 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAMP: Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining
Jan 31, 2026Leveraging pre-trained 2D image representations in behavior cloning policies has achieved great success and has become a standard approach for robotic manipulation. However, such representations fail to capture the 3D spatial information about objects and scenes that is essential for precise manipulation. In this work, we introduce Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining (CLAMP), a novel 3D pre-training framework that utilizes point clouds and robot actions. From the merged point cloud computed from RGB-D images and camera extrinsics, we re-render multi-view four-channel image observations with depth and 3D coordinates, including dynamic wrist views, to provide clearer views of target objects for high-precision manipulation tasks. The pre-trained encoders learn to associate the 3D geometric and positional information of objects with robot action patterns via contrastive learning on large-scale simulated robot trajectories. During encoder pre-training, we pre-train a Diffusion Policy to initialize the policy weights for fine-tuning, which is essential for improving fine-tuning sample efficiency and performance. After pre-training, we fine-tune the policy on a limited amount of task demonstrations using the learned image and action representations. We demonstrate that this pre-training and fine-tuning design substantially improves learning efficiency and policy performance on unseen tasks. Furthermore, we show that CLAMP outperforms state-of-the-art baselines across six simulated tasks and five real-world tasks.
Learning the RoPEs: Better 2D and 3D Position Encodings with STRING
Feb 04, 2025



We introduce STRING: Separable Translationally Invariant Position Encodings. STRING extends Rotary Position Encodings, a recently proposed and widely used algorithm in large language models, via a unifying theoretical framework. Importantly, STRING still provides exact translation invariance, including token coordinates of arbitrary dimensionality, whilst maintaining a low computational footprint. These properties are especially important in robotics, where efficient 3D token representation is key. We integrate STRING into Vision Transformers with RGB(-D) inputs (color plus optional depth), showing substantial gains, e.g. in open-vocabulary object detection and for robotics controllers. We complement our experiments with a rigorous mathematical analysis, proving the universality of our methods.
Linear Transformer Topological Masking with Graph Random Features
Oct 04, 2024



When training transformers on graph-structured data, incorporating information about the underlying topology is crucial for good performance. Topological masking, a type of relative position encoding, achieves this by upweighting or downweighting attention depending on the relationship between the query and keys in a graph. In this paper, we propose to parameterise topological masks as a learnable function of a weighted adjacency matrix -- a novel, flexible approach which incorporates a strong structural inductive bias. By approximating this mask with graph random features (for which we prove the first known concentration bounds), we show how this can be made fully compatible with linear attention, preserving $\mathcal{O}(N)$ time and space complexity with respect to the number of input tokens. The fastest previous alternative was $\mathcal{O}(N \log N)$ and only suitable for specific graphs. Our efficient masking algorithms provide strong performance gains for tasks on image and point cloud data, including with $>30$k nodes.
Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
Jul 10, 2024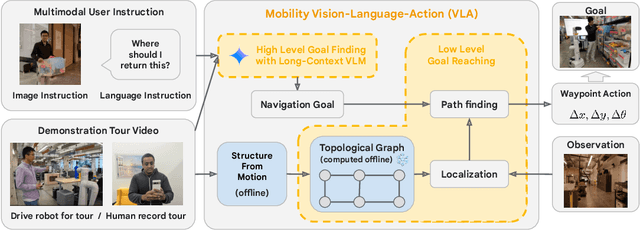
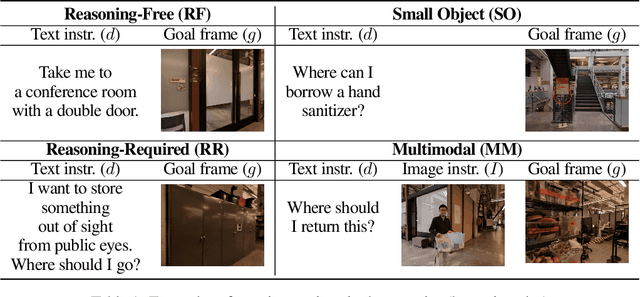


An elusive goal in navigation research is to build an intelligent agent that can understand multimodal instructions including natural language and image, and perform useful navigation. To achieve this, we study a widely useful category of navigation tasks we call Multimodal Instruction Navigation with demonstration Tours (MINT), in which the environment prior is provided through a previously recorded demonstration video. Recent advances in Vision Language Models (VLMs) have shown a promising path in achieving this goal as it demonstrates capabilities in perceiving and reasoning about multimodal inputs. However, VLMs are typically trained to predict textual output and it is an open research question about how to best utilize them in navigation. To solve MINT, we present Mobility VLA, a hierarchical Vision-Language-Action (VLA) navigation policy that combines the environment understanding and common sense reasoning power of long-context VLMs and a robust low-level navigation policy based on topological graphs. The high-level policy consists of a long-context VLM that takes the demonstration tour video and the multimodal user instruction as input to find the goal frame in the tour video. Next, a low-level policy uses the goal frame and an offline constructed topological graph to generate robot actions at every timestep. We evaluated Mobility VLA in a 836m^2 real world environment and show that Mobility VLA has a high end-to-end success rates on previously unsolved multimodal instructions such as "Where should I return this?" while holding a plastic bin.
SPNets: Differentiable Fluid Dynamics for Deep Neural Networks
Sep 26, 2018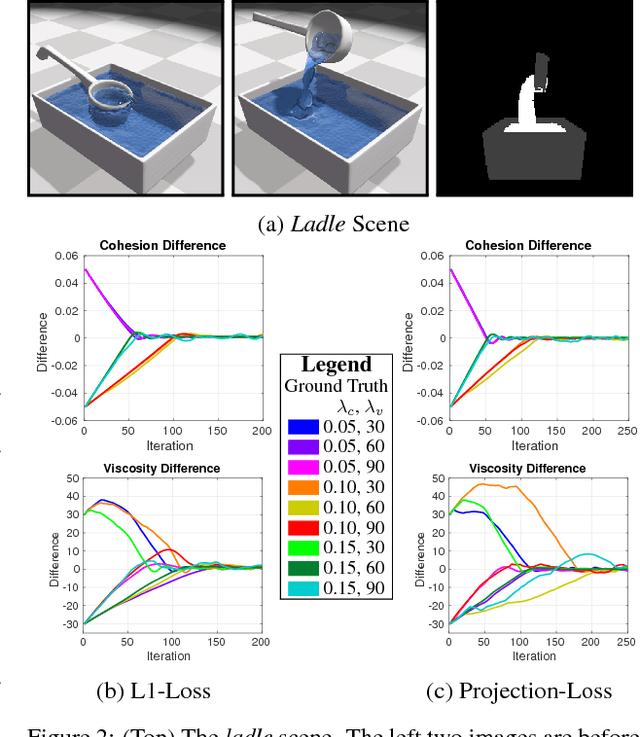
