 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Deep Learning Architectures for Urban Vegetation Points Segmentation
Jun 17, 2023
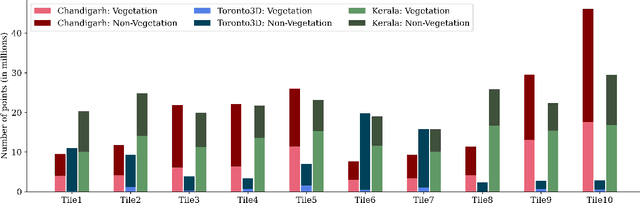
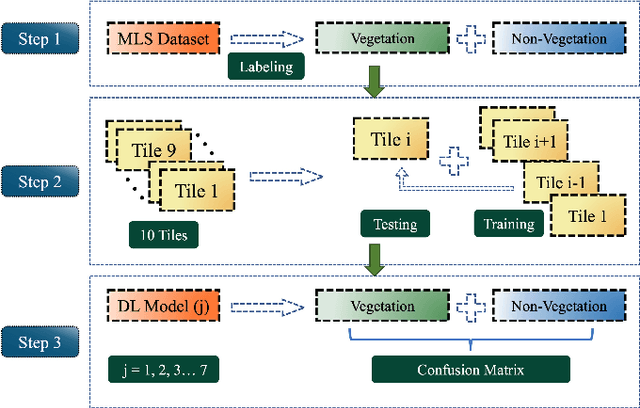
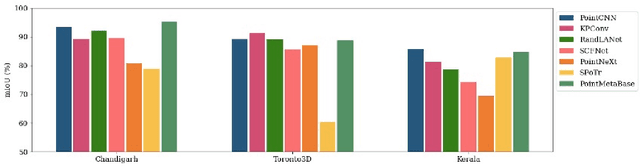
Vegetation is crucial for sustainable and resilient cities providing various ecosystem services and well-being of humans. However, vegetation is under critical stress with rapid urbanization and expanding infrastructure footprints. Consequently, mapping of this vegetation is essential in the urban environment. Recently, deep learning for point cloud semantic segmentation has shown significant progress. Advanced models attempt to obtain state-of-the-art performance on benchmark datasets, comprising multiple classes and representing real world scenarios. However, class specific segmentation with respect to vegetation points has not been explored. Therefore, selection of a deep learning model for vegetation points segmentation is ambiguous. To address this problem, we provide a comprehensive assessment of point-based deep learning models for semantic segmentation of vegetation class. We have selected four representative point-based models, namely PointCNN, KPConv (omni-supervised), RandLANet and SCFNet. These models are investigated on three different datasets, specifically Chandigarh, Toronto3D and Kerala, which are characterized by diverse nature of vegetation, varying scene complexity and changing per-point features. PointCNN achieves the highest mIoU on the Chandigarh (93.32%) and Kerala datasets (85.68%) while KPConv (omni-supervised) provides the highest mIoU on the Toronto3D dataset (91.26%). The paper develops a deeper insight, hitherto not reported, into the working of these models for vegetation segmentation and outlines the ingredients that should be included in a model specifically for vegetation segmentation. This paper is a step towards the development of a novel architecture for vegetation points segmentation.
Translating Place-Related Questions to GeoSPARQL Queries
May 06, 2022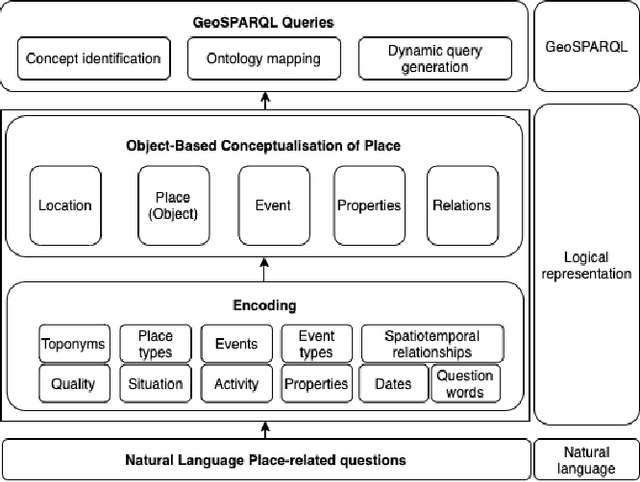
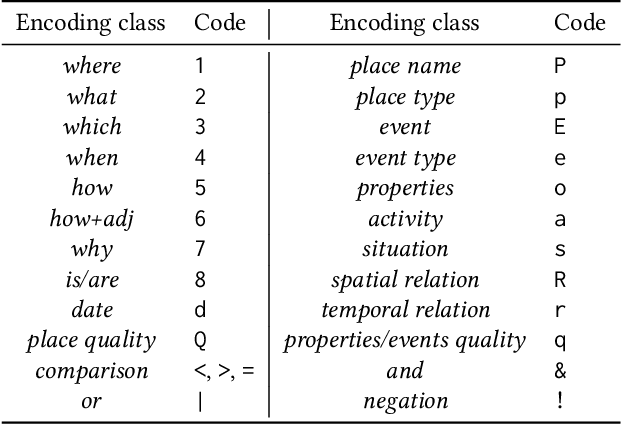
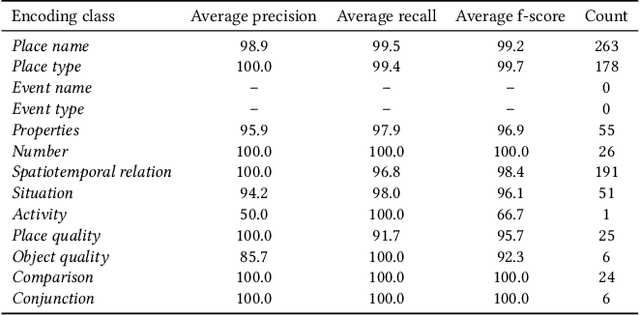
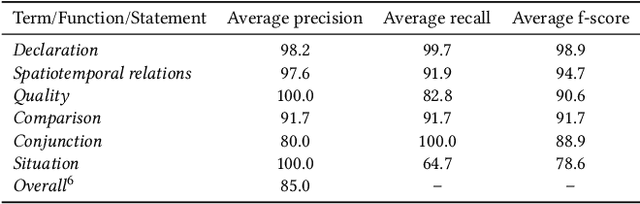
