 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Channel Knowledge Map Assisted Scheduling Optimization of Active IRSs in Multi-User Systems
Aug 09, 2025Intelligent Reflecting Surfaces (IRSs) have potential for significant performance gains in next-generation wireless networks but face key challenges, notably severe double-pathloss and complex multi-user scheduling due to hardware constraints. Active IRSs partially address pathloss but still require efficient scheduling in cell-level multi-IRS multi-user systems, whereby the overhead/delay of channel state acquisition and the scheduling complexity both rise dramatically as the user density and channel dimensions increase. Motivated by these challenges, this paper proposes a novel scheduling framework based on neural Channel Knowledge Map (CKM), designing Transformer-based deep neural networks (DNNs) to predict ergodic spectral efficiency (SE) from historical channel/throughput measurements tagged with user positions. Specifically, two cascaded networks, LPS-Net and SE-Net, are designed to predict link power statistics (LPS) and ergodic SE accurately. We further propose a low-complexity Stable Matching-Iterative Balancing (SM-IB) scheduling algorithm. Numerical evaluations verify that the proposed neural CKM significantly enhances prediction accuracy and computational efficiency, while the SM-IB algorithm effectively achieves near-optimal max-min throughput with greatly reduced complexity.
Quasi-Static IRS: 3D Shaped Beamforming for Area Coverage Enhancement
May 02, 2025Intelligent reflecting surface (IRS) is a promising paradigm to reconfigure the wireless environment for enhanced communication coverage and quality. However, to compensate for the double pathloss effect, massive IRS elements are required, raising concerns on the scalability of cost and complexity. This paper introduces a new architecture of quasi-static IRS (QS-IRS), which tunes element phases via mechanical adjustment or manually re-arranging the array topology. QS-IRS relies on massive production/assembly of purely passive elements only, and thus is suitable for ultra low-cost and large-scale deployment to enhance long-term coverage. To achieve this end, an IRS-aided area coverage problem is formulated, which explicitly considers the element radiation pattern (ERP), with the newly introduced shape masks for the mainlobe, and the sidelobe constraints to reduce energy leakage. An alternating optimization (AO) algorithm based on the difference-of-convex (DC) and successive convex approximation (SCA) procedure is proposed, which achieves shaped beamforming with power gains close to that of the joint optimization algorithm, but with significantly reduced computational complexity.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
Oct 31, 2024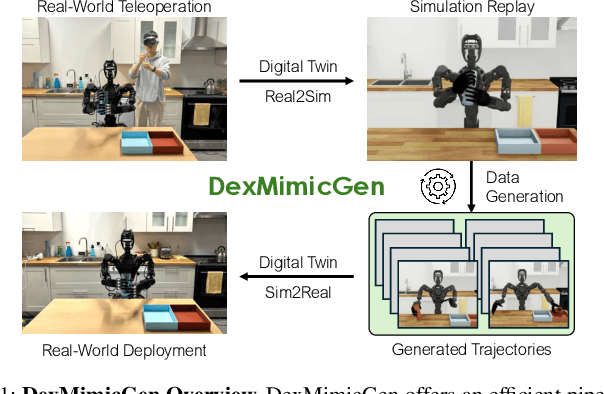

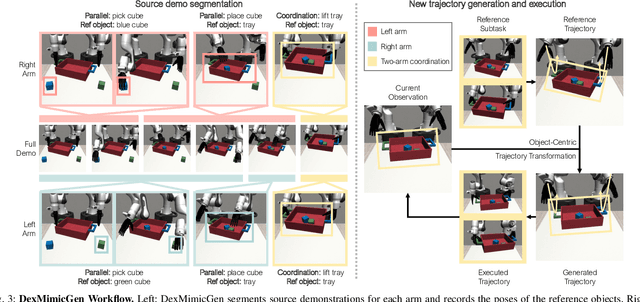

