 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable User Simulation for Search and Recommendation Systems
Jun 12, 2026Large-language-model (LLM) based user simulation is increasingly adopted for evaluating search engines, recommender systems, and retrieval-augmented generation pipelines, yet most simulators remain opaque: it is difficult to determine why a simulated user made a particular choice or whether that choice is consistent with the intended user profile. Compounding this, recent research shows that LLMs can produce biased or discriminatory responses depending on user background characteristics such as language, education level, and cultural context, raising concerns about the equitable treatment of minority and disadvantaged groups. This half-day, in-person tutorial introduces a proposed design-and-audit framework that treats a user simulator as a verifiable engineering artefact composed of seven auditable components - structured Persona, task-aware Contract, matched human-vs-agent Execution, auditable Trace, persona-aligned Verification, structured Feedback, and a Refinement loop that updates personas and contracts. Through two hands-on mini-labs on recommendation-list evaluation and search-query formulation, participants will inspect simulator behaviour end-to-end, distinguish diagnostic discrepancy analysis from statistical validation, and apply checks for fidelity, credibility, and demographic bias. The tutorial targets information retrieval and recommender systems researchers and practitioners interested in user behaviour simulation and responsible AI.
* Presented as a half-day tutorial at SIGIR 2026, 4 pages
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thought
Jan 13, 2026Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
Addressing Mark Imbalance in Integration-free Neural Marked Temporal Point Processes
Oct 23, 2025Marked Temporal Point Process (MTPP) has been well studied to model the event distribution in marked event streams, which can be used to predict the mark and arrival time of the next event. However, existing studies overlook that the distribution of event marks is highly imbalanced in many real-world applications, with some marks being frequent but others rare. The imbalance poses a significant challenge to the performance of the next event prediction, especially for events of rare marks. To address this issue, we propose a thresholding method, which learns thresholds to tune the mark probability normalized by the mark's prior probability to optimize mark prediction, rather than predicting the mark directly based on the mark probability as in existing studies. In conjunction with this method, we predict the mark first and then the time. In particular, we develop a novel neural MTPP model to support effective time sampling and estimation of mark probability without computationally expensive numerical improper integration. Extensive experiments on real-world datasets demonstrate the superior performance of our solution against various baselines for the next event mark and time prediction. The code is available at https://github.com/undes1red/IFNMTPP.
Rehearsal-free and Task-free Online Continual Learning With Contrastive Prompt
Oct 01, 2025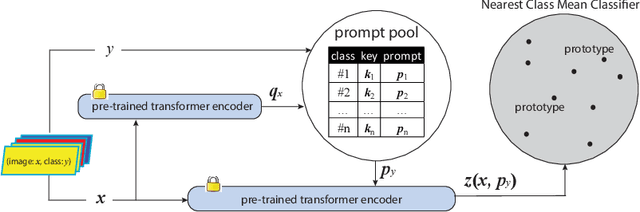
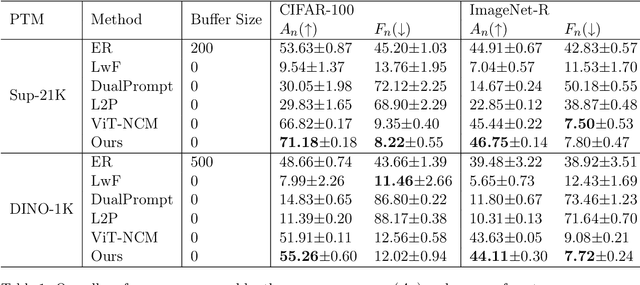
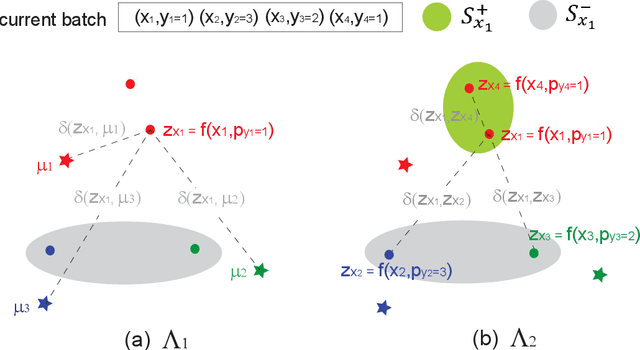

The main challenge of continual learning is \textit{catastrophic forgetting}. Because of processing data in one pass, online continual learning (OCL) is one of the most difficult continual learning scenarios. To address catastrophic forgetting in OCL, some existing studies use a rehearsal buffer to store samples and replay them in the later learning process, other studies do not store samples but assume a sequence of learning tasks so that the task identities can be explored. However, storing samples may raise data security or privacy concerns and it is not always possible to identify the boundaries between learning tasks in one pass of data processing. It motivates us to investigate rehearsal-free and task-free OCL (F2OCL). By integrating prompt learning with an NCM classifier, this study has effectively tackled catastrophic forgetting without storing samples and without usage of task boundaries or identities. The extensive experimental results on two benchmarks have demonstrated the effectiveness of the proposed method.