Many place-related questions can only be answered by complex spatial reasoning, a task poorly supported by factoid question retrieval. Such reasoning using combinations of spatial and non-spatial criteria pertinent to place-related questions is increasingly possible on linked data knowledge bases. Yet, to enable question answering based on linked knowledge bases, natural language questions must first be re-formulated as formal queries. Here, we first present an enhanced version of YAGO2geo, the geospatially-enabled variant of the YAGO2 knowledge base, by linking and adding more than one million places from OpenStreetMap data to YAGO2. We then propose a novel approach to translate the place-related questions into logical representations, theoretically grounded in the core concepts of spatial information. Next, we use a dynamic template-based approach to generate fully executable GeoSPARQL queries from the logical representations. We test our approach using the Geospatial Gold Standard dataset and report substantial improvements over existing methods.
Templates of generic geographic information for answering where-questions
Jan 21, 2021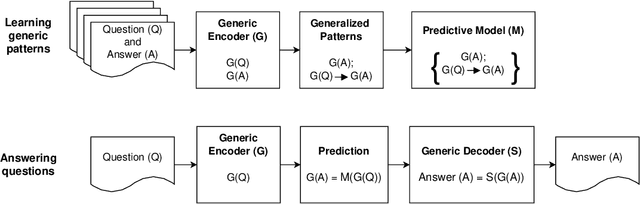
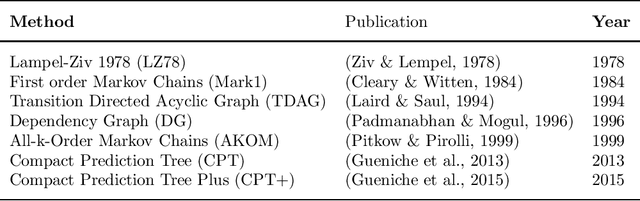

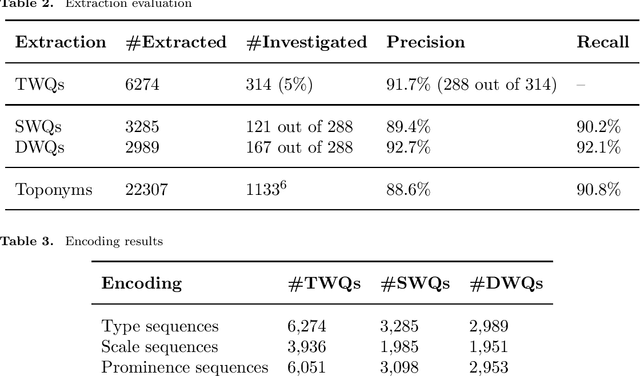
In everyday communication, where-questions are answered by place descriptions. To answer where-questions automatically, computers should be able to generate relevant place descriptions that satisfy inquirers' information needs. Human-generated answers to where-questions constructed based on a few anchor places that characterize the location of inquired places. The challenge for automatically generating such relevant responses stems from selecting relevant anchor places. In this paper, we present templates that allow to characterize the human-generated answers and to imitate their structure. These templates are patterns of generic geographic information derived and encoded from the largest available machine comprehension dataset, MS MARCO v2.1. In our approach, the toponyms in the questions and answers of the dataset are encoded into sequences of generic information. Next, sequence prediction methods are used to model the relation between the generic information in the questions and their answers. Finally, we evaluate the performance of predicting templates for answers to where-questions.
