 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARISTO Hand: Sensing-Driven Distal Hyperextension for Fine-Grained Manipulation
May 28, 2026Manipulating thin objects requires precise contact geometry and reliable force perception, yet many anthropomorphic robotic hands lack the mechanical and sensing capabilities needed for such interactions. We present the ARISTO Hand, a tendon-driven robotic hand that integrates active distal hyperextension with a hybrid fingertip-sensing architecture that combines a rigid, nail-mounted force-torque sensor and a soft capacitive tactile array. Active hyperextension enables controlled fingertip engagement beyond the kinematic limits of standard flexion, increasing pull-out force by 2.76x for object thicknesses of 1-20 mm while preserving the nominal grasp capability. The rigid nail-mounted sensor provides reliable force measurements during edge contacts, where the sensitivity of proprioceptive force estimation degrades as the contact geometry approaches kinematic singularities. We validate the proposed architecture through quantitative force characterization and a multi-stage SD card extraction and insertion task. Video and supplementary materials are available at: https://aristohand.github.io
PLATO Hand: Shaping Contact Behavior with Fingernails for Precise Manipulation
Feb 05, 2026We present the PLATO Hand, a dexterous robotic hand with a hybrid fingertip that embeds a rigid fingernail within a compliant pulp. This design shapes contact behavior to enable diverse interaction modes across a range of object geometries. We develop a strain-energy-based bending-indentation model to guide the fingertip design and to explain how guided contact preserves local indentation while suppressing global bending. Experimental results show that the proposed robotic hand design demonstrates improved pinching stability, enhanced force observability, and successful execution of edge-sensitive manipulation tasks, including paper singulation, card picking, and orange peeling. Together, these results show that coupling structured contact geometry with a force-motion transparent mechanism provides a principled, physically embodied approach to precise manipulation.
HARMONIC: A Content-Centric Cognitive Robotic Architecture
Sep 16, 2025This paper introduces HARMONIC, a cognitive-robotic architecture designed for robots in human-robotic teams. HARMONIC supports semantic perception interpretation, human-like decision-making, and intentional language communication. It addresses the issues of safety and quality of results; aims to solve problems of data scarcity, explainability, and safety; and promotes transparency and trust. Two proof-of-concept HARMONIC-based robotic systems are demonstrated, each implemented in both a high-fidelity simulation environment and on physical robotic platforms.
FORTE: Tactile Force and Slip Sensing on Compliant Fingers for Delicate Manipulation
Jun 23, 2025



Handling delicate and fragile objects remains a major challenge for robotic manipulation, especially for rigid parallel grippers. While the simplicity and versatility of parallel grippers have led to widespread adoption, these grippers are limited by their heavy reliance on visual feedback. Tactile sensing and soft robotics can add responsiveness and compliance. However, existing methods typically involve high integration complexity or suffer from slow response times. In this work, we introduce FORTE, a tactile sensing system embedded in compliant gripper fingers. FORTE uses 3D-printed fin-ray grippers with internal air channels to provide low-latency force and slip feedback. FORTE applies just enough force to grasp objects without damaging them, while remaining easy to fabricate and integrate. We find that FORTE can accurately estimate grasping forces from 0-8 N with an average error of 0.2 N, and detect slip events within 100 ms of occurring. We demonstrate FORTE's ability to grasp a wide range of slippery, fragile, and deformable objects. In particular, FORTE grasps fragile objects like raspberries and potato chips with a 98.6% success rate, and achieves 93% accuracy in detecting slip events. These results highlight FORTE's potential as a robust and practical solution for enabling delicate robotic manipulation. Project page: https://merge-lab.github.io/FORTE
Casper: Inferring Diverse Intents for Assistive Teleoperation with Vision Language Models
Jun 17, 2025



Assistive teleoperation, where control is shared between a human and a robot, enables efficient and intuitive human-robot collaboration in diverse and unstructured environments. A central challenge in real-world assistive teleoperation is for the robot to infer a wide range of human intentions from user control inputs and to assist users with correct actions. Existing methods are either confined to simple, predefined scenarios or restricted to task-specific data distributions at training, limiting their support for real-world assistance. We introduce Casper, an assistive teleoperation system that leverages commonsense knowledge embedded in pre-trained visual language models (VLMs) for real-time intent inference and flexible skill execution. Casper incorporates an open-world perception module for a generalized understanding of novel objects and scenes, a VLM-powered intent inference mechanism that leverages commonsense reasoning to interpret snippets of teleoperated user input, and a skill library that expands the scope of prior assistive teleoperation systems to support diverse, long-horizon mobile manipulation tasks. Extensive empirical evaluation, including human studies and system ablations, demonstrates that Casper improves task performance, reduces human cognitive load, and achieves higher user satisfaction than direct teleoperation and assistive teleoperation baselines.
