 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical and Modular Network on Non-prehensile Manipulation in General Environments
Feb 28, 2025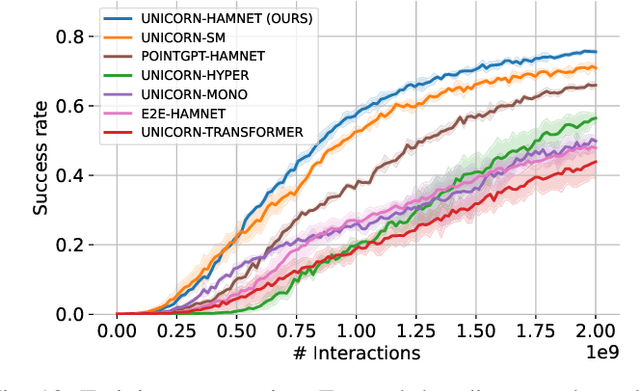
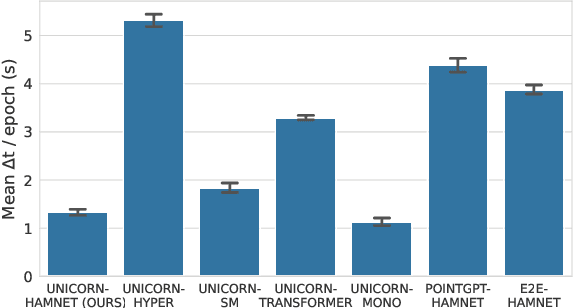
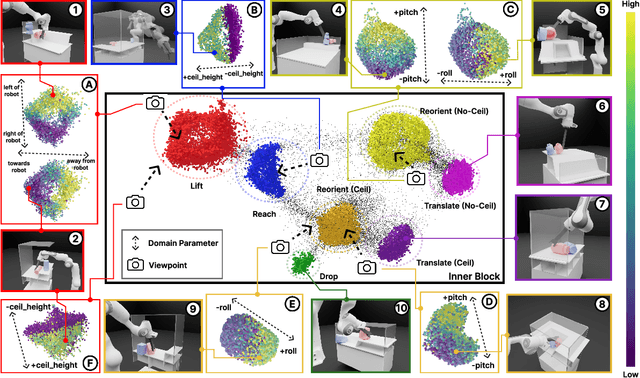
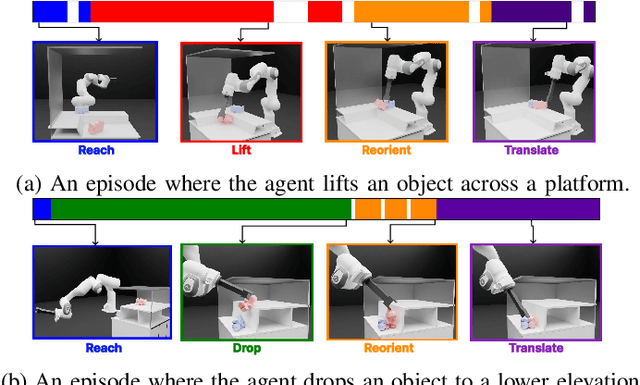
For robots to operate in general environments like households, they must be able to perform non-prehensile manipulation actions such as toppling and rolling to manipulate ungraspable objects. However, prior works on non-prehensile manipulation cannot yet generalize across environments with diverse geometries. The main challenge lies in adapting to varying environmental constraints: within a cabinet, the robot must avoid walls and ceilings; to lift objects to the top of a step, the robot must account for the step's pose and extent. While deep reinforcement learning (RL) has demonstrated impressive success in non-prehensile manipulation, accounting for such variability presents a challenge for the generalist policy, as it must learn diverse strategies for each new combination of constraints. To address this, we propose a modular and reconfigurable architecture that adaptively reconfigures network modules based on task requirements. To capture the geometric variability in environments, we extend the contact-based object representation (CORN) to environment geometries, and propose a procedural algorithm for generating diverse environments to train our agent. Taken together, the resulting policy can zero-shot transfer to novel real-world environments and objects despite training entirely within a simulator. We additionally release a simulation-based benchmark featuring nine digital twins of real-world scenes with 353 objects to facilitate non-prehensile manipulation research in realistic domains.