Disambiguating fine-grained place names from descriptions by clustering
Aug 17, 2018

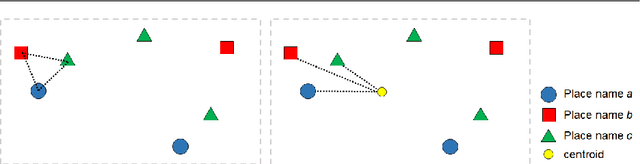
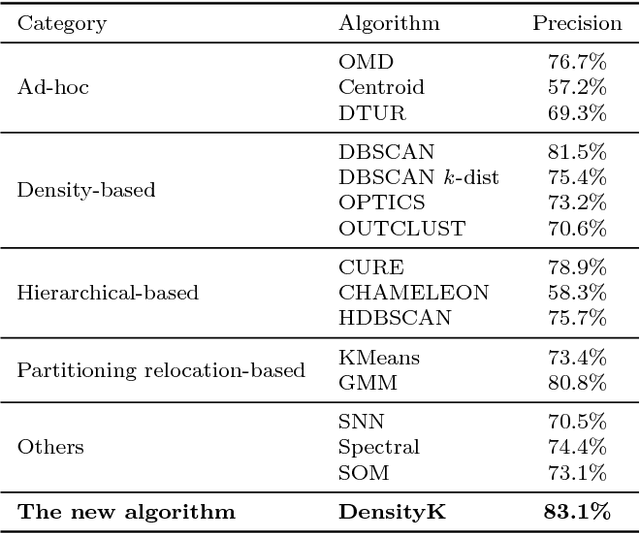
Everyday place descriptions often contain place names of fine-grained features, such as buildings or businesses, that are more difficult to disambiguate than names referring to larger places, for example cities or natural geographic features. Fine-grained places are often significantly more frequent and more similar to each other, and disambiguation heuristics developed for larger places, such as those based on population or containment relationships, are often not applicable in these cases. In this research, we address the disambiguation of fine-grained place names from everyday place descriptions. For this purpose, we evaluate the performance of different existing clustering-based approaches, since clustering approaches require no more knowledge other than the locations of ambiguous place names. We consider not only approaches developed specifically for place name disambiguation, but also clustering algorithms developed for general data mining that could potentially be leveraged. We compare these methods with a novel algorithm, and show that the novel algorithm outperforms the other algorithms in terms of disambiguation precision and distance error over several tested datasets.
Geo-referencing Place from Everyday Natural Language Descriptions
Oct 09, 2017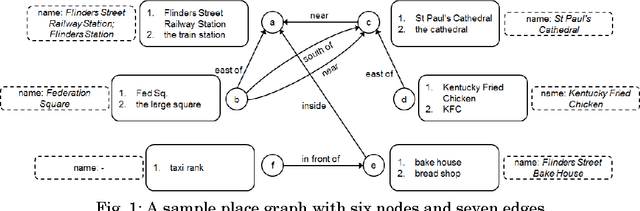
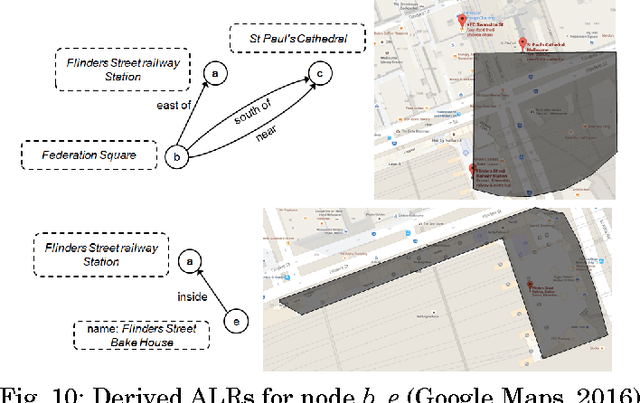
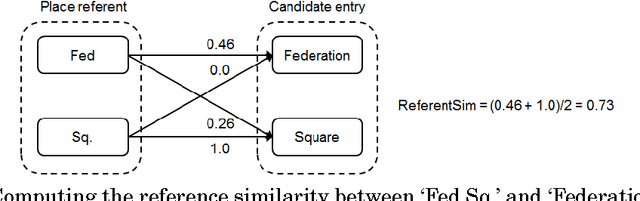
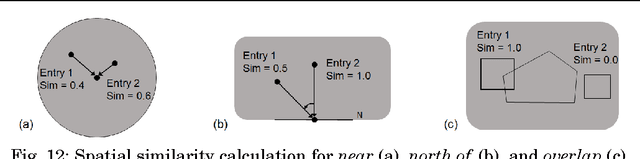
Natural language place descriptions in everyday communication provide a rich source of spatial knowledge about places. An important step to utilize such knowledge in information systems is geo-referencing all the places referred to in these descriptions. Current techniques for geo-referencing places from text documents are using place name recognition and disambiguation; however, place descriptions often contain place references that are not known by gazetteers, or that are expressed in other, more flexible ways. Hence, the approach for geo-referencing presented in this paper starts from a place graph that contains the place references as well as spatial relationships extracted from place descriptions. Spatial relationships are used to constrain the locations of places and allow the later best-matching process for geo-referencing. The novel geo-referencing process results in higher precision and recall compared to state-of-art toponym resolution approaches on several tested place description datasets.