 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Estimation of Tree Volume and Aboveground Biomass Using Deep Regression with Synthetic Lidar Data
Mar 04, 2026Accurate estimation of forest biomass is crucial for monitoring carbon sequestration and informing climate change mitigation strategies. Existing methods often rely on allometric models, which estimate individual tree biomass by relating it to measurable biophysical parameters, e.g., trunk diameter and height. This indirect approach is limited in accuracy due to measurement uncertainties and the inherently approximate nature of allometric equations, which may not fully account for the variability in tree characteristics and forest conditions. This study proposes a direct approach that leverages synthetic point cloud data to train a deep regression network, which is then applied to real point clouds for plot-level wood volume and aboveground biomass (AGB) estimation. We created synthetic 3D forest plots with ground truth volume, which were then converted into point cloud data using a lidar simulator. These point clouds were subsequently used to train deep regression networks based on PointNet, PointNet++, DGCNN, and PointConv. When applied to synthetic data, the deep regression networks achieved mean absolute percentage error (MAPE) values ranging from 1.69% to 8.11%. The trained networks were then applied to real lidar data to estimate volume and AGB. When compared against field measurements, our direct approach showed discrepancies of 2% to 20%. In contrast, indirect approaches based on individual tree segmentation followed by allometric conversion, as well as FullCAM, exhibited substantially large underestimation, with discrepancies ranging from 27% to 85%. Our results highlight the potential of integrating synthetic data with deep learning for efficient and scalable forest carbon estimation at plot level.
Learning Geometric Invariant Features for Classification of Vector Polygons with Graph Message-passing Neural Network
Jul 05, 2024



Geometric shape classification of vector polygons remains a non-trivial learning task in spatial analysis. Previous studies mainly focus on devising deep learning approaches for representation learning of rasterized vector polygons, whereas the study of discrete representations of polygons and subsequent deep learning approaches have not been fully investigated. In this study, we investigate a graph representation of vector polygons and propose a novel graph message-passing neural network (PolyMP) to learn the geometric-invariant features for shape classification of polygons. Through extensive experiments, we show that the graph representation of polygons combined with a permutation-invariant graph message-passing neural network achieves highly robust performances on benchmark datasets (i.e., synthetic glyph and real-world building footprint datasets) as compared to baseline methods. We demonstrate that the proposed graph-based PolyMP network enables the learning of expressive geometric features invariant to geometric transformations of polygons (i.e., translation, rotation, scaling and shearing) and is robust to trivial vertex removals of polygons. We further show the strong generalizability of PolyMP, which enables generalizing the learned geometric features from the synthetic glyph polygons to the real-world building footprints.
LMSeg: A deep graph message-passing network for efficient and accurate semantic segmentation of large-scale 3D landscape meshes
Jul 05, 2024



Semantic segmentation of large-scale 3D landscape meshes is pivotal for various geospatial applications, including spatial analysis, automatic mapping and localization of target objects, and urban planning and development. This requires an efficient and accurate 3D perception system to understand and analyze real-world environments. However, traditional mesh segmentation methods face challenges in accurately segmenting small objects and maintaining computational efficiency due to the complexity and large size of 3D landscape mesh datasets. This paper presents an end-to-end deep graph message-passing network, LMSeg, designed to efficiently and accurately perform semantic segmentation on large-scale 3D landscape meshes. The proposed approach takes the barycentric dual graph of meshes as inputs and applies deep message-passing neural networks to hierarchically capture the geometric and spatial features from the barycentric graph structures and learn intricate semantic information from textured meshes. The hierarchical and local pooling of the barycentric graph, along with the effective geometry aggregation modules of LMSeg, enable fast inference and accurate segmentation of small-sized and irregular mesh objects in various complex landscapes. Extensive experiments on two benchmark datasets (natural and urban landscapes) demonstrate that LMSeg significantly outperforms existing learning-based segmentation methods in terms of object segmentation accuracy and computational efficiency. Furthermore, our method exhibits strong generalization capabilities across diverse landscapes and demonstrates robust resilience against varying mesh densities and landscape topologies.
