 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguating fine-grained place names from descriptions by clustering
Paper and Code
Aug 17, 2018

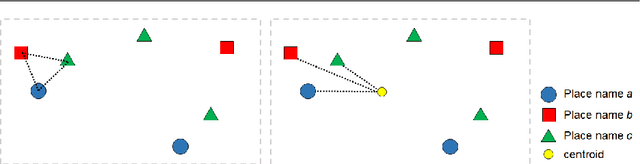
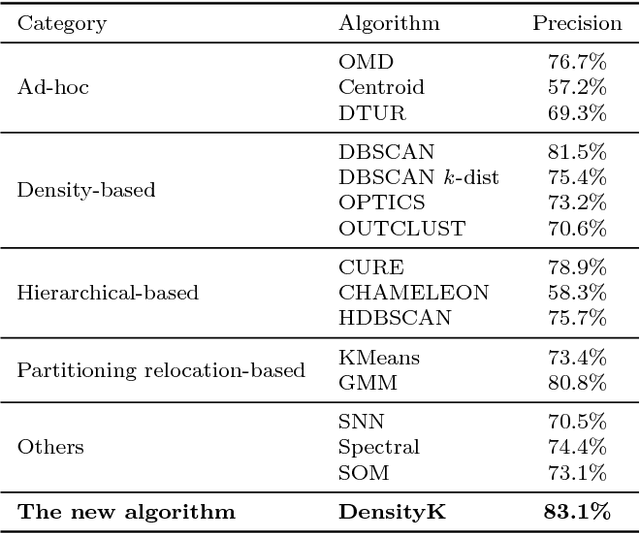
Everyday place descriptions often contain place names of fine-grained features, such as buildings or businesses, that are more difficult to disambiguate than names referring to larger places, for example cities or natural geographic features. Fine-grained places are often significantly more frequent and more similar to each other, and disambiguation heuristics developed for larger places, such as those based on population or containment relationships, are often not applicable in these cases. In this research, we address the disambiguation of fine-grained place names from everyday place descriptions. For this purpose, we evaluate the performance of different existing clustering-based approaches, since clustering approaches require no more knowledge other than the locations of ambiguous place names. We consider not only approaches developed specifically for place name disambiguation, but also clustering algorithms developed for general data mining that could potentially be leveraged. We compare these methods with a novel algorithm, and show that the novel algorithm outperforms the other algorithms in terms of disambiguation precision and distance error over several tested datasets.