 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-level Cross-view Geo-localization with Location Enhancement and Multi-Head Cross Attention
May 23, 2025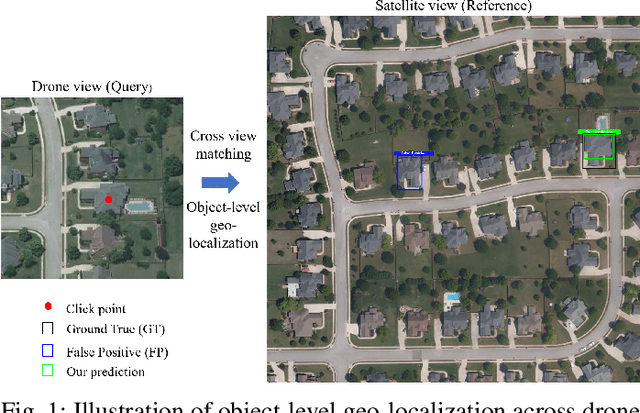
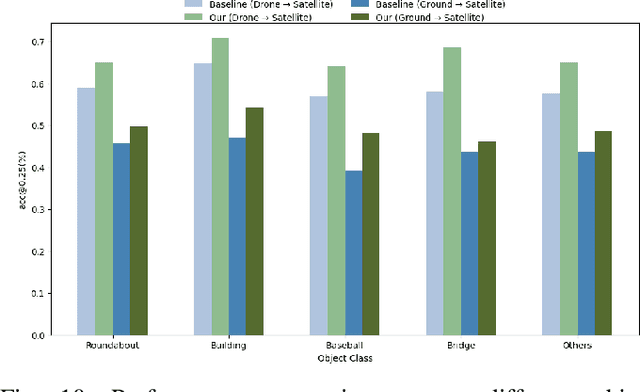
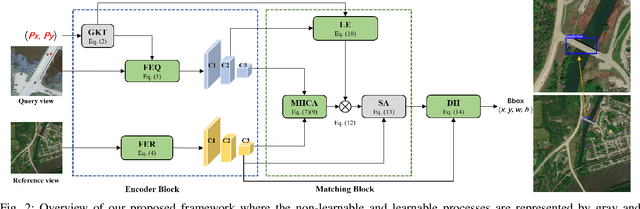
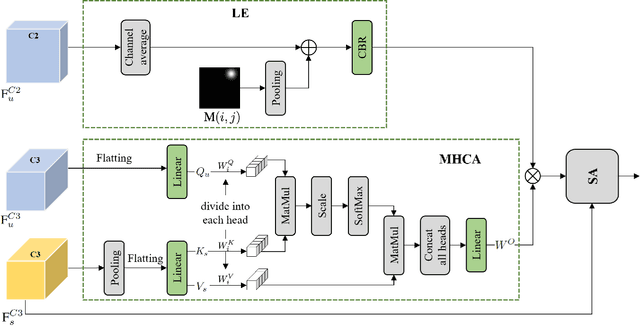
Cross-view geo-localization determines the location of a query image, captured by a drone or ground-based camera, by matching it to a geo-referenced satellite image. While traditional approaches focus on image-level localization, many applications, such as search-and-rescue, infrastructure inspection, and precision delivery, demand object-level accuracy. This enables users to prompt a specific object with a single click on a drone image to retrieve precise geo-tagged information of the object. However, variations in viewpoints, timing, and imaging conditions pose significant challenges, especially when identifying visually similar objects in extensive satellite imagery. To address these challenges, we propose an Object-level Cross-view Geo-localization Network (OCGNet). It integrates user-specified click locations using Gaussian Kernel Transfer (GKT) to preserve location information throughout the network. This cue is dually embedded into the feature encoder and feature matching blocks, ensuring robust object-specific localization. Additionally, OCGNet incorporates a Location Enhancement (LE) module and a Multi-Head Cross Attention (MHCA) module to adaptively emphasize object-specific features or expand focus to relevant contextual regions when necessary. OCGNet achieves state-of-the-art performance on a public dataset, CVOGL. It also demonstrates few-shot learning capabilities, effectively generalizing from limited examples, making it suitable for diverse applications (https://github.com/ZheyangH/OCGNet).