Location Aware Modular Biencoder for Tourism Question Answering
Jan 04, 2024Answering real-world tourism questions that seek Point-of-Interest (POI) recommendations is challenging, as it requires both spatial and non-spatial reasoning, over a large candidate pool. The traditional method of encoding each pair of question and POI becomes inefficient when the number of candidates increases, making it infeasible for real-world applications. To overcome this, we propose treating the QA task as a dense vector retrieval problem, where we encode questions and POIs separately and retrieve the most relevant POIs for a question by utilizing embedding space similarity. We use pretrained language models (PLMs) to encode textual information, and train a location encoder to capture spatial information of POIs. Experiments on a real-world tourism QA dataset demonstrate that our approach is effective, efficient, and outperforms previous methods across all metrics. Enabled by the dense retrieval architecture, we further build a global evaluation baseline, expanding the search space by 20 times compared to previous work. We also explore several factors that impact on the model's performance through follow-up experiments. Our code and model are publicly available at https://github.com/haonan-li/LAMB.
Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities
Feb 17, 2023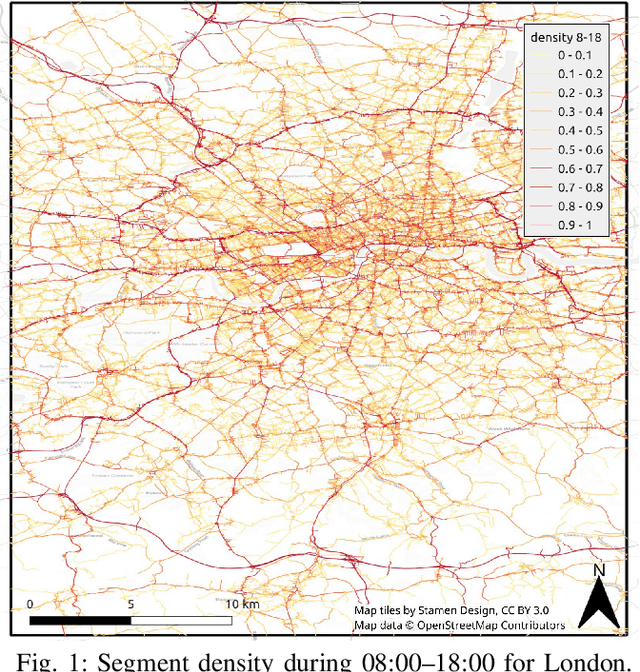
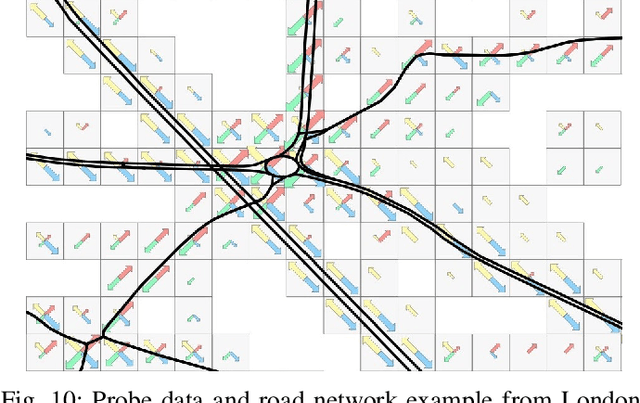
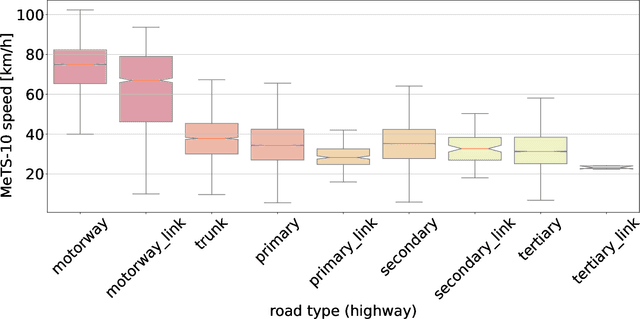
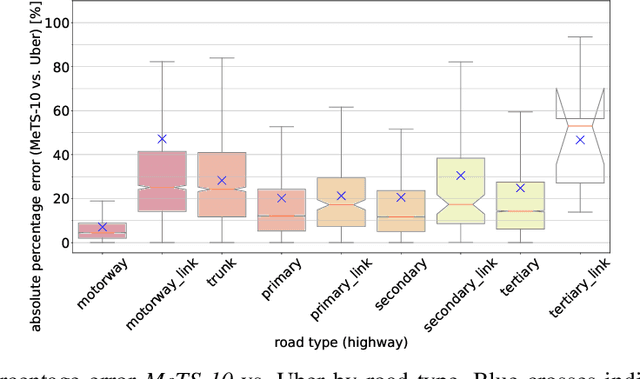
Traffic analysis is crucial for urban operations and planning, while the availability of dense urban traffic data beyond loop detectors is still scarce. We present a large-scale floating vehicle dataset of per-street segment traffic information, Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities (MeTS-10), available for 10 global cities with a 15-minute resolution for collection periods ranging