PRESTO: Fast motion planning using diffusion models based on key-configuration environment representation
Sep 24, 2024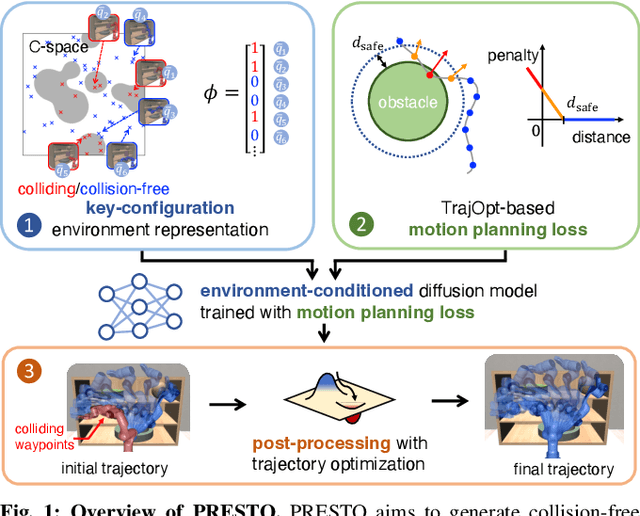
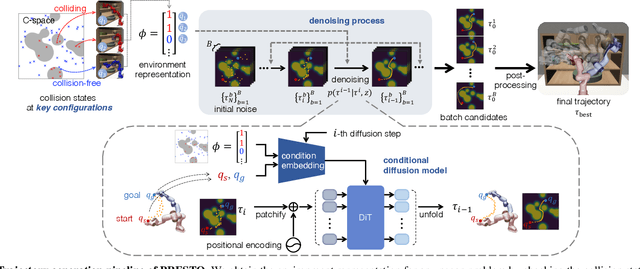
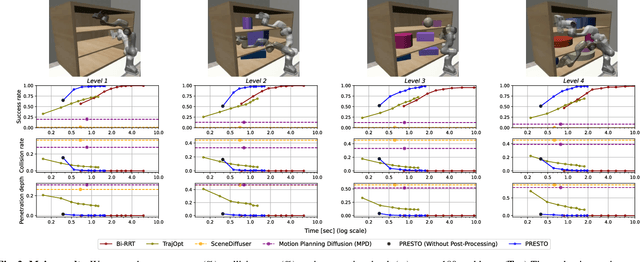
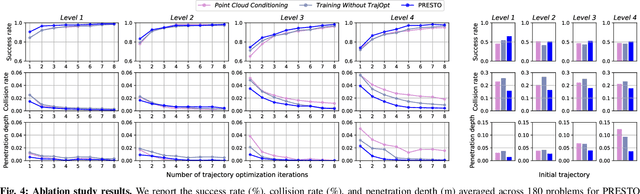
We introduce a learning-guided motion planning framework that provides initial seed trajectories using a diffusion model for trajectory optimization. Given a workspace, our method approximates the configuration space (C-space) obstacles through a key-configuration representation that consists of a sparse set of task-related key configurations, and uses this as an input to the diffusion model. The diffusion model integrates regularization terms that encourage collision avoidance and smooth trajectories during training, and trajectory optimization refines the generated seed trajectories to further correct any colliding segments. Our experimental results demonstrate that using high-quality trajectory priors, learned through our C-space-grounded diffusion model, enables efficient generation of collision-free trajectories in narrow-passage environments, outperforming prior learning- and planning-based baselines. Videos and additional materials can be found on the project page: https://kiwi-sherbet.github.io/PRESTO.
CORN: Contact-based Object Representation for Nonprehensile Manipulation of General Unseen Objects
Mar 16, 2024



Nonprehensile manipulation is essential for manipulating objects that are too thin, large, or otherwise ungraspable in the wild. To sidestep the difficulty of contact modeling in conventional modeling-based approaches, reinforcement learning (RL) has recently emerged as a promising alternative. However, previous RL approaches either lack the ability to generalize over diverse object shapes, or use simple action primitives that limit the diversity of robot motions. Furthermore, using RL over diverse object geometry is challenging due to the high cost of training a policy that takes in high-dimensional sensory inputs. We propose a novel contact-based object representation and pretraining pipeline to tackle this. To enable massively parallel training, we leverage a lightweight patch-based transformer architecture for our encoder that processes point clouds, thus scaling our training across thousands of environments. Compared to learning from scratch, or other shape representation baselines, our representation facilitates both time- and data-efficient learning. We validate the efficacy of our overall system by zero-shot transferring the trained policy to novel real-world objects. Code and videos are available at https://sites.google.com/view/contact-non-prehensile.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.