 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Optical Flow Prediction Improves Robot Control & Video Generation
Jan 15, 2026Future motion representations, such as optical flow, offer immense value for control and generative tasks. However, forecasting generalizable spatially dense motion representations remains a key challenge, and learning such forecasting from noisy, real-world data remains relatively unexplored. We introduce FOFPred, a novel language-conditioned optical flow forecasting model featuring a unified Vision-Language Model (VLM) and Diffusion architecture. This unique combination enables strong multimodal reasoning with pixel-level generative fidelity for future motion prediction. Our model is trained on web-scale human activity data-a highly scalable but unstructured source. To extract meaningful signals from this noisy video-caption data, we employ crucial data preprocessing techniques and our unified architecture with strong image pretraining. The resulting trained model is then extended to tackle two distinct downstream tasks in control and generation. Evaluations across robotic manipulation and video generation under language-driven settings establish the cross-domain versatility of FOFPred, confirming the value of a unified VLM-Diffusion architecture and scalable learning from diverse web data for future optical flow prediction.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
FLARE: Robot Learning with Implicit World Modeling
May 21, 2025We introduce $\textbf{F}$uture $\textbf{LA}$tent $\textbf{RE}$presentation Alignment ($\textbf{FLARE}$), a novel framework that integrates predictive latent world modeling into robot policy learning. By aligning features from a diffusion transformer with latent embeddings of future observations, $\textbf{FLARE}$ enables a diffusion transformer policy to anticipate latent representations of future observations, allowing it to reason about long-term consequences while generating actions. Remarkably lightweight, $\textbf{FLARE}$ requires only minimal architectural modifications -- adding a few tokens to standard vision-language-action (VLA) models -- yet delivers substantial performance gains. Across two challenging multitask simulation imitation learning benchmarks spanning single-arm and humanoid tabletop manipulation, $\textbf{FLARE}$ achieves state-of-the-art performance, outperforming prior policy learning baselines by up to 26%. Moreover, $\textbf{FLARE}$ unlocks the ability to co-train with human egocentric video demonstrations without action labels, significantly boosting policy generalization to a novel object with unseen geometry with as few as a single robot demonstration. Our results establish $\textbf{FLARE}$ as a general and scalable approach for combining implicit world modeling with high-frequency robotic control.
DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories
May 19, 2025We introduce DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories - synthetic robot data generated from video world models. DreamGen leverages state-of-the-art image-to-video generative models, adapting them to the target robot embodiment to produce photorealistic synthetic videos of familiar or novel tasks in diverse environments. Since these models generate only videos, we recover pseudo-action sequences using either a latent action model or an inverse-dynamics model (IDM). Despite its simplicity, DreamGen unlocks strong behavior and environment generalization: a humanoid robot can perform 22 new behaviors in both seen and unseen environments, while requiring teleoperation data from only a single pick-and-place task in one environment. To evaluate the pipeline systematically, we introduce DreamGen Bench, a video generation benchmark that shows a strong correlation between benchmark performance and downstream policy success. Our work establishes a promising new axis for scaling robot learning well beyond manual data collection.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