between 108 and 361 days in 2019-2021 and covering more than 1500 square kilometers per metropolitan area. MeTS-10 features traffic speed information at all street levels from main arterials to local streets for Antwerp, Bangkok, Barcelona, Berlin, Chicago, Istanbul, London, Madrid, Melbourne and Moscow. The dataset leverages the industrial-scale floating vehicle Traffic4cast data with speeds and vehicle counts provided in a privacy-preserving spatio-temporal aggregation. We detail the efficient matching approach mapping the data to the OpenStreetMap road graph. We evaluate the dataset by comparing it with publicly available stationary vehicle detector data (for Berlin, London, and Madrid) and the Uber traffic speed dataset (for Barcelona, Berlin, and London). The comparison highlights the differences across datasets in spatio-temporal coverage and variations in the reported traffic caused by the binning method. MeTS-10 enables novel, city-wide analysis of mobility and traffic patterns for ten major world cities, overcoming current limitations of spatially sparse vehicle detector data. The large spatial and temporal coverage offers an opportunity for joining the MeTS-10 with other datasets, such as traffic surveys in traffic planning studies or vehicle detector data in traffic control settings.
Translating Place-Related Questions to GeoSPARQL Queries
May 06, 2022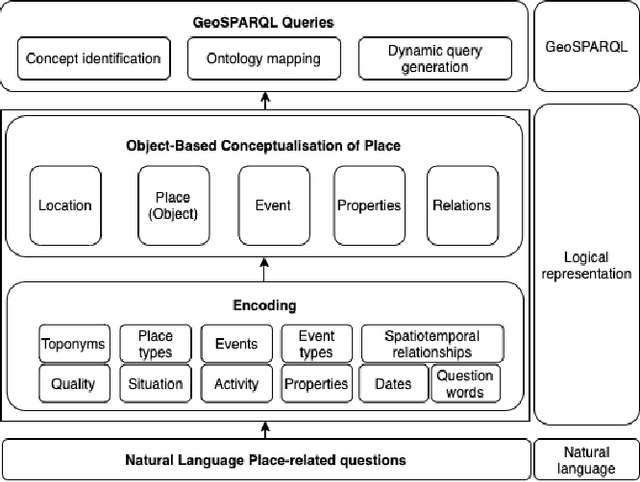
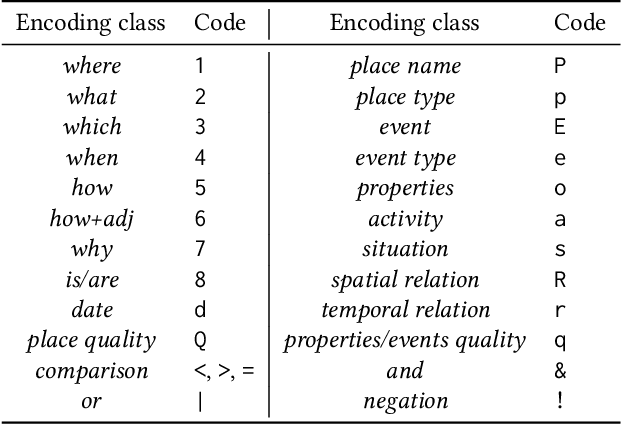
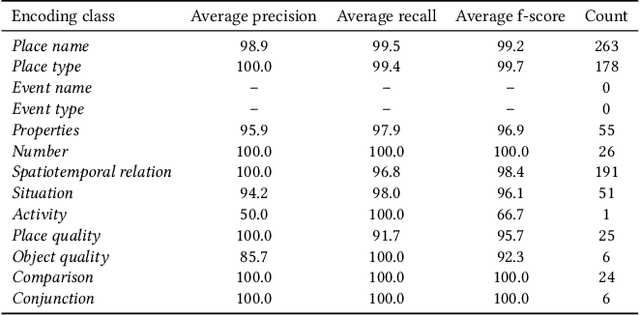
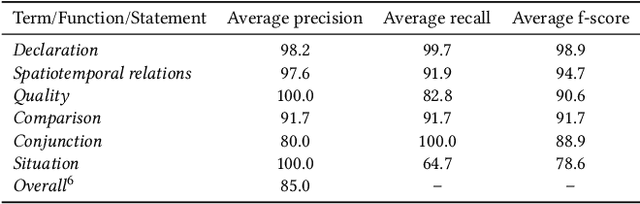
Many place-related questions can only be answered by complex spatial reasoning, a task poorly supported by factoid question retrieval. Such reasoning using combinations of spatial and non-spatial criteria pertinent to place-related questions is increasingly possible on linked data knowledge bases. Yet, to enable question answering based on linked knowledge bases, natural language questions must