A Comprehensive Survey for Hyperspectral Image Classification: The Evolution from Conventional to Transformers
May 09, 2024



Hyperspectral Image Classification (HSC) is a challenging task due to the high dimensionality and complex nature of Hyperspectral (HS) data. Traditional Machine Learning approaches while effective, face challenges in real-world data due to varying optimal feature sets, subjectivity in human-driven design, biases, and limitations. Traditional approaches encounter the curse of dimensionality, struggle with feature selection and extraction, lack spatial information consideration, exhibit limited robustness to noise, face scalability issues, and may not adapt well to complex data distributions. In recent years, Deep Learning (DL) techniques have emerged as powerful tools for addressing these challenges. This survey provides a comprehensive overview of the current trends and future prospects in HSC, focusing on the advancements from DL models to the emerging use of Transformers. We review the key concepts, methodologies, and state-of-the-art approaches in DL for HSC. We explore the potential of Transformer-based models in HSC, outlining their benefits and challenges. We also delve into emerging trends in HSC, as well as thorough discussions on Explainable AI and Interoperability concepts along with Diffusion Models (image denoising, feature extraction, and image fusion). Lastly, we address several open challenges and research questions pertinent to HSC. Comprehensive experimental results have been undertaken using three HS datasets to verify the efficacy of various conventional DL models and Transformers. Finally, we outline future research directions and potential applications that can further enhance the accuracy and efficiency of HSC. The Source code is available at \href{https://github.com/mahmad00/Conventional-to-Transformer-for-Hyperspectral-Image-Classification-Survey-2024}{github.com/mahmad00}.