Imitation learning from human demonstrations is an effective means to teach robots manipulation skills. But data acquisition is a major bottleneck in applying this paradigm more broadly, due to the amount of cost and human effort involved. There has been significant interest in imitation learning for bimanual dexterous robots, like humanoids. Unfortunately, data collection is even more challenging here due to the challenges of simultaneously controlling multiple arms and multi-fingered hands. Automated data generation in simulation is a compelling, scalable alternative to fuel this need for data. To this end, we introduce DexMimicGen, a large-scale automated data generation system that synthesizes trajectories from a handful of human demonstrations for humanoid robots with dexterous hands. We present a collection of simulation environments in the setting of bimanual dexterous manipulation, spanning a range of manipulation behaviors and different requirements for coordination among the two arms. We generate 21K demos across these tasks from just 60 source human demos and study the effect of several data generation and policy learning decisions on agent performance. Finally, we present a real-to-sim-to-real pipeline and deploy it on a real-world humanoid can sorting task. Videos and more are at https://dexmimicgen.github.io/
HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
Oct 28, 2024



Humanoid whole-body control requires adapting to diverse tasks such as navigation, loco-manipulation, and tabletop manipulation, each demanding a different mode of control. For example, navigation relies on root velocity tracking, while tabletop manipulation prioritizes upper-body joint angle tracking. Existing approaches typically train individual policies tailored to a specific command space, limiting their transferability across modes. We present the key insight that full-body kinematic motion imitation can serve as a common abstraction for all these tasks and provide general-purpose motor skills for learning multiple modes of whole-body control. Building on this, we propose HOVER (Humanoid Versatile Controller), a multi-mode policy distillation framework that consolidates diverse control modes into a unified policy. HOVER enables seamless transitions between control modes while preserving the distinct advantages of each, offering a robust and scalable solution for humanoid control across a wide range of modes. By eliminating the need for policy retraining for each control mode, our approach improves efficiency and flexibility for future humanoid applications.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
Oct 16, 2024Humanoid robots, with their human-like embodiment, have the potential to integrate seamlessly into human environments. Critical to their coexistence and cooperation with humans is the ability to understand natural language communications and exhibit human-like behaviors. This work focuses on generating diverse whole-body motions for humanoid robots from language descriptions. We leverage human motion priors from extensive human motion datasets to initialize humanoid motions and employ the commonsense reasoning capabilities of Vision Language Models (VLMs) to edit and refine these motions. Our approach demonstrates the capability to produce natural, expressive, and text-aligned humanoid motions, validated through both simulated and real-world experiments. More videos can be found at https://ut-austin-rpl.github.io/Harmon/.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.