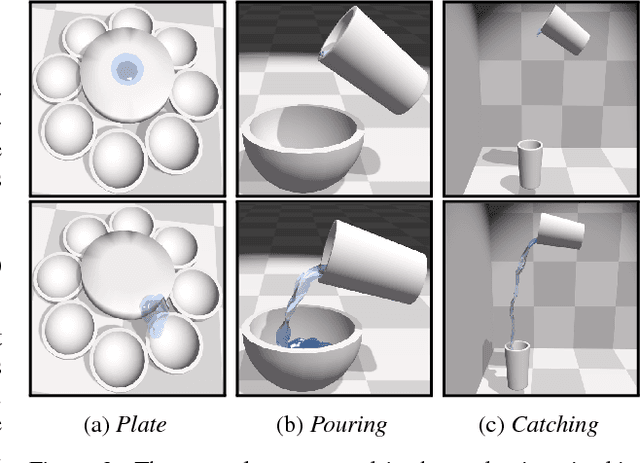
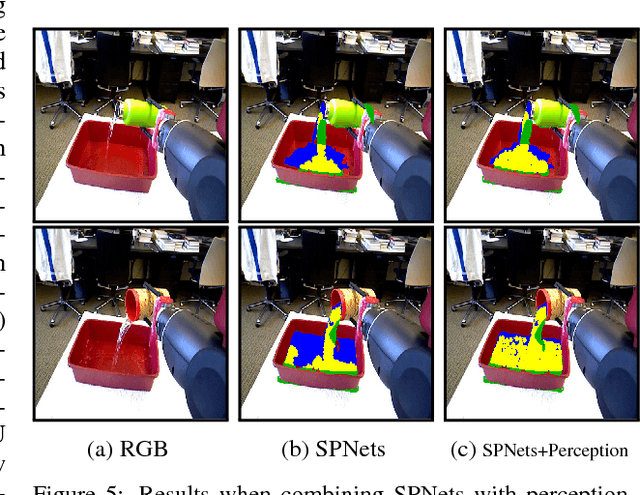
In this paper we introduce Smooth Particle Networks (SPNets), a framework for integrating fluid dynamics with deep networks. SPNets adds two new layers to the neural network toolbox: ConvSP and ConvSDF, which enable computing physical interactions with unordered particle sets. We use these lay- ers in combination with standard neural network layers to directly implement fluid dynamics inside a deep network, where the parameters of the network are the fluid parameters themselves (e.g., viscosity, cohesion, etc.). Because SPNets are imple- mented as a neural network, the resulting fluid dynamics are fully differentiable. We then show how this can be successfully used to learn fluid parameters from data, perform liquid control tasks, and learn policies to manipulate liquids.
Learning Robotic Manipulation of Granular Media
Oct 25, 2017

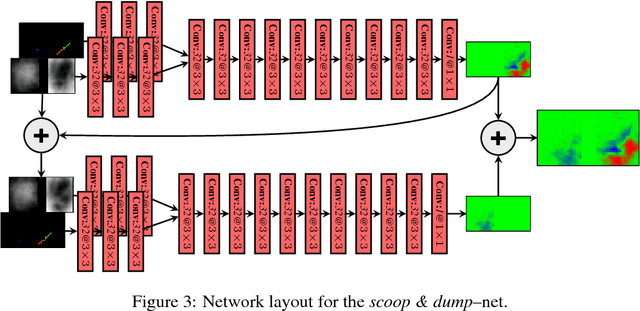
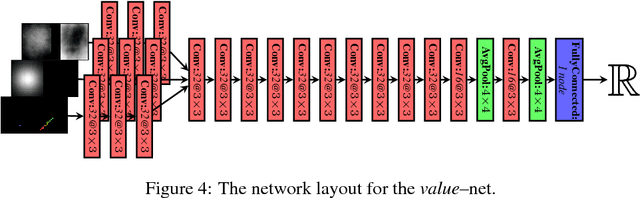
In this paper, we examine the problem of robotic manipulation of granular media. We evaluate multiple predictive models used to infer the dynamics of scooping and dumping actions. These models are evaluated on a task that involves manipulating the media in order to deform it into a desired shape. Our best performing model is based on a highly-tailored convolutional network architecture with domain-specific optimizations, which we show accurately models the physical interaction of the robotic scoop with the underlying media. We empirically demonstrate that explicitly predicting physical mechanics results in a policy that out-performs both a hand-crafted dynamics baseline, and a "value-network", which must otherwise implicitly predict the same mechanics in order to produce accurate value estimates.