A Comparative Study of Knowledge Transfer Methods for Misaligned Urban Building Labels
Nov 07, 2023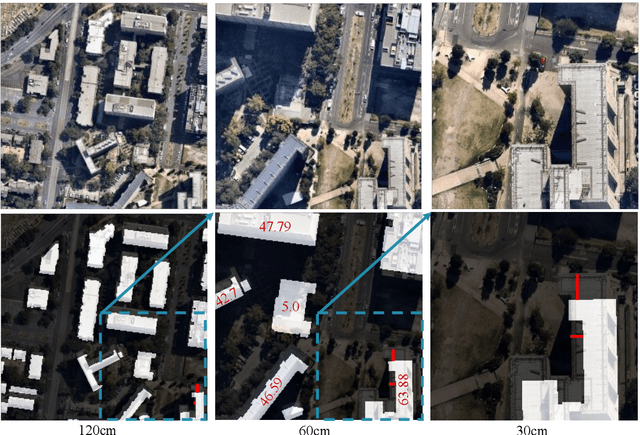
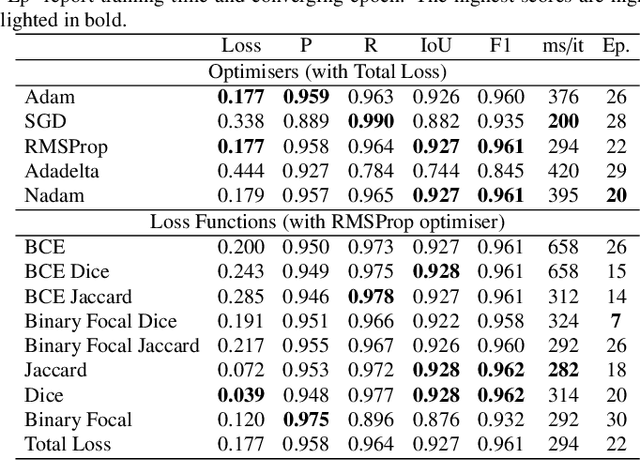
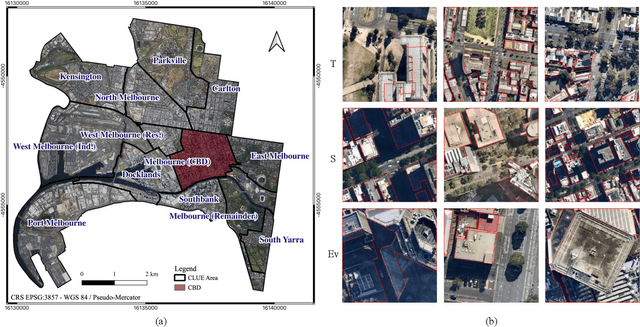
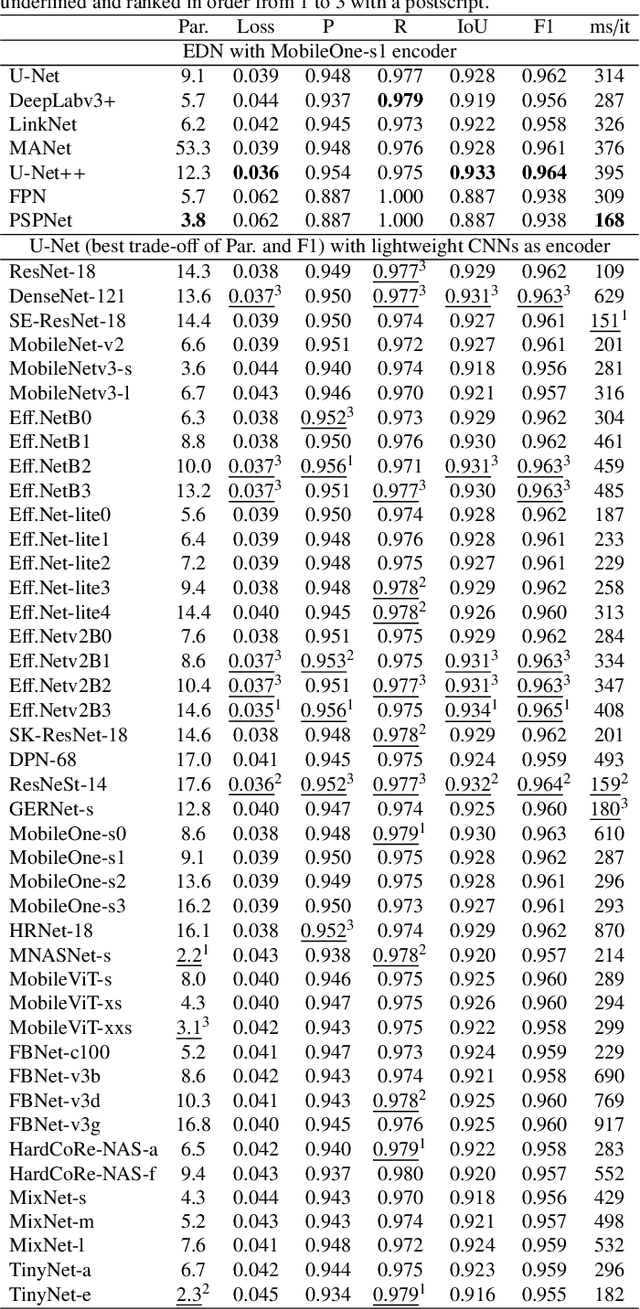
Misalignment in Earth observation (EO) images and building labels impact the training of accurate convolutional neural networks (CNNs) for semantic segmentation of building footprints. Recently, three Teacher-Student knowledge transfer methods have been introduced to address this issue: supervised domain adaptation (SDA), knowledge distillation (KD), and deep mutual learning (DML). However, these methods are merely studied for different urban buildings (low-rise, mid-rise, high-rise, and skyscrapers), where misalignment increases with building height and spatial resolution. In this study, we present a workflow for the systematic comparative study of the three methods. The workflow first identifies the best (with the highest evaluation scores) hyperparameters, lightweight CNNs for the Student (among 43 CNNs from Computer Vision), and encoder-decoder networks (EDNs) for both Teachers and Students. Secondly, three building footprint datasets are developed to train and evaluate the identified Teachers and Students in the three transfer methods. The results show that U-Net with VGG19 (U-VGG19) is the best Teacher, and U-EfficientNetv2B3 and U-EfficientNet-lite0 are among the best Students. With these Teacher-Student pairs, SDA could yield upto 0.943, 0.868, 0.912, and 0.697 F1 scores in the low-rise, mid-rise, high-rise, and skyscrapers respectively. KD and DML provide model compression of upto 82%, despite marginal loss in performance. This new comparison concludes that SDA is the most effective method to address the misalignment problem, while KD and DML can efficiently compress network size without significant loss in performance. The 158 experiments and datasets developed in this study will be valuable to minimise the misaligned labels.
