 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Mark Imbalance in Integration-free Neural Marked Temporal Point Processes
Oct 23, 2025Marked Temporal Point Process (MTPP) has been well studied to model the event distribution in marked event streams, which can be used to predict the mark and arrival time of the next event. However, existing studies overlook that the distribution of event marks is highly imbalanced in many real-world applications, with some marks being frequent but others rare. The imbalance poses a significant challenge to the performance of the next event prediction, especially for events of rare marks. To address this issue, we propose a thresholding method, which learns thresholds to tune the mark probability normalized by the mark's prior probability to optimize mark prediction, rather than predicting the mark directly based on the mark probability as in existing studies. In conjunction with this method, we predict the mark first and then the time. In particular, we develop a novel neural MTPP model to support effective time sampling and estimation of mark probability without computationally expensive numerical improper integration. Extensive experiments on real-world datasets demonstrate the superior performance of our solution against various baselines for the next event mark and time prediction. The code is available at https://github.com/undes1red/IFNMTPP.
Rehearsal-free and Task-free Online Continual Learning With Contrastive Prompt
Oct 01, 2025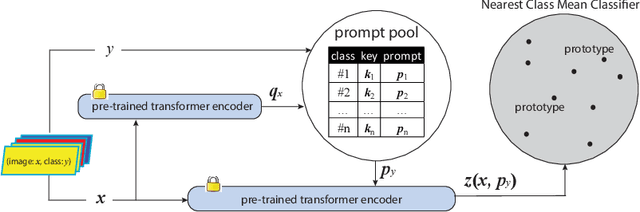
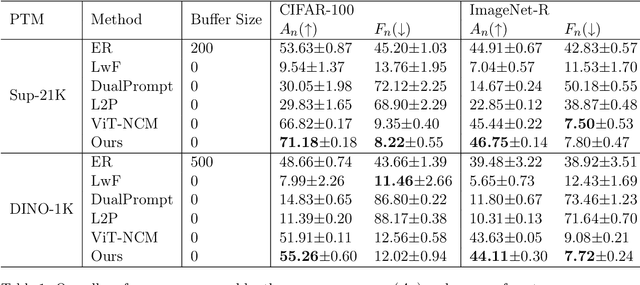
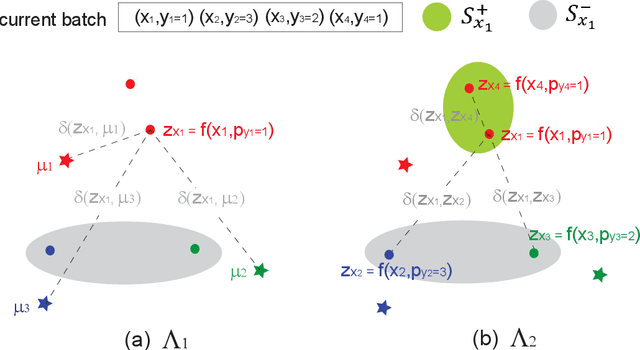

