 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaLiTy and LADS: A Unified Framework and Dataset Suite for LiDAR Adaptation Across Sensors and Adverse Weather Conditions
Apr 11, 2026Reliable LiDAR perception requires robustness across sensors, environments, and adverse weather. However, existing datasets rarely provide physically consistent observations of the same scene under varying sensor configurations and weather conditions, limiting systematic analysis of domain shifts. This work presents ReaLiTy, a unified physics-informed framework that transforms LiDAR data to match target sensor specifications and weather conditions. The framework integrates physically grounded cues with a learning-based module to generate realistic intensity patterns, while a physics-based weather model introduces consistent geometric and radiometric degradations. Building on this framework, we introduce the LiDAR Adaptation Dataset Suite (LADS), a collection of physically consistent, transformation-ready point clouds with one-to-one correspondence to original datasets. Experiments demonstrate improved cross-domain consistency and realistic weather effects. ReaLiTy and LADS provide a reproducible foundation for studying LiDAR adaptation and simulation-driven perception in intelligent transportation systems.
Simulating Realistic LiDAR Data Under Adverse Weather for Autonomous Vehicles: A Physics-Informed Learning Approach
Apr 01, 2026Accurate LiDAR simulation is crucial for autonomous driving, especially under adverse weather conditions. Existing methods struggle to capture the complex interactions between LiDAR signals and atmospheric phenomena, leading to unrealistic representations. This paper presents a physics-informed learning framework (PICWGAN) for generating realistic LiDAR data under adverse weather conditions. By integrating physicsdriven constraints for modeling signal attenuation and geometryconsistent degradations into a physics-informed learning pipeline, the proposed method reduces the sim-to-real gap. Evaluations on real-world datasets (CADC for snow, Boreas for rain) and the VoxelScape dataset show that our approach closely mimics realworld intensity patterns. Quantitative metrics, including MSE, SSIM, KL divergence, and Wasserstein distance, demonstrate statistically consistent intensity distributions. Additionally, models trained on data enhanced by our framework outperform baselines in downstream 3D object detection, achieving performance comparable to models trained on real-world data. These results highlight the effectiveness of the proposed approach in improving the realism of LiDAR data and enabling robust perception under adverse weather conditions.
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation
Apr 24, 2024



Autonomous vehicles (AVs) heavily rely on LiDAR perception for environment understanding and navigation. LiDAR intensity provides valuable information about the reflected laser signals and plays a crucial role in enhancing the perception capabilities of AVs. However, accurately simulating LiDAR intensity remains a challenge due to the unavailability of material properties of the objects in the environment, and complex interactions between the laser beam and the environment. The proposed method aims to improve the accuracy of intensity simulation by incorporating physics-based modalities within the deep learning framework. One of the key entities that captures the interaction between the laser beam and the objects is the angle of incidence. In this work we demonstrate that the addition of the LiDAR incidence angle as a separate input to the deep neural networks significantly enhances the results. We present a comparative study between two prominent deep learning architectures: U-NET a Convolutional Neural Network (CNN), and Pix2Pix a Generative Adversarial Network (GAN). We implemented these two architectures for the intensity prediction task and used SemanticKITTI and VoxelScape datasets for experiments. The comparative analysis reveals that both architectures benefit from the incidence angle as an additional input. Moreover, the Pix2Pix architecture outperforms U-NET, especially when the incidence angle is incorporated.