A Novel Multi-scale Attention Feature Extraction Block for Aerial Remote Sensing Image Classification
Aug 27, 2023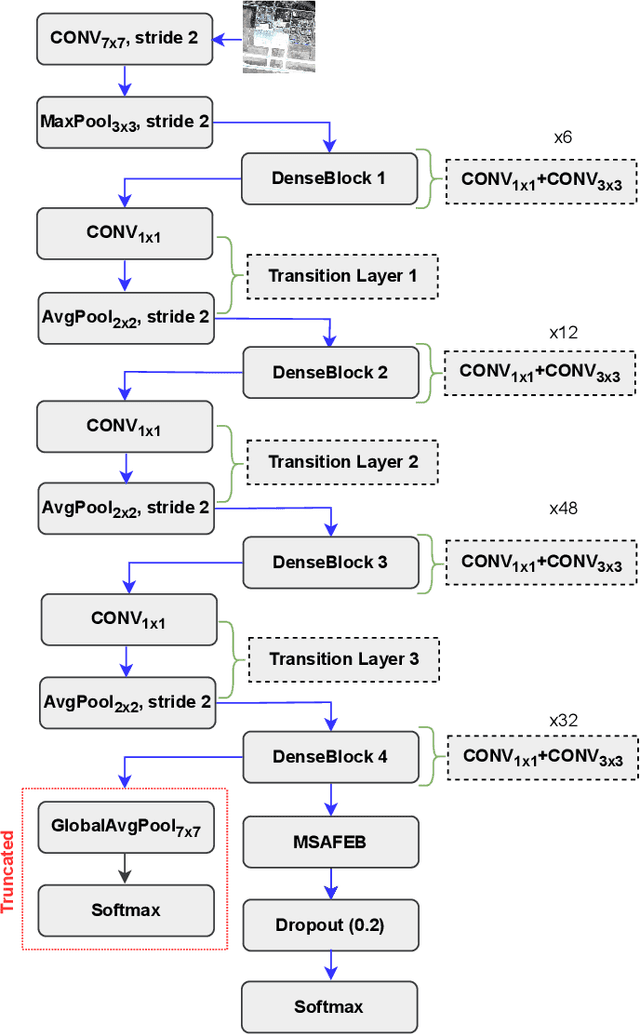
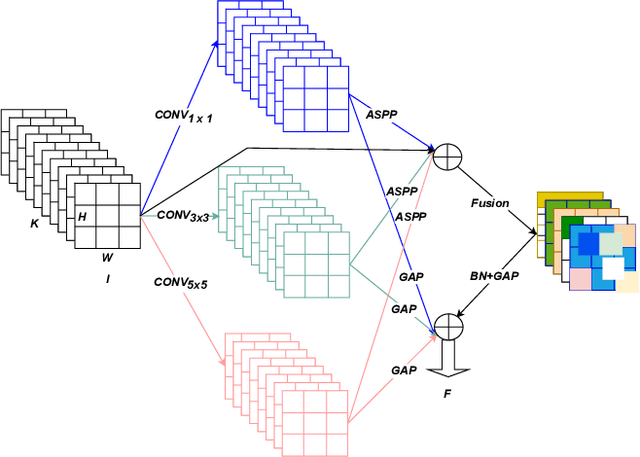

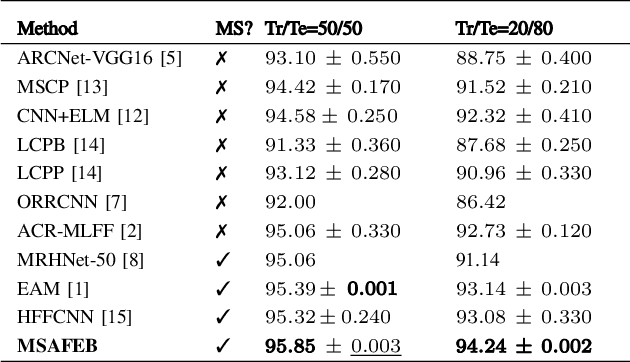
Classification of very high-resolution (VHR) aerial remote sensing (RS) images is a well-established research area in the remote sensing community as it provides valuable spatial information for decision-making. Existing works on VHR aerial RS image classification produce an excellent classification performance; nevertheless, they have a limited capability to well-represent VHR RS images having complex and small objects, thereby leading to performance instability. As such, we propose a novel plug-and-play multi-scale attention feature extraction block (MSAFEB) based on multi-scale convolution at two levels with skip connection, producing discriminative/salient information at a deeper/finer level. The experimental study on two benchmark VHR aerial RS image datasets (AID and NWPU) demonstrates that our proposal achieves a stable/consistent performance (minimum standard deviation of $0.002$) and competent overall classification performance (AID: 95.85\% and NWPU: 94.09\%).
