 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetamorphic Evaluation of ChatGPT as a Recommender System
Nov 18, 2024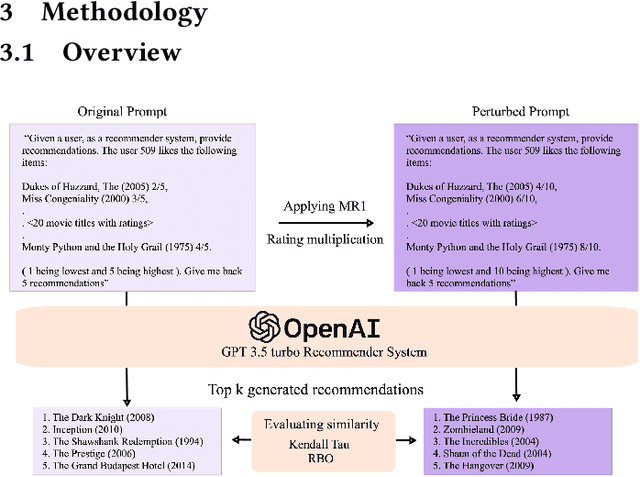

With the rise of Large Language Models (LLMs) such as ChatGPT, researchers have been working on how to utilize the LLMs for better recommendations. However, although LLMs exhibit black-box and probabilistic characteristics (meaning their internal working is not visible), the evaluation framework used for assessing these LLM-based recommender systems (RS) are the same as those used for traditional recommender systems. To address this gap, we introduce the metamorphic testing for the evaluation of GPT-based RS. This testing technique involves defining of metamorphic relations (MRs) between the inputs and checking if the relationship has been satisfied in the outputs. Specifically, we examined the MRs from both RS and LLMs perspectives, including rating multiplication/shifting in RS and adding spaces/randomness in the LLMs prompt via prompt perturbation. Similarity metrics (e.g. Kendall tau and Ranking Biased Overlap(RBO)) are deployed to measure whether the relationship has been satisfied in the outputs of MRs. The experiment results on MovieLens dataset with GPT3.5 show that lower similarity are obtained in terms of Kendall $\tau$ and RBO, which concludes that there is a need of a comprehensive evaluation of the LLM-based RS in addition to the existing evaluation metrics used for traditional recommender systems.