Unbiased Reasoning for Knowledge-Intensive Tasks in Large Language Models via Conditional Front-Door Adjustment
Aug 23, 2025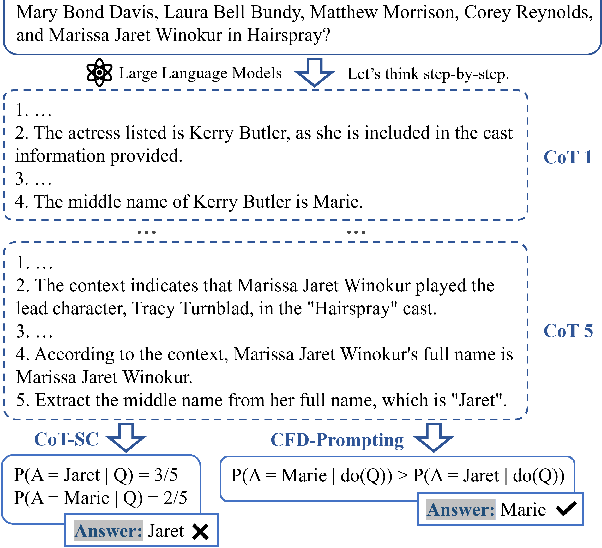
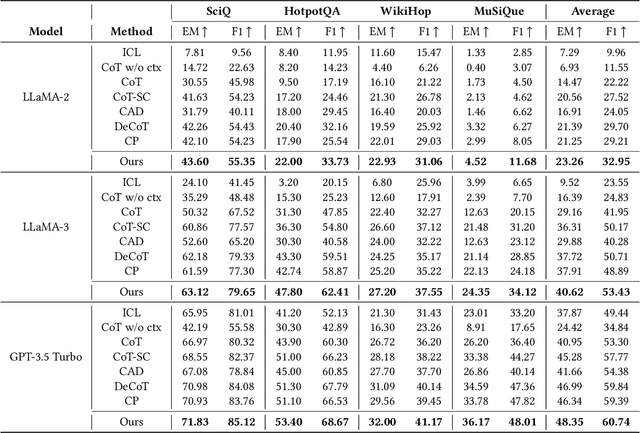
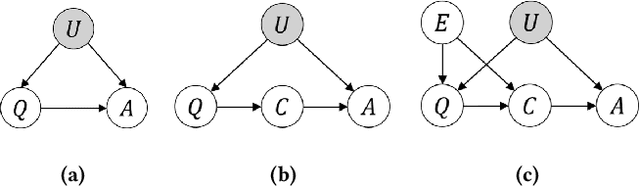
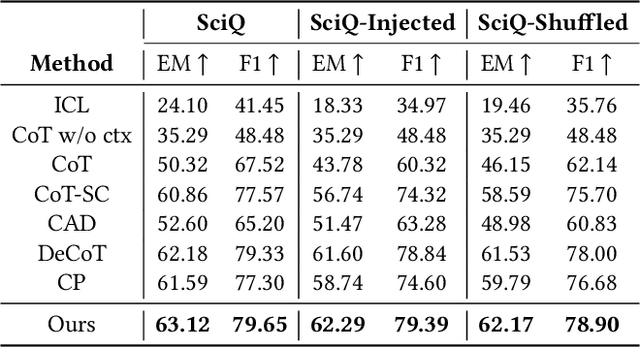
Large Language Models (LLMs) have shown impressive capabilities in natural language processing but still struggle to perform well on knowledge-intensive tasks that require deep reasoning and the integration of external knowledge. Although methods such as Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) have been proposed to enhance LLMs with external knowledge, they still suffer from internal bias in LLMs, which often leads to incorrect answers. In this paper, we propose a novel causal prompting framework, Conditional Front-Door Prompting (CFD-Prompting), which enables the unbiased estimation of the causal effect between the query and the answer, conditional on external knowledge, while mitigating internal bias. By constructing counterfactual external knowledge, our framework simulates how the query behaves under varying contexts, addressing the challenge that the query is fixed and is not amenable to direct causal intervention. Compared to the standard front-door adjustment, the conditional variant operates under weaker assumptions, enhancing both robustness and generalisability of the reasoning process. Extensive experiments across multiple LLMs and benchmark datasets demonstrate that CFD-Prompting significantly outperforms existing baselines in both accuracy and robustness.