Mar 15, 2025Vision-language-action (VLA) models present a promising paradigm by training policies directly on real robot datasets like Open X-Embodiment. However, the high cost of real-world data collection hinders further data scaling, thereby restricting the generalizability of VLAs. In this paper, we introduce ReBot, a novel real-to-sim-to-real approach for scaling real robot datasets and adapting VLA models to target domains, which is the last-mile deployment challenge in robot manipulation. Specifically, ReBot replays real-world robot trajectories in simulation to diversify manipulated objects (real-to-sim), and integrates the simulated movements with inpainted real-world background to synthesize physically realistic and temporally consistent robot videos (sim-to-real). Our approach has several advantages: 1) it enjoys the benefit of real data to minimize the sim-to-real gap; 2) it leverages the scalability of simulation; and 3) it can generalize a pretrained VLA to a target domain with fully automated data pipelines. Extensive experiments in both simulation and real-world environments show that ReBot significantly enhances the performance and robustness of VLAs. For example, in SimplerEnv with the WidowX robot, ReBot improved the in-domain performance of Octo by 7.2% and OpenVLA by 21.8%, and out-of-domain generalization by 19.9% and 9.4%, respectively. For real-world evaluation with a Franka robot, ReBot increased the success rates of Octo by 17% and OpenVLA by 20%. More information can be found at: https://yuffish.github.io/rebot/
DiVISe: Direct Visual-Input Speech Synthesis Preserving Speaker Characteristics And Intelligibility
Mar 07, 2025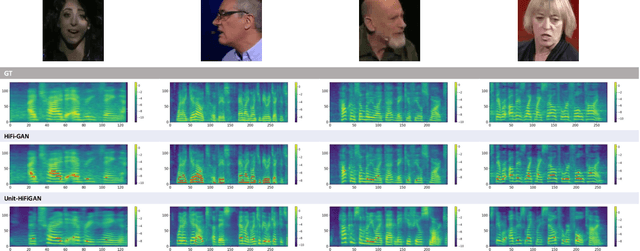
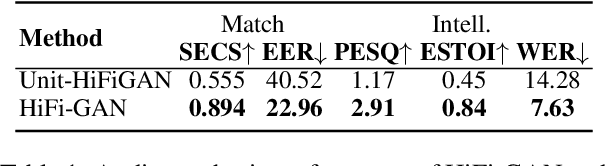
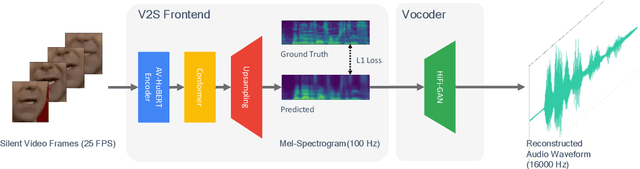
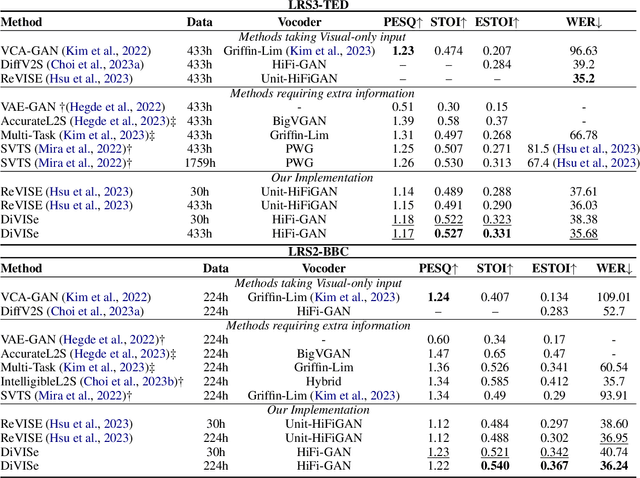
Video-to-speech (V2S) synthesis, the task of generating speech directly from silent video input, is inherently more challenging than other speech synthesis tasks due to the need to accurately reconstruct both speech content and speaker characteristics from visual cues alone. Recently, audio-visual pre-training has eliminated the need for additional acoustic hints in V2S, which previous methods often relied on to ensure training convergence. However, even with pre-training, existing methods continue to face challenges in achieving a balance between acoustic intelligibility and the preservation of speaker-specific characteristics. We analyzed this limitation and were motivated to introduce DiVISe (Direct Visual-Input Speech Synthesis), an end-to-end V2S model that predicts Mel-spectrograms directly from video frames alone. Despite not taking any acoustic hints, DiVISe effectively preserves speaker characteristics in the generated audio, and achieves superior performance on both objective and subjective metrics across the LRS2 and LRS3 datasets. Our results demonstrate that DiVISe not only outperforms existing V2S models in acoustic intelligibility but also scales more effectively with increased data and model parameters. Code and weights can be found at https://github.com/PussyCat0700/DiVISe.
Virtual Reflections on a Dynamic 2D Eye Model Improve Spatial Reference Identification
Dec 10, 2024



The visible orientation of human eyes creates some transparency about people's spatial attention and other mental states. This leads to a dual role for the eyes as a means of sensing and communication. Accordingly, artificial eye models are being explored as communication media in human-machine interaction scenarios. One challenge in the use of eye models for communication consists of resolving spatial reference ambiguities, especially for screen-based models. Here, we introduce an approach for overcoming this challenge through the introduction of reflection-like features that are contingent on artificial eye movements. We conducted a user study with 30 participants in which participants had to use spatial references provided by dynamic eye models to advance in a fast-paced group interaction task. Compared to a non-reflective eye model and a pure reflection mode, their combination in the new approach resulted in a higher identification accuracy and user experience, suggesting a synergistic benefit.
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023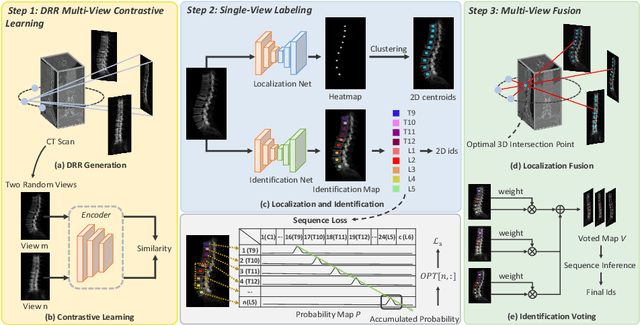
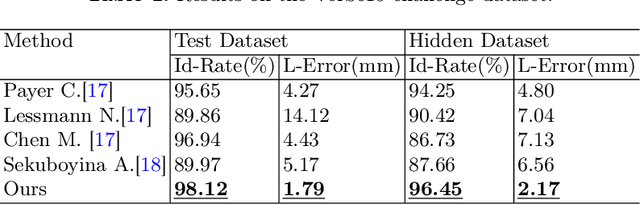
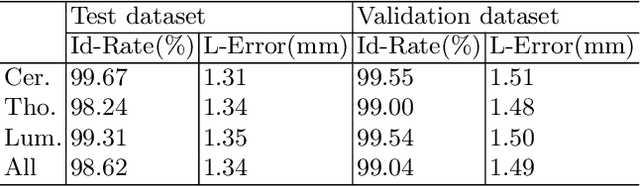
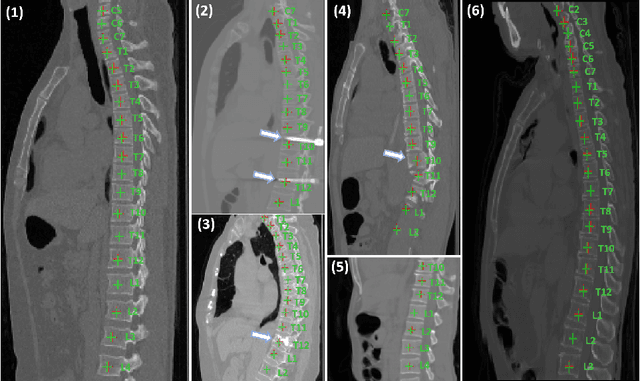
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.