Guided Policy Search with Delayed Sensor Measurements
Sep 29, 2017
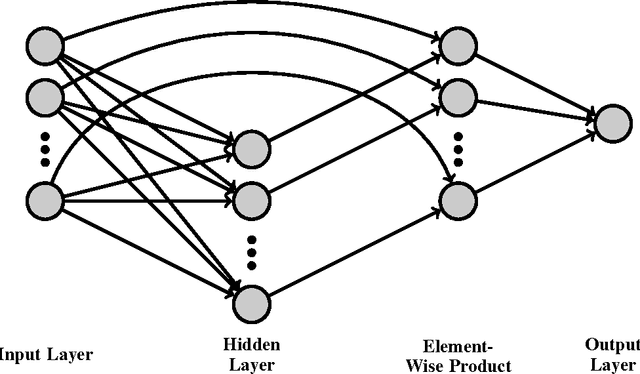

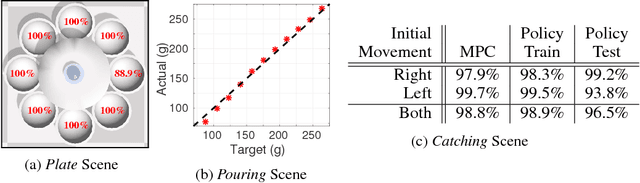
Guided policy search is a method for reinforcement learning that trains a general policy for accomplishing a given task by guiding the learning of the policy with multiple guiding distributions. Guided policy search relies on learning an underlying dynamical model of the environment and then, at each iteration of the algorithm, using that model to gradually improve the policy. This model, though, often makes the assumption that the environment dynamics are markovian, e.g., depend only on the current state and control signal. In this paper we apply guided policy search to a problem with non-markovian dynamics. Specifically, we apply it to the problem of pouring a precise amount of liquid from a cup into a bowl, where many of the sensor measurements experience non-trivial amounts of delay. We show that, with relatively simple state augmentation, guided policy search can be extended to non-markovian dynamical systems, where the non-markovianess is caused by delayed sensor readings.
See the Glass Half Full: Reasoning about Liquid Containers, their Volume and Content
Sep 06, 2017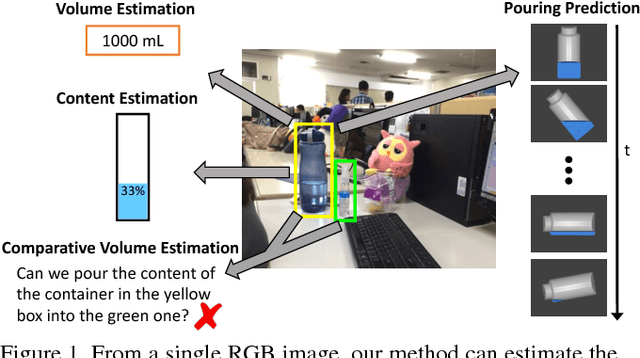
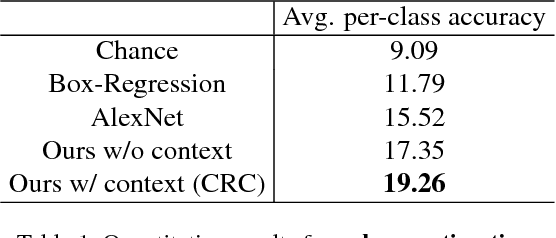
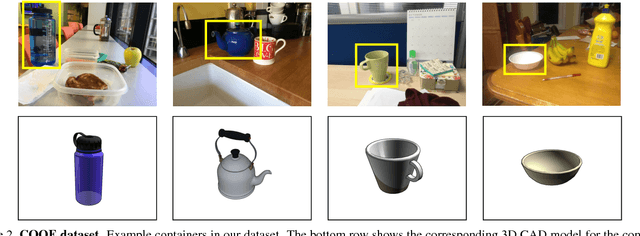

Humans have rich understanding of liquid containers and their contents; for example, we can effortlessly pour water from a pitcher to a cup. Doing so requires estimating the volume of the cup, approximating the amount of water in the pitcher, and predicting the behavior of water when we tilt the pitcher. Very little attention in computer vision has been made to liquids and their containers. In this paper, we study liquid containers and their contents, and propose methods to estimate the volume of containers, approximate the amount of liquid in them, and perform comparative volume estimations all from a single RGB image. Furthermore, we show the results of the proposed model for predicting the behavior of liquids inside containers when one tilts the containers. We also introduce a new dataset of Containers Of liQuid contEnt (COQE) that contains more than 5,000 images of 10,000 liquid containers in context labelled with volume, amount of content, bounding box annotation, and corresponding similar 3D CAD models.