PUB: An LLM-Enhanced Personality-Driven User Behaviour Simulator for Recommender System Evaluation
Jun 05, 2025Traditional offline evaluation methods for recommender systems struggle to capture the complexity of modern platforms due to sparse behavioural signals, noisy data, and limited modelling of user personality traits. While simulation frameworks can generate synthetic data to address these gaps, existing methods fail to replicate behavioural diversity, limiting their effectiveness. To overcome these challenges, we propose the Personality-driven User Behaviour Simulator (PUB), an LLM-based simulation framework that integrates the Big Five personality traits to model personalised user behaviour. PUB dynamically infers user personality from behavioural logs (e.g., ratings, reviews) and item metadata, then generates synthetic interactions that preserve statistical fidelity to real-world data. Experiments on the Amazon review datasets show that logs generated by PUB closely align with real user behaviour and reveal meaningful associations between personality traits and recommendation outcomes. These results highlight the potential of the personality-driven simulator to advance recommender system evaluation, offering scalable, controllable, high-fidelity alternatives to resource-intensive real-world experiments.
Metamorphic Evaluation of ChatGPT as a Recommender System
Nov 18, 2024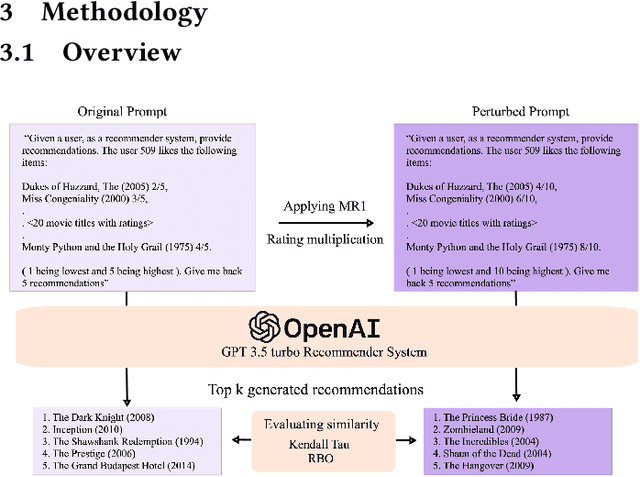

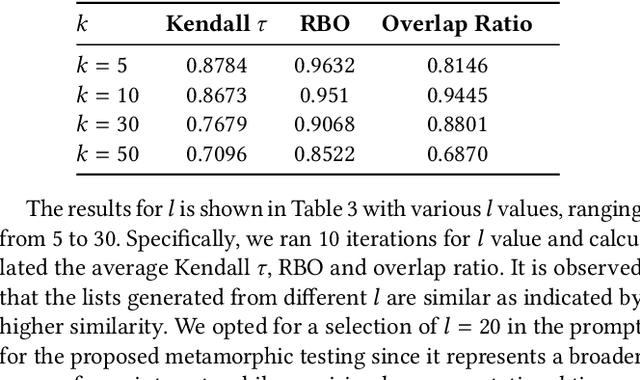
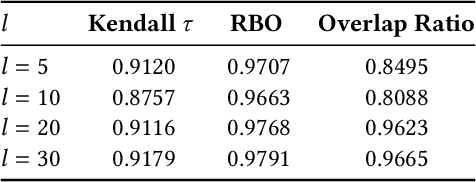
With the rise of Large Language Models (LLMs) such as ChatGPT, researchers have been working on how to utilize the LLMs for better recommendations. However, although LLMs exhibit black-box and probabilistic characteristics (meaning their internal working is not visible), the evaluation framework used for assessing these LLM-based recommender systems (RS) are the same as those used for traditional recommender systems. To address this gap, we introduce the metamorphic testing for the evaluation of GPT-based RS. This testing technique involves defining of metamorphic relations (MRs) between the inputs and checking if the relationship has been satisfied in the outputs. Specifically, we examined the MRs from both RS and LLMs perspectives, including rating multiplication/shifting in RS and adding spaces/randomness in the LLMs prompt via prompt perturbation. Similarity metrics (e.g. Kendall tau and Ranking Biased Overlap(RBO)) are deployed to measure whether the relationship has been satisfied in the outputs of MRs. The experiment results on MovieLens dataset with GPT3.5 show that lower similarity are obtained in terms of Kendall $\tau$ and RBO, which concludes that there is a need of a comprehensive evaluation of the LLM-based RS in addition to the existing evaluation metrics used for traditional recommender systems.