The main challenge of continual learning is \textit{catastrophic forgetting}. Because of processing data in one pass, online continual learning (OCL) is one of the most difficult continual learning scenarios. To address catastrophic forgetting in OCL, some existing studies use a rehearsal buffer to store samples and replay them in the later learning process, other studies do not store samples but assume a sequence of learning tasks so that the task identities can be explored. However, storing samples may raise data security or privacy concerns and it is not always possible to identify the boundaries between learning tasks in one pass of data processing. It motivates us to investigate rehearsal-free and task-free OCL (F2OCL). By integrating prompt learning with an NCM classifier, this study has effectively tackled catastrophic forgetting without storing samples and without usage of task boundaries or identities. The extensive experimental results on two benchmarks have demonstrated the effectiveness of the proposed method.
MemoryKT: An Integrative Memory-and-Forgetting Method for Knowledge Tracing
Aug 11, 2025Knowledge Tracing (KT) is committed to capturing students' knowledge mastery from their historical interactions. Simulating students' memory states is a promising approach to enhance both the performance and interpretability of knowledge tracing models. Memory consists of three fundamental processes: encoding, storage, and retrieval. Although forgetting primarily manifests during the storage stage, most existing studies rely on a single, undifferentiated forgetting mechanism, overlooking other memory processes as well as personalized forgetting patterns. To address this, this paper proposes memoryKT, a knowledge tracing model based on a novel temporal variational autoencoder. The model simulates memory dynamics through a three-stage process: (i) Learning the distribution of students' knowledge memory features, (ii) Reconstructing their exercise feedback, while (iii) Embedding a personalized forgetting module within the temporal workflow to dynamically modulate memory storage strength. This jointly models the complete encoding-storage-retrieval cycle, significantly enhancing the model's perception capability for individual differences. Extensive experiments on four public datasets demonstrate that our proposed approach significantly outperforms state-of-the-art baselines.
Generating Grounded Responses to Counter Misinformation via Learning Efficient Fine-Grained Critiques
Jun 06, 2025Fake news and misinformation poses a significant threat to society, making efficient mitigation essential. However, manual fact-checking is costly and lacks scalability. Large Language Models (LLMs) offer promise in automating counter-response generation to mitigate misinformation, but a critical challenge lies in their tendency to hallucinate non-factual information. Existing models mainly rely on LLM self-feedback to reduce hallucination, but this approach is computationally expensive. In this paper, we propose MisMitiFact, Misinformation Mitigation grounded in Facts, an efficient framework for generating fact-grounded counter-responses at scale. MisMitiFact generates simple critique feedback to refine LLM outputs, ensuring responses are grounded in evidence. We develop lightweight, fine-grained critique models trained on data sourced from readily available fact-checking sites to identify and correct errors in key elements such as numerals, entities, and topics in LLM generations. Experiments show that MisMitiFact generates counter-responses of comparable quality to LLMs' self-feedback while using significantly smaller critique models. Importantly, it achieves ~5x increase in feedback generation throughput, making it highly suitable for cost-effective, large-scale misinformation mitigation. Code and LLM prompt templates are at https://github.com/xxfwin/MisMitiFact.
Performance-Driven QUBO for Recommender Systems on Quantum Annealers
Oct 20, 2024



We propose Counterfactual Analysis Quadratic Unconstrained Binary Optimization (CAQUBO) to solve QUBO problems for feature selection in recommender systems. CAQUBO leverages counterfactual analysis to measure the impact of individual features and feature combinations on model performance and employs the measurements to construct the coefficient matrix for a quantum annealer to select the optimal feature combinations for recommender systems, thereby improving their final recommendation performance. By establishing explicit connections between features and the recommendation performance, the proposed approach demonstrates superior performance compared to the state-of-the-art quantum annealing methods. Extensive experiments indicate that integrating quantum computing with counterfactual analysis holds great promise for addressing these challenges.
CRUISE on Quantum Computing for Feature Selection in Recommender Systems
Jul 03, 2024Using Quantum Computers to solve problems in Recommender Systems that classical computers cannot address is a worthwhile research topic. In this paper, we use Quantum Annealers to address the feature selection problem in recommendation algorithms. This feature selection problem is a Quadratic Unconstrained Binary Optimization(QUBO) problem. By incorporating Counterfactual Analysis, we significantly improve the performance of the item-based KNN recommendation algorithm compared to using pure Mutual Information. Extensive experiments have demonstrated that the use of Counterfactual Analysis holds great promise for addressing such problems.
Efficient Surgical Tool Recognition via HMM-Stabilized Deep Learning
Apr 07, 2024



Recognizing various surgical tools, actions and phases from surgery videos is an important problem in computer vision with exciting clinical applications. Existing deep-learning-based methods for this problem either process each surgical video as a series of independent images without considering their dependence, or rely on complicated deep learning models to count for dependence of video frames. In this study, we revealed from exploratory data analysis that surgical videos enjoy relatively simple semantic structure, where the presence of surgical phases and tools can be well modeled by a compact hidden Markov model (HMM). Based on this observation, we propose an HMM-stabilized deep learning method for tool presence detection. A wide range of experiments confirm that the proposed approaches achieve better performance with lower training and running costs, and support more flexible ways to construct and utilize training data in scenarios where not all surgery videos of interest are extensively labelled. These results suggest that popular deep learning approaches with over-complicated model structures may suffer from inefficient utilization of data, and integrating ingredients of deep learning and statistical learning wisely may lead to more powerful algorithms that enjoy competitive performance, transparent interpretation and convenient model training simultaneously.
Transfer Learning-Enhanced Instantaneous Multi-Person Indoor Localization by CSI
Mar 02, 2024

