 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Apr 13, 2026Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-language models. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .
SAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025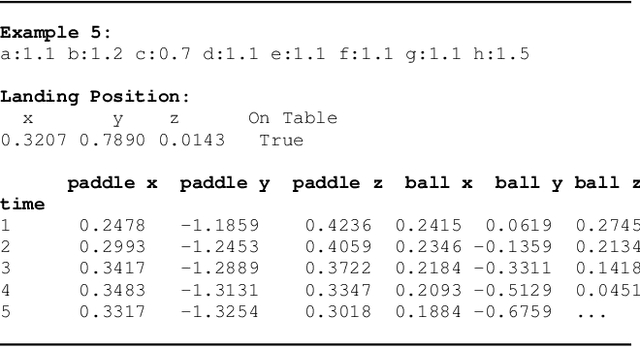

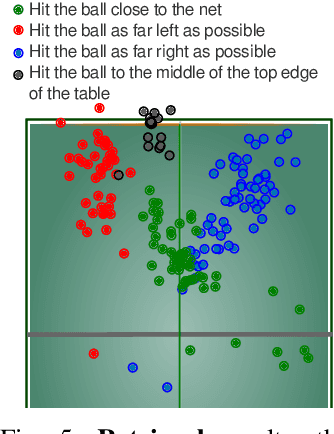

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Imitating Language via Scalable Inverse Reinforcement Learning
Sep 02, 2024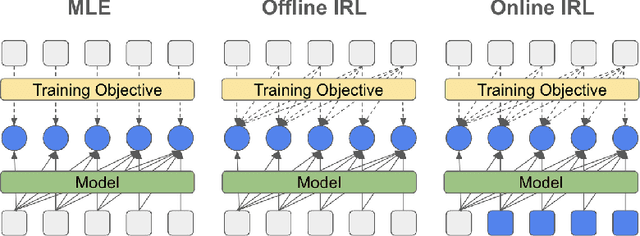
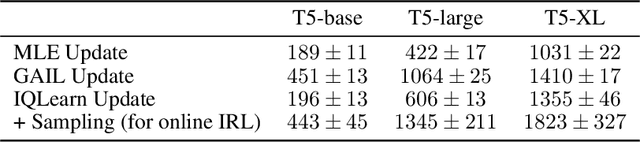
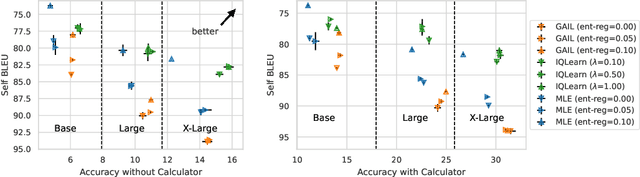

The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Mar 21, 2024



Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide analyses of zero-shot performance, ablations, and real-world qualitative examples.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Robots That Can See: Leveraging Human Pose for Trajectory Prediction
Sep 29, 2023



Anticipating the motion of all humans in dynamic environments such as homes and offices is critical to enable safe and effective robot navigation. Such spaces remain challenging as humans do not follow strict rules of motion and there are often multiple occluded entry points such as corners and doors that create opportunities for sudden encounters. In this work, we present a Transformer based architecture to predict human future trajectories in human-centric environments from input features including human positions, head orientations, and 3D skeletal keypoints from onboard in-the-wild sensory information. The resulting model captures the inherent uncertainty for future human trajectory prediction and achieves state-of-the-art performance on common prediction benchmarks and a human tracking dataset captured from a mobile robot adapted for the prediction task. Furthermore, we identify new agents with limited historical data as a major contributor to error and demonstrate the complementary nature of 3D skeletal poses in reducing prediction error in such challenging scenarios.
* Project page: https://human-scene-transformer.github.io/