spectral distortion, amongst all the methods considered. The values of the quantitative evaluation metrics were closest to their ideal values when SDRCNN was used. The processing time of SDRCNN was also the shortest among all methods tested. Finally, the effectiveness of each component in the SDRCNN was demonstrated in ablation experiments. All of these confirmed the superiority of SDRCNN.
OSTA: One-shot Task-adaptive Channel Selection for Semantic Segmentation of Multichannel Images
May 08, 2023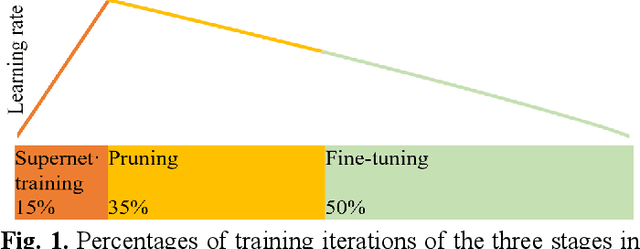
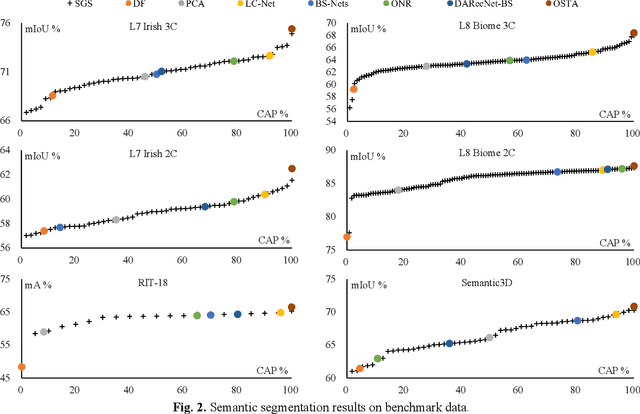

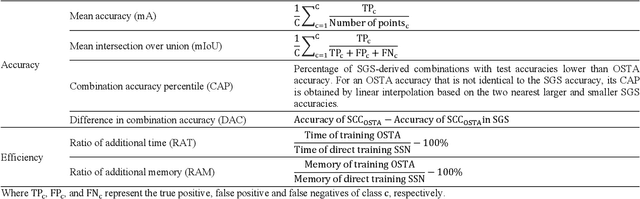
Semantic segmentation of multichannel images is a fundamental task for many applications. Selecting an appropriate channel combination from the original multichannel image can improve the accuracy of semantic segmentation and reduce the cost of data storage, processing and future acquisition. Existing channel selection methods typically use a reasonable selection procedure to determine a desirable channel combination, and then train a semantic segmentation network using that combination. In this study, the concept of pruning from a supernet is used for the first time to integrate the selection of channel combination and the training of a semantic segmentation network. Based on this concept, a One-Shot Task-Adaptive (OSTA) channel selection method is proposed for the semantic segmentation of multichannel images. OSTA has three stages, namely the supernet training stage, the pruning stage and the fine-tuning stage. The outcomes of six groups of experiments (L7Irish3C, L7Irish2C, L8Biome3C, L8Biome2C, RIT-18 and Semantic3D) demonstrated the effectiveness and efficiency of OSTA. OSTA achieved the highest segmentation accuracies in all tests (62.49% (mIoU), 75.40% (mIoU), 68.38% (mIoU), 87.63% (mIoU), 66.53% (mA) and 70.86% (mIoU), respectively). It even exceeded the highest accuracies of exhaustive tests (61.54% (mIoU), 74.91% (mIoU), 67.94% (mIoU), 87.32% (mIoU), 65.32% (mA) and 70.27% (mIoU), respectively), where all possible channel combinations were tested. All of this can be accomplished within a predictable and relatively efficient timeframe, ranging from 101.71% to 298.1% times the time required to train the segmentation network alone. In addition, there were interesting findings that were deemed valuable for several fields.
SBSS: Stacking-Based Semantic Segmentation Framework for Very High Resolution Remote Sensing Image
Dec 15, 2022Semantic segmentation of Very High Resolution (VHR) remote sensing images is a fundamental task for many applications. However, large variations in the scales of objects in those VHR images pose a challenge for performing accurate semantic segmentation. Existing semantic segmentation networks are able to analyse an input image at up to four resizing scales, but this may be insufficient given the diversity of object scales. Therefore, Multi Scale (MS) test-time data augmentation is often used in practice to obtain more accurate segmentation results, which makes equal use of the segmentation results obtained at the different resizing scales. However, it was found in this study that different classes of objects had their preferred resizing scale for more accurate semantic segmentation. Based on this behaviour, a Stacking-Based Semantic Segmentation (SBSS) framework is proposed to improve the segmentation results by learning this behaviour, which contains a learnable Error Correction Module (ECM) for segmentation result fusion and an Error Correction Scheme (ECS) for computational complexity control. Two ECS, i.e., ECS-MS and ECS-SS, are proposed and investigated in this study. The Floating-point operations (Flops) required for ECS-MS and ECS-SS are similar to the commonly used MS test and the Single-Scale (SS) test, respectively. Extensive experiments on four datasets (i.e., Cityscapes, UAVid, LoveDA and Potsdam) show that SBSS is an effective and flexible framework. It achieved higher accuracy than MS when using ECS-MS, and similar accuracy as SS with a quarter of the memory footprint when using ECS-SS.