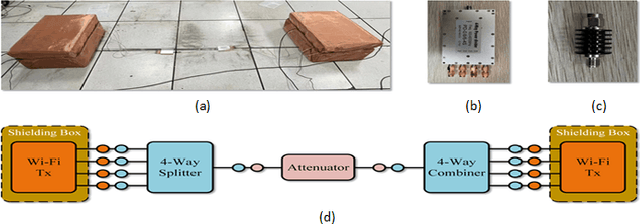
Passive indoor localization, integral to smart buildings, emergency response, and indoor navigation, has traditionally been limited by a focus on single-target localization and reliance on multi-packet CSI. We introduce a novel Multi-target loss, notably enhancing multi-person localization. Utilizing this loss function, our instantaneous CSI-ResNet achieves an impressive 99.21% accuracy at 0.6m precision with single-timestamp CSI. A preprocessing algorithm is implemented to counteract WiFi-induced variability, thereby augmenting robustness. Furthermore, we incorporate Nuclear Norm-Based Transfer Pre-Training, ensuring adaptability in diverse environments, which provides a new paradigm for indoor multi-person localization. Additionally, we have developed an extensive dataset, surpassing existing ones in scope and diversity, to underscore the efficacy of our method and facilitate future fingerprint-based localization research.
Harnessing Network Effect for Fake News Mitigation: Selecting Debunkers via Self-Imitation Learning
Jan 28, 2024This study aims to minimize the influence of fake news on social networks by deploying debunkers to propagate true news. This is framed as a reinforcement learning problem, where, at each stage, one user is selected to propagate true news. A challenging issue is episodic reward where the "net" effect of selecting individual debunkers cannot be discerned from the interleaving information propagation on social networks, and only the collective effect from mitigation efforts can be observed. Existing Self-Imitation Learning (SIL) methods have shown promise in learning from episodic rewards, but are ill-suited to the real-world application of fake news mitigation because of their poor sample efficiency. To learn a more effective debunker selection policy for fake news mitigation, this study proposes NAGASIL - Negative sampling and state Augmented Generative Adversarial Self-Imitation Learning, which consists of two improvements geared towards fake news mitigation: learning from negative samples, and an augmented state representation to capture the "real" environment state by integrating the current observed state with the previous state-action pairs from the same campaign. Experiments on two social networks show that NAGASIL yields superior performance to standard GASIL and state-of-the-art fake news mitigation models.
Explainable History Distillation by Marked Temporal Point Process
Nov 13, 2023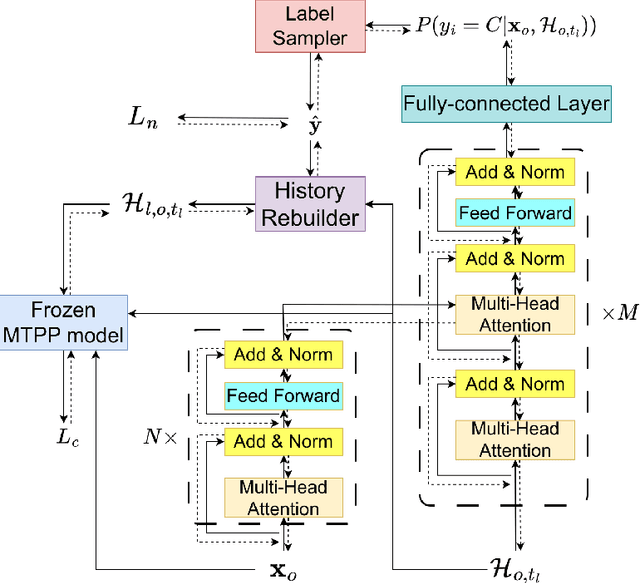


Explainability of machine learning models is mandatory when researchers introduce these commonly believed black boxes to real-world tasks, especially high-stakes ones. In this paper, we build a machine learning system to automatically generate explanations of happened events from history by \gls{ca} based on the \acrfull{tpp}. Specifically, we propose a new task called \acrfull{ehd}. This task requires a model to distill as few events as possible from observed history. The target is that the event distribution conditioned on left events predicts the observed future noticeably worse. We then regard distilled events as the explanation for the future. To efficiently solve \acrshort{ehd}, we rewrite the task into a \gls{01ip} and directly estimate the solution to the program by a model called \acrfull{model}. This work fills the gap between our task and existing works, which only spot the difference between factual and counterfactual worlds after applying a predefined modification to the environment. Experiment results on Retweet and StackOverflow datasets prove that \acrshort{model} significantly outperforms other \acrshort{ehd} baselines and can reveal the rationale underpinning real-world processes.