LEGATO: Cross-Embodiment Imitation Using a Grasping Tool
Nov 06, 2024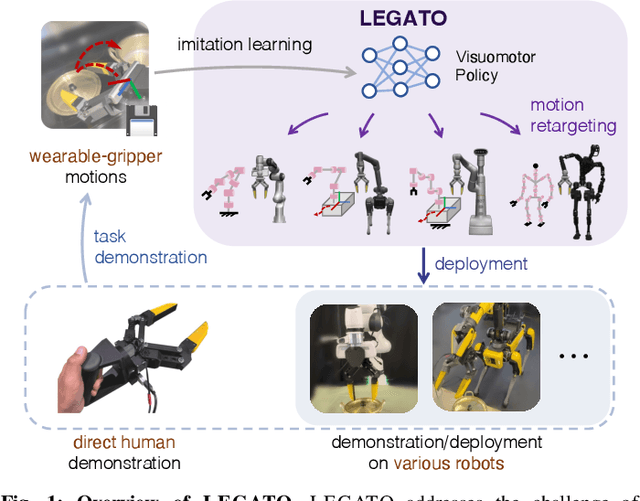
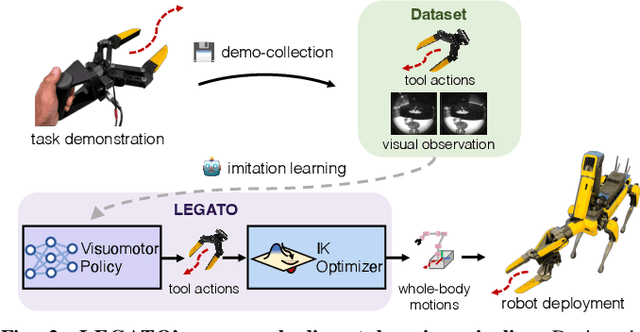
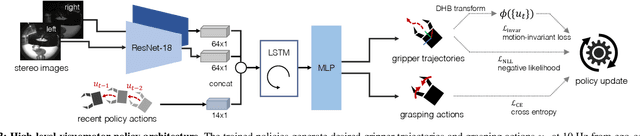
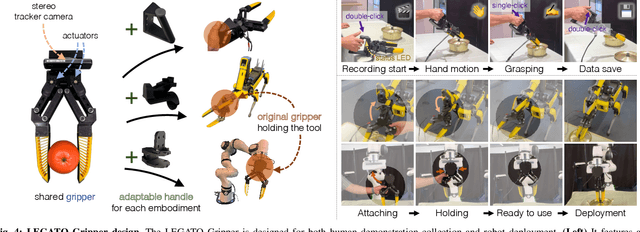
Cross-embodiment imitation learning enables policies trained on specific embodiments to transfer across different robots, unlocking the potential for large-scale imitation learning that is both cost-effective and highly reusable. This paper presents LEGATO, a cross-embodiment imitation learning framework for visuomotor skill transfer across varied kinematic morphologies. We introduce a handheld gripper that unifies action and observation spaces, allowing tasks to be defined consistently across robots. Using this gripper, we train visuomotor policies via imitation learning, applying a motion-invariant transformation to compute the training loss. Gripper motions are then retargeted into high-degree-of-freedom whole-body motions using inverse kinematics for deployment across diverse embodiments. Our evaluations in simulation and real-robot experiments highlight the framework's effectiveness in learning and transferring visuomotor skills across various robots. More information can be found at the project page: https://ut-hcrl.github.io/LEGATO.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.