Reasoning About Liquids via Closed-Loop Simulation
Jun 09, 2017

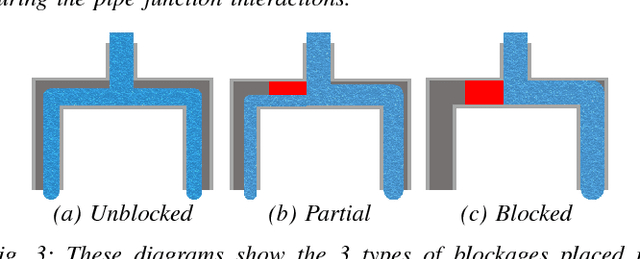

Simulators are powerful tools for reasoning about a robot's interactions with its environment. However, when simulations diverge from reality, that reasoning becomes less useful. In this paper, we show how to close the loop between liquid simulation and real-time perception. We use observations of liquids to correct errors when tracking the liquid's state in a simulator. Our results show that closed-loop simulation is an effective way to prevent large divergence between the simulated and real liquid states. As a direct consequence of this, our method can enable reasoning about liquids that would otherwise be infeasible due to large divergences, such as reasoning about occluded liquid.
Visual Closed-Loop Control for Pouring Liquids
Feb 25, 2017
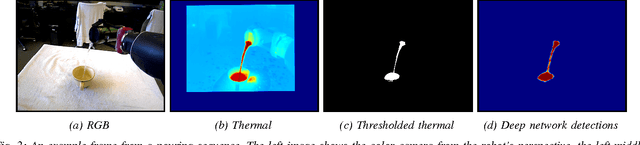
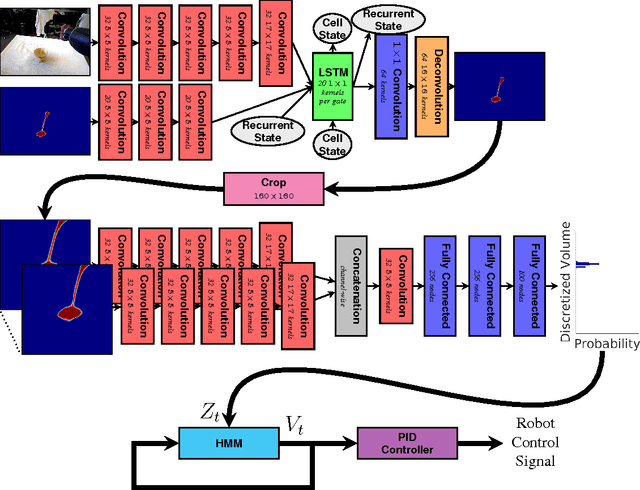
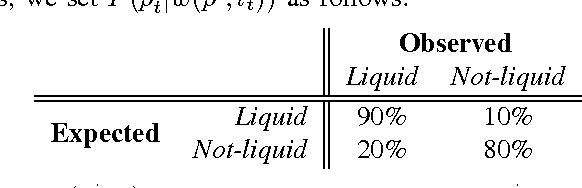
Pouring a specific amount of liquid is a challenging task. In this paper we develop methods for robots to use visual feedback to perform closed-loop control for pouring liquids. We propose both a model-based and a model-free method utilizing deep learning for estimating the volume of liquid in a container. Our results show that the model-free method is better able to estimate the volume. We combine this with a simple PID controller to pour specific amounts of liquid, and show that the robot is able to achieve an average 38ml deviation from the target amount. To our knowledge, this is the first use of raw visual feedback to pour liquids in robotics.