first be re-formulated as formal queries. Here, we first present an enhanced version of YAGO2geo, the geospatially-enabled variant of the YAGO2 knowledge base, by linking and adding more than one million places from OpenStreetMap data to YAGO2. We then propose a novel approach to translate the place-related questions into logical representations, theoretically grounded in the core concepts of spatial information. Next, we use a dynamic template-based approach to generate fully executable GeoSPARQL queries from the logical representations. We test our approach using the Geospatial Gold Standard dataset and report substantial improvements over existing methods.
Templates of generic geographic information for answering where-questions
Jan 21, 2021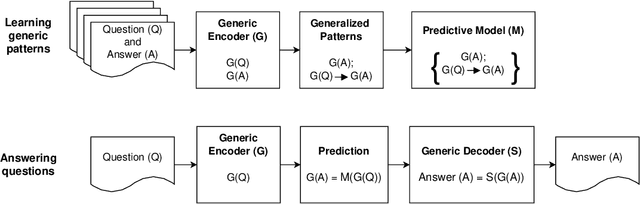

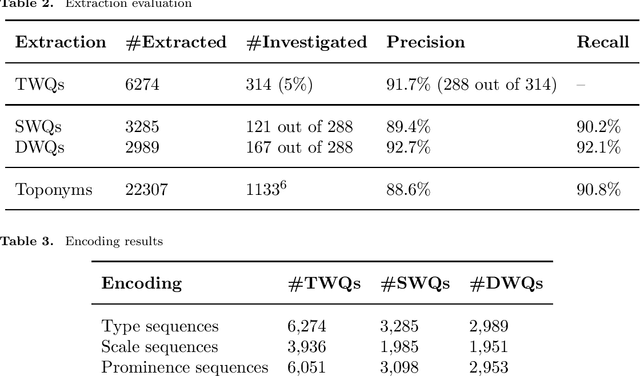
In everyday communication, where-questions are answered by place descriptions. To answer where-questions automatically, computers should be able to generate relevant place descriptions that satisfy inquirers' information needs. Human-generated answers to where-questions constructed based on a few anchor places that characterize the location of inquired places. The challenge for automatically generating such relevant responses stems from selecting relevant anchor places. In this paper, we present templates that allow to characterize the human-generated answers and to imitate their structure. These templates are patterns of generic geographic information derived and encoded from the largest available machine comprehension dataset, MS MARCO v2.1. In our approach, the toponyms in the questions and answers of the dataset are encoded into sequences of generic information. Next, sequence prediction methods are used to model the relation between the generic information in the questions and their answers. Finally, we evaluate the performance of predicting templates for answers to where-questions.