PRESTO: Fast motion planning using diffusion models based on key-configuration environment representation
Sep 24, 2024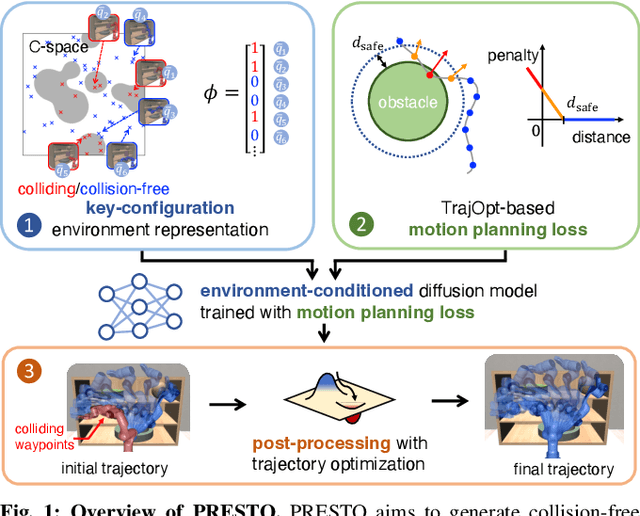
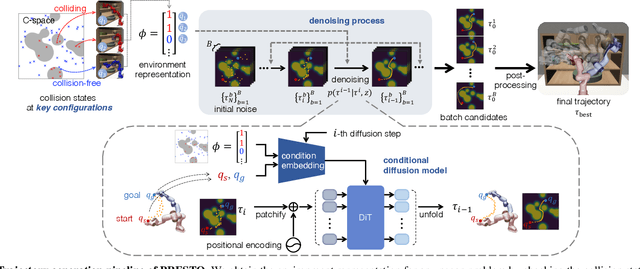
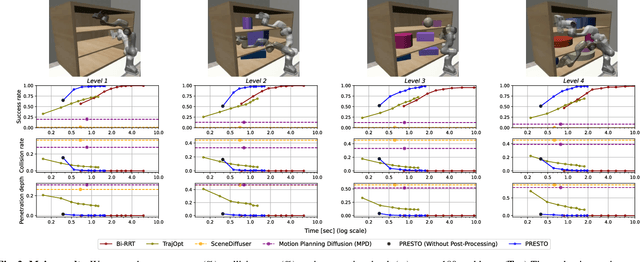
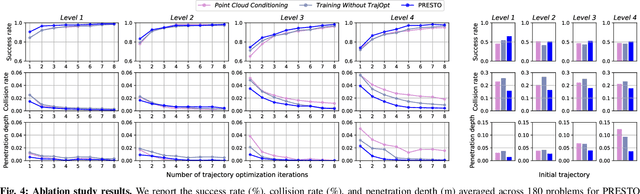
We introduce a learning-guided motion planning framework that provides initial seed trajectories using a diffusion model for trajectory optimization. Given a workspace, our method approximates the configuration space (C-space) obstacles through a key-configuration representation that consists of a sparse set of task-related key configurations, and uses this as an input to the diffusion model. The diffusion model integrates regularization terms that encourage collision avoidance and smooth trajectories during training, and trajectory optimization refines the generated seed trajectories to further correct any colliding segments. Our experimental results demonstrate that using high-quality trajectory priors, learned through our C-space-grounded diffusion model, enables efficient generation of collision-free trajectories in narrow-passage environments, outperforming prior learning- and planning-based baselines. Videos and additional materials can be found on the project page: https://kiwi-sherbet.github.io/PRESTO.