pCTFusion: Point Convolution-Transformer Fusion with Semantic Aware Loss for Outdoor LiDAR Point Cloud Segmentation
Jul 31, 2023



LiDAR-generated point clouds are crucial for perceiving outdoor environments. The segmentation of point clouds is also essential for many applications. Previous research has focused on using self-attention and convolution (local attention) mechanisms individually in semantic segmentation architectures. However, there is limited work on combining the learned representations of these attention mechanisms to improve performance. Additionally, existing research that combines convolution with self-attention relies on global attention, which is not practical for processing large point clouds. To address these challenges, this study proposes a new architecture, pCTFusion, which combines kernel-based convolutions and self-attention mechanisms for better feature learning and capturing local and global dependencies in segmentation. The proposed architecture employs two types of self-attention mechanisms, local and global, based on the hierarchical positions of the encoder blocks. Furthermore, the existing loss functions do not consider the semantic and position-wise importance of the points, resulting in reduced accuracy, particularly at sharp class boundaries. To overcome this, the study models a novel attention-based loss function called Pointwise Geometric Anisotropy (PGA), which assigns weights based on the semantic distribution of points in a neighborhood. The proposed architecture is evaluated on SemanticKITTI outdoor dataset and showed a 5-7% improvement in performance compared to the state-of-the-art architectures. The results are particularly encouraging for minor classes, often misclassified due to class imbalance, lack of space, and neighbor-aware feature encoding. These developed methods can be leveraged for the segmentation of complex datasets and can drive real-world applications of LiDAR point cloud.
Benchmarking Deep Learning Architectures for Urban Vegetation Points Segmentation
Jun 17, 2023
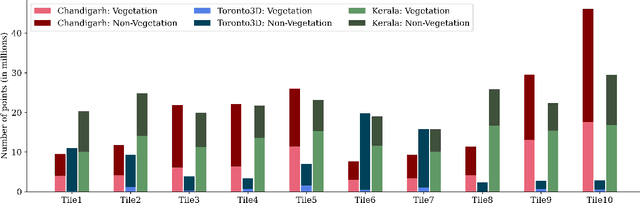
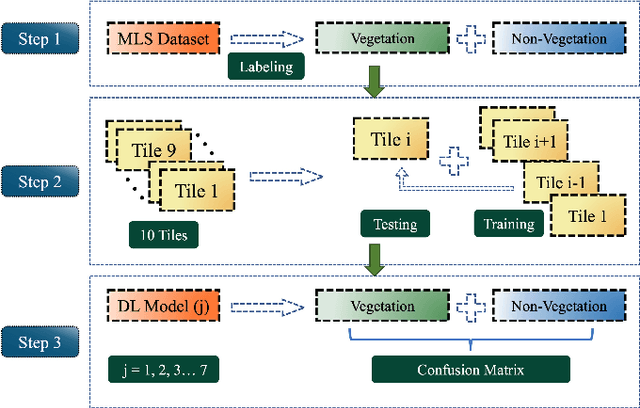
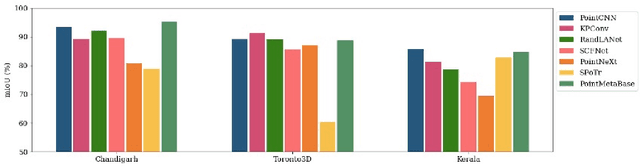
Vegetation is crucial for sustainable and resilient cities providing various ecosystem services and well-being of humans. However, vegetation is under critical stress with rapid urbanization and expanding infrastructure footprints. Consequently, mapping of this vegetation is essential in the urban environment. Recently, deep learning for point cloud semantic segmentation has shown significant progress. Advanced models attempt to obtain state-of-the-art performance on benchmark datasets, comprising multiple classes and representing real world scenarios. However, class specific segmentation with respect to vegetation points has not been explored. Therefore, selection of a deep learning model for vegetation points segmentation is ambiguous. To address this problem, we provide a comprehensive assessment of point-based deep learning models for semantic segmentation of vegetation class. We have selected four representative point-based models, namely PointCNN, KPConv (omni-supervised), RandLANet and SCFNet. These models are investigated on three different datasets, specifically Chandigarh, Toronto3D and Kerala, which are characterized by diverse nature of vegetation, varying scene complexity and changing per-point features. PointCNN achieves the highest mIoU on the Chandigarh (93.32%) and Kerala datasets (85.68%) while KPConv (omni-supervised) provides the highest mIoU on the Toronto3D dataset (91.26%). The paper develops a deeper insight, hitherto not reported, into the working of these models for vegetation segmentation and outlines the ingredients that should be included in a model specifically for vegetation segmentation. This paper is a step towards the development of a novel architecture for vegetation points segmentation.