Target Word Masking for Location Metonymy Resolution
Oct 30, 2020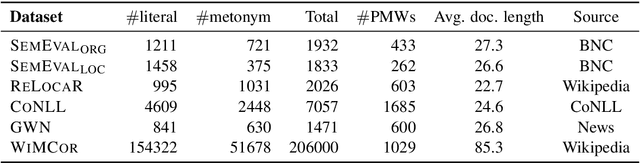
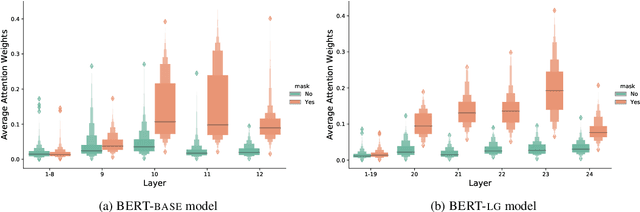
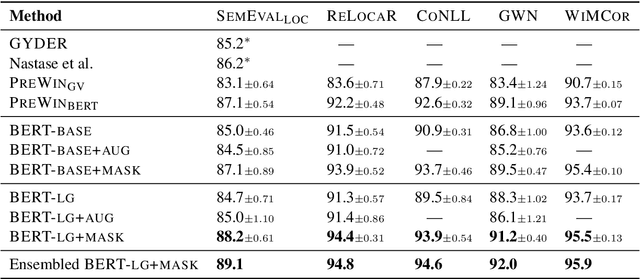
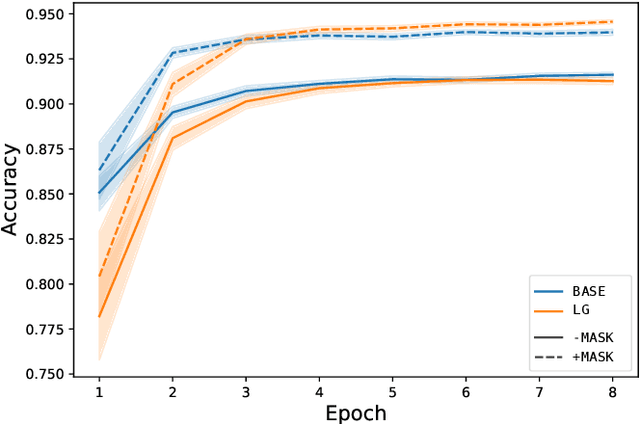
Existing metonymy resolution approaches rely on features extracted from external resources like dictionaries and hand-crafted lexical resources. In this paper, we propose an end-to-end word-level classification approach based only on BERT, without dependencies on taggers, parsers, curated dictionaries of place names, or other external resources. We show that our approach achieves the state-of-the-art on 5 datasets, surpassing conventional BERT models and benchmarks by a large margin. We also show that our approach generalises well to unseen data.