ODEStream: A Buffer-Free Online Learning Framework with ODE-based Adaptor for Streaming Time Series Forecasting
Nov 11, 2024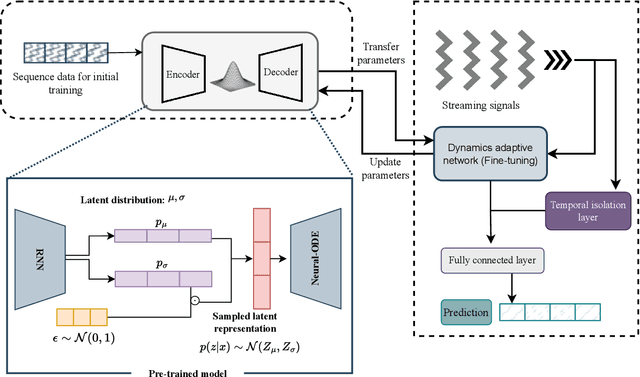

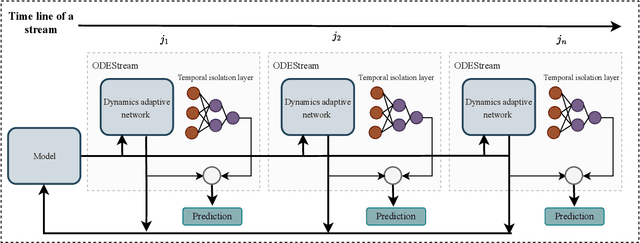
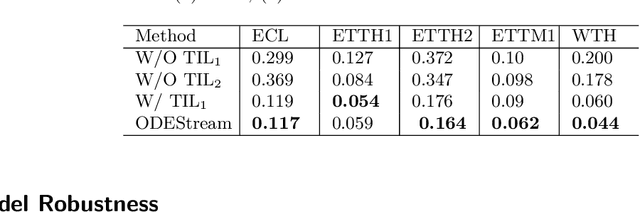
Addressing the challenges of irregularity and concept drift in streaming time series is crucial in real-world predictive modelling. Previous studies in time series continual learning often propose models that require buffering of long sequences, potentially restricting the responsiveness of the inference system. Moreover, these models are typically designed for regularly sampled data, an unrealistic assumption in real-world scenarios. This paper introduces ODEStream, a novel buffer-free continual learning framework that incorporates a temporal isolation layer that integrates temporal dependencies within the data. Simultaneously, it leverages the capability of neural ordinary differential equations to process irregular sequences and generate a continuous data representation, enabling seamless adaptation to changing dynamics in a data streaming scenario. Our approach focuses on learning how the dynamics and distribution of historical data change with time, facilitating the direct processing of streaming sequences. Evaluations on benchmark real-world datasets demonstrate that ODEStream outperforms the state-of-the-art online learning and streaming analysis baselines, providing accurate predictions over extended periods while minimising performance degradation over time by learning how the sequence dynamics change.
Performance-Driven QUBO for Recommender Systems on Quantum Annealers
Oct 20, 2024



We propose Counterfactual Analysis Quadratic Unconstrained Binary Optimization (CAQUBO) to solve QUBO problems for feature selection in recommender systems. CAQUBO leverages counterfactual analysis to measure the impact of individual features and feature combinations on model performance and employs the measurements to construct the coefficient matrix for a quantum annealer to select the optimal feature combinations for recommender systems, thereby improving their final recommendation performance. By establishing explicit connections between features and the recommendation performance, the proposed approach demonstrates superior performance compared to the state-of-the-art quantum annealing methods. Extensive experiments indicate that integrating quantum computing with counterfactual analysis holds great promise for addressing these challenges.
CRUISE on Quantum Computing for Feature Selection in Recommender Systems
Jul 03, 2024Using Quantum Computers to solve problems in Recommender Systems that classical computers cannot address is a worthwhile research topic. In this paper, we use Quantum Annealers to address the feature selection problem in recommendation algorithms. This feature selection problem is a Quadratic Unconstrained Binary Optimization(QUBO) problem. By incorporating Counterfactual Analysis, we significantly improve the performance of the item-based KNN recommendation algorithm compared to using pure Mutual Information. Extensive experiments have demonstrated that the use of Counterfactual Analysis holds great promise for addressing such problems.