KinScene: Model-Based Mobile Manipulation of Articulated Scenes
Sep 24, 2024
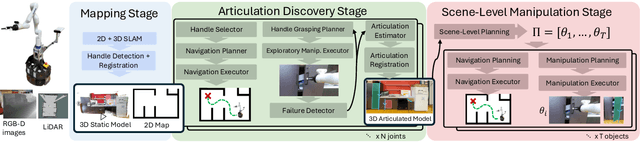
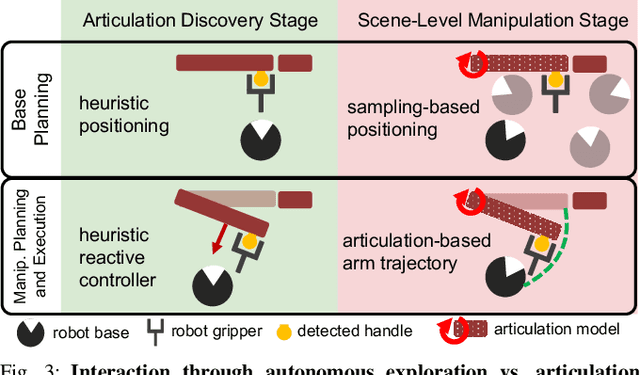

Sequentially interacting with articulated objects is crucial for a mobile manipulator to operate effectively in everyday environments. To enable long-horizon tasks involving articulated objects, this study explores building scene-level articulation models for indoor scenes through autonomous exploration. While previous research has studied mobile manipulation with articulated objects by considering object kinematic constraints, it primarily focuses on individual-object scenarios and lacks extension to a scene-level context for task-level planning. To manipulate multiple object parts sequentially, the robot needs to reason about the resultant motion of each part and anticipate its impact on future actions.We introduce \ourtool{}, a full-stack approach for long-horizon manipulation tasks with articulated objects. The robot maps the scene, detects and physically interacts with articulated objects, collects observations, and infers the articulation properties. For sequential tasks, the robot plans a feasible series of object interactions based on the inferred articulation model. We demonstrate that our approach repeatably constructs accurate scene-level kinematic and geometric models, enabling long-horizon mobile manipulation in a real-world scene. Code and additional results are available at https://chengchunhsu.github.io/KinScene/
ARDuP: Active Region Video Diffusion for Universal Policies
Jun 19, 2024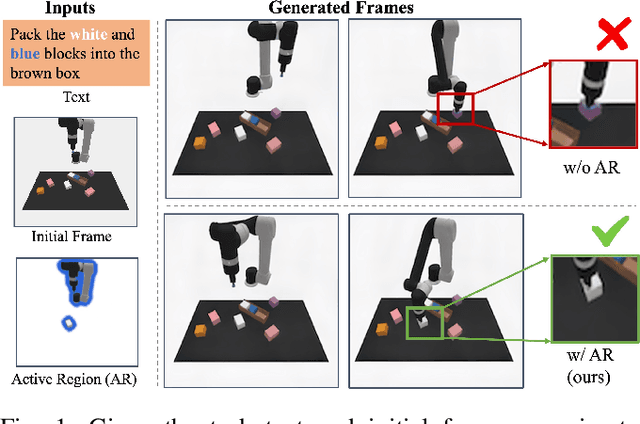
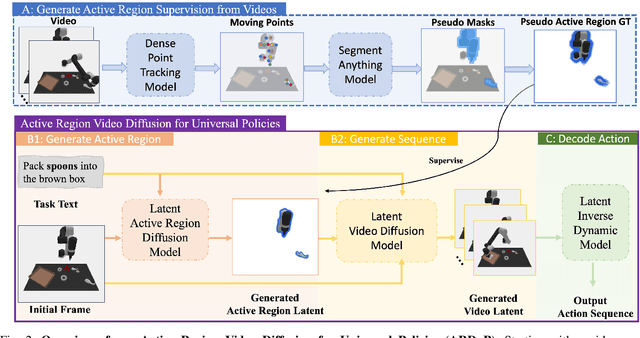
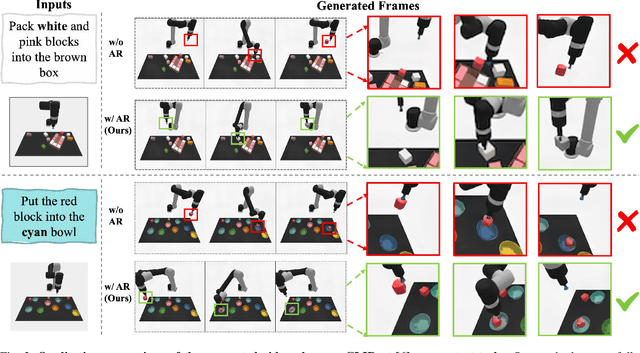
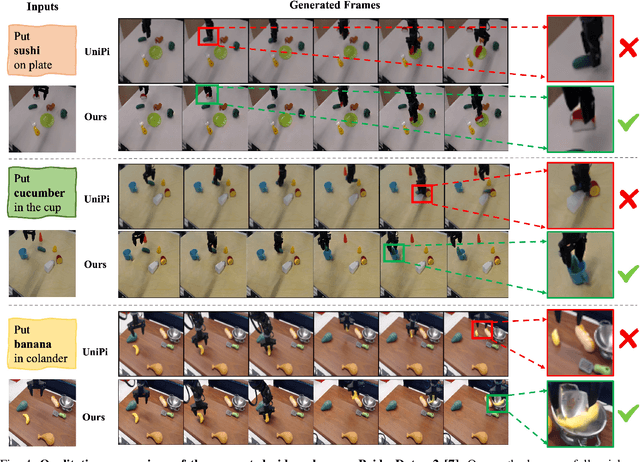
Sequential decision-making can be formulated as a text-conditioned video generation problem, where a video planner, guided by a text-defined goal, generates future frames visualizing planned actions, from which control actions are subsequently derived. In this work, we introduce Active Region Video Diffusion for Universal Policies (ARDuP), a novel framework for video-based policy learning that emphasizes the generation of active regions, i.e. potential interaction areas, enhancing the conditional policy's focus on interactive areas critical for task execution. This innovative framework integrates active region conditioning with latent diffusion models for video planning and employs latent representations for direct action decoding during inverse dynamic modeling. By utilizing motion cues in videos for automatic active region discovery, our method eliminates the need for manual annotations of active regions. We validate ARDuP's efficacy via extensive experiments on simulator CLIPort and the real-world dataset BridgeData v2, achieving notable improvements in success rates and generating convincingly realistic video plans.