RPC: A Modular Framework for Robot Planning, Control, and Deployment
Sep 16, 2024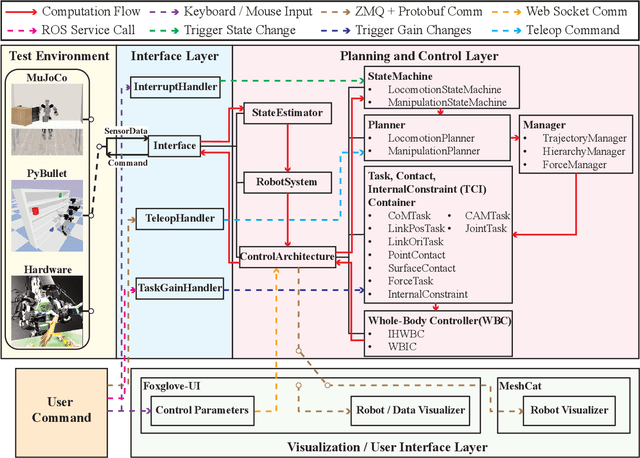
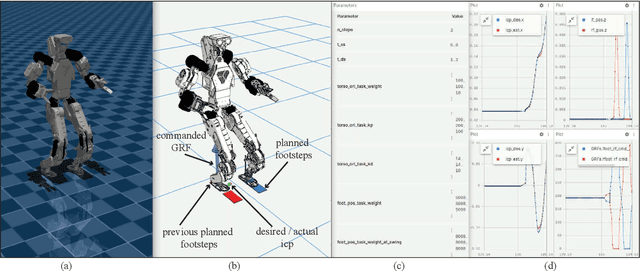
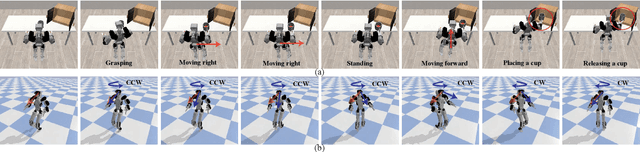

This paper presents an open-source, lightweight, yet comprehensive software framework, named RPC, which integrates physics-based simulators, planning and control libraries, debugging tools, and a user-friendly operator interface. RPC enables users to thoroughly evaluate and develop control algorithms for robotic systems. While existing software frameworks provide some of these capabilities, integrating them into a cohesive system can be challenging and cumbersome. To overcome this challenge, we have modularized each component in RPC to ensure easy and seamless integration or replacement with new modules. Additionally, our framework currently supports a variety of model-based planning and control algorithms for robotic manipulators and legged robots, alongside essential debugging tools, making it easier for users to design and execute complex robotics tasks. The code and usage instructions of RPC are available at https://github.com/shbang91/rpc.
Deep Imitation Learning for Humanoid Loco-manipulation through Human Teleoperation
Sep 05, 2023



We tackle the problem of developing humanoid loco-manipulation skills with deep imitation learning. The difficulty of collecting task demonstrations and training policies for humanoids with a high degree of freedom presents substantial challenges. We introduce TRILL, a data-efficient framework for training humanoid loco-manipulation policies from human demonstrations. In this framework, we collect human demonstration data through an intuitive Virtual Reality (VR) interface. We employ the whole-body control formulation to transform task-space commands by human operators into the robot's joint-torque actuation while stabilizing its dynamics. By employing high-level action abstractions tailored for humanoid loco-manipulation, our method can efficiently learn complex sensorimotor skills. We demonstrate the effectiveness of TRILL in simulation and on a real-world robot for performing various loco-manipulation tasks. Videos and additional materials can be found on the project page: https://ut-austin-rpl.github.io/TRILL.