Benchmarking Deep Learning Architectures for Urban Vegetation Points Segmentation
Jun 17, 2023
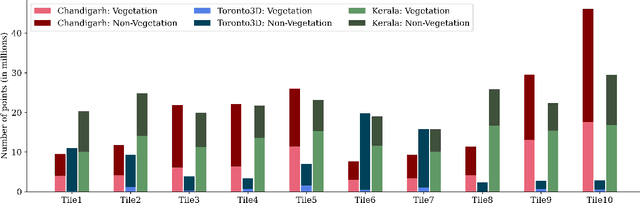
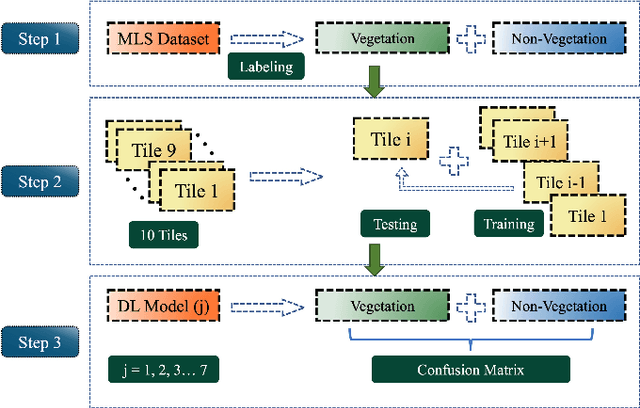
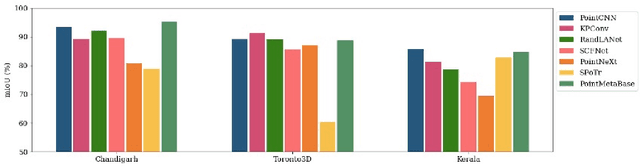
Vegetation is crucial for sustainable and resilient cities providing various ecosystem services and well-being of humans. However, vegetation is under critical stress with rapid urbanization and expanding infrastructure footprints. Consequently, mapping of this vegetation is essential in the urban environment. Recently, deep learning for point cloud semantic segmentation has shown significant progress. Advanced models attempt to obtain state-of-the-art performance on benchmark datasets, comprising multiple classes and representing real world scenarios. However, class specific segmentation with respect to vegetation points has not been explored. Therefore, selection of a deep learning model for vegetation points segmentation is ambiguous. To address this problem, we provide a comprehensive assessment of point-based deep learning models for semantic segmentation of vegetation class. We have selected four representative point-based models, namely PointCNN, KPConv (omni-supervised), RandLANet and SCFNet. These models are investigated on three different datasets, specifically Chandigarh, Toronto3D and Kerala, which are characterized by diverse nature of vegetation, varying scene complexity and changing per-point features. PointCNN achieves the highest mIoU on the Chandigarh (93.32%) and Kerala datasets (85.68%) while KPConv (omni-supervised) provides the highest mIoU on the Toronto3D dataset (91.26%). The paper develops a deeper insight, hitherto not reported, into the working of these models for vegetation segmentation and outlines the ingredients that should be included in a model specifically for vegetation segmentation. This paper is a step towards the development of a novel architecture for vegetation points segmentation.
OSTA: One-shot Task-adaptive Channel Selection for Semantic Segmentation of Multichannel Images
May 08, 2023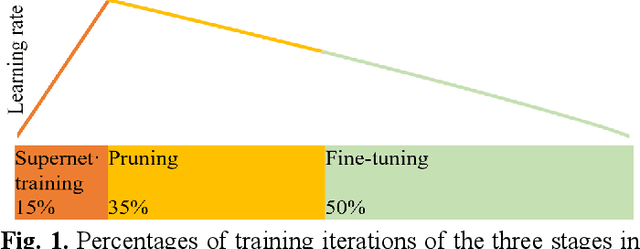
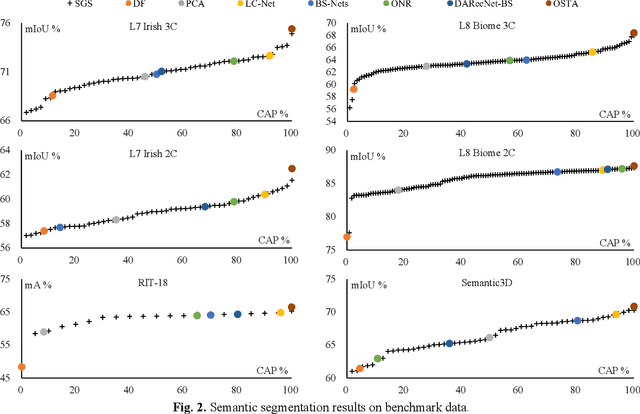

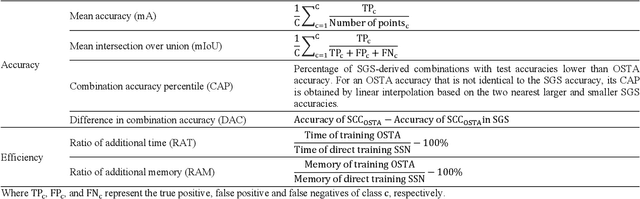
Semantic segmentation of multichannel images is a fundamental task for many applications. Selecting an appropriate channel combination from the original multichannel image can improve the accuracy of semantic segmentation and reduce the cost of data storage, processing and future acquisition. Existing channel selection methods typically use a reasonable selection procedure to determine a desirable channel combination, and then train a semantic segmentation network using that combination. In this study, the concept of pruning from a supernet is used for the first time to integrate the selection of channel combination and the training of a semantic segmentation network. Based on this concept, a One-Shot Task-Adaptive (OSTA) channel selection method is proposed for the semantic segmentation of multichannel images. OSTA has three stages, namely the supernet training stage, the pruning stage and the fine-tuning stage. The outcomes of six groups of experiments (L7Irish3C, L7Irish2C, L8Biome3C, L8Biome2C, RIT-18 and Semantic3D) demonstrated the effectiveness and efficiency of OSTA. OSTA achieved the highest segmentation accuracies in all tests (62.49% (mIoU), 