Joint Modelling of Cyber Activities and Physical Context to Improve Prediction of Visitor Behaviors
Aug 26, 2020
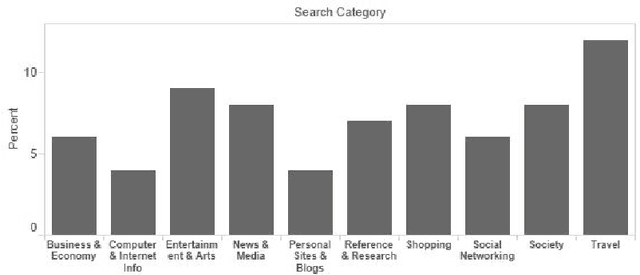
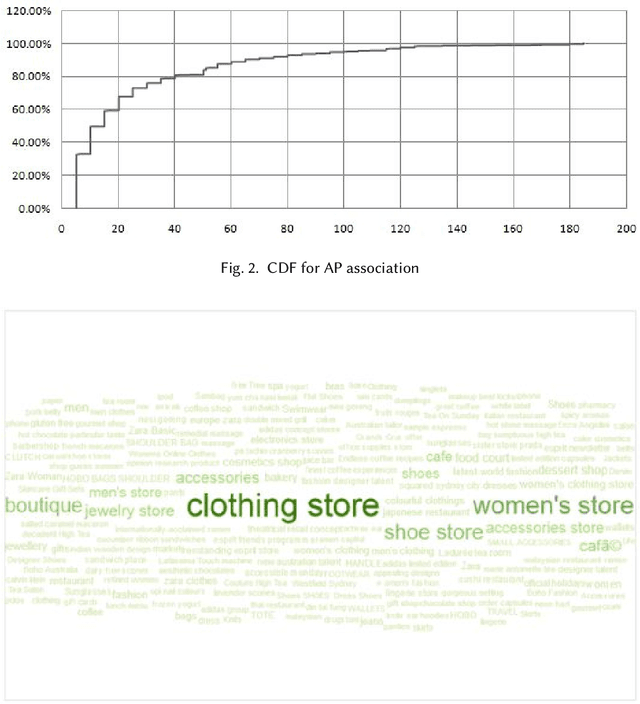

This paper investigates the Cyber-Physical behavior of users in a large indoor shopping mall by leveraging anonymized (opt in) Wi-Fi association and browsing logs recorded by the mall operators. Our analysis shows that many users exhibit a high correlation between their cyber activities and their physical context. To find this correlation, we propose a mechanism to semantically label a physical space with rich categorical information from DBPedia concepts and compute a contextual similarity that represents a user's activities with the mall context. We demonstrate the application of cyber-physical contextual similarity in two situations: user visit intent classification and future location prediction. The experimental results demonstrate that exploitation of contextual similarity significantly improves the accuracy of such applications.
* Accepted in ACM Transactions on Sensor Networks, 2020
Detecting Unsigned Physical Road Incidents from Driver-View Images
Apr 24, 2020
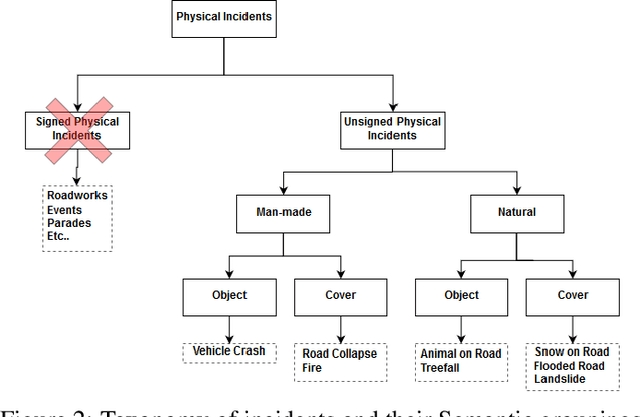
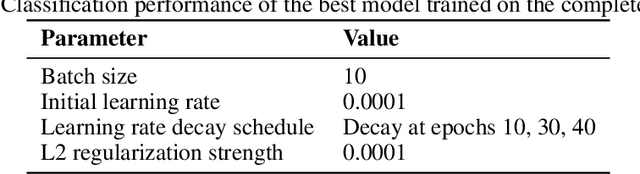
Safety on roads is of uttermost importance, especially in the context of autonomous vehicles. A critical need is to detect and communicate disruptive incidents early and effectively. In this paper we propose a system based on an off-the-shelf deep neural network architecture that is able to detect and recognize types of unsigned (non-placarded, such as traffic signs), physical (visible in images) road incidents. We develop a taxonomy for unsigned physical incidents to provide a means of organizing and grouping related incidents. After selecting eight target types of incidents, we collect a dataset of twelve thousand images gathered from publicly-available web sources. We subsequently fine-tune a convolutional neural network to recognize the eight types of road incidents. The proposed model is able to recognize incidents with a high level of accuracy (higher than 90%). We further show that while our system generalizes well across spatial context by training a classifier on geostratified data in the United Kingdom (with an accuracy of over 90%), the translation to visually less similar environments requires spatially distributed data collection. Note: this is a pre-print version of work accepted in IEEE Transactions on Intelligent Vehicles (T-IV;in press). The paper is currently in production, and the DOI link will be added soon.