75.40% (mIoU), 68.38% (mIoU), 87.63% (mIoU), 66.53% (mA) and 70.86% (mIoU), respectively). It even exceeded the highest accuracies of exhaustive tests (61.54% (mIoU), 74.91% (mIoU), 67.94% (mIoU), 87.32% (mIoU), 65.32% (mA) and 70.27% (mIoU), respectively), where all possible channel combinations were tested. All of this can be accomplished within a predictable and relatively efficient timeframe, ranging from 101.71% to 298.1% times the time required to train the segmentation network alone. In addition, there were interesting findings that were deemed valuable for several fields.
Enhanced Multi-level Features for Very High Resolution Remote Sensing Scene Classification
May 01, 2023Very high-resolution (VHR) remote sensing (RS) scene classification is a challenging task due to the higher inter-class similarity and intra-class variability problems. Recently, the existing deep learning (DL)-based methods have shown great promise in VHR RS scene classification. However, they still provide an unstable classification performance. To address such a problem, we, in this letter, propose a novel DL-based approach. For this, we devise an enhanced VHR attention module (EAM), followed by the atrous spatial pyramid pooling (ASPP) and global average pooling (GAP). This procedure imparts the enhanced features from the corresponding level. Then, the multi-level feature fusion is performed. Experimental results on two widely-used VHR RS datasets show that the proposed approach yields a competitive and stable/robust classification performance with the least standard deviation of 0.001. Further, the highest overall accuracies on the AID and the NWPU datasets are 95.39% and 93.04%, respectively.
A novel dual skip connection mechanism in U-Nets for building footprint extraction
Mar 16, 2023



The importance of building footprints and their inventory has been recognised as an enabler for multiple societal problems. Extracting urban building footprint is complex and requires semantic segmentation of very high-resolution (VHR) earth observation (EO) images. U-Net is a common deep learning architecture for such segmentation. It has seen several re-incarnation including U-Net++ and U-Net3+ with a focus on multi-scale feature aggregation with re-designed skip connections. However, the exploitation of multi-scale information is still evolving. In this paper, we propose a dual skip connection mechanism (DSCM) for U-Net and a dual full-scale skip connection mechanism (DFSCM) for U-Net3+. The DSCM in U-Net doubles the features in the encoder and passes them to the decoder for precise localisation. Similarly, the DFSCM incorporates increased low-level context information with high-level semantics from feature maps in different scales. The DSCM is further tested in ResUnet and different scales of U-Net. The proposed mechanisms, therefore, produce several novel networks that are evaluated in a benchmark WHU building dataset and a multi-resolution dataset that we develop for the City of Melbourne. The results on the benchmark dataset demonstrate 17.7% and 18.4% gain in F1 score and Intersection over Union (IoU) compared to the state-of-the-art vanilla U-Net3+. In the same experimental setup, DSCM on U-Net and ResUnet provides a gain in five accuracy measures against the original networks. The codes will be available in a GitHub link after peer review.