 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAPT: Actively Discovering and Adapting to Preferences for any Task
Apr 05, 2025Assistive agents should be able to perform under-specified long-horizon tasks while respecting user preferences. We introduce Actively Discovering and Adapting to Preferences for any Task (ADAPT) -- a benchmark designed to evaluate agents' ability to adhere to user preferences across various household tasks through active questioning. Next, we propose Reflection-DPO, a novel training approach for adapting large language models (LLMs) to the task of active questioning. Reflection-DPO finetunes a 'student' LLM to follow the actions of a privileged 'teacher' LLM, and optionally ask a question to gather necessary information to better predict the teacher action. We find that prior approaches that use state-of-the-art LLMs fail to sufficiently follow user preferences in ADAPT due to insufficient questioning and poor adherence to elicited preferences. In contrast, Reflection-DPO achieves a higher rate of satisfying user preferences, outperforming a zero-shot chain-of-thought baseline by 6.1% on unseen users.
Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
Apr 02, 2025
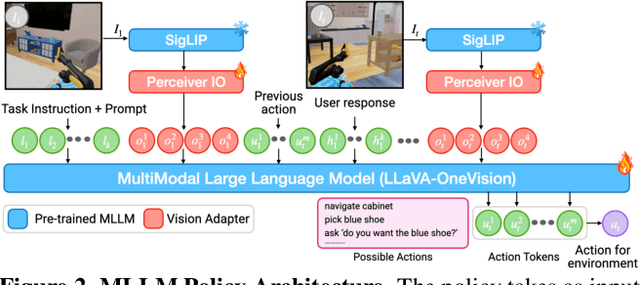
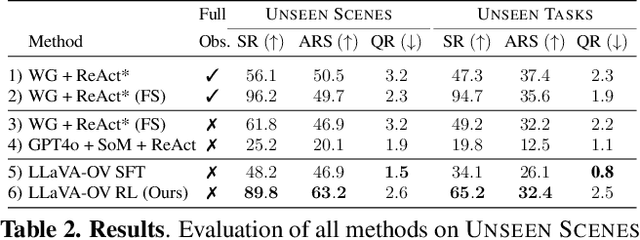
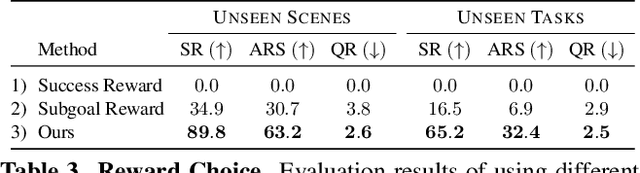
Embodied agents operating in real-world environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent must fetch a specific object instance given an ambiguous instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To solve this problem, we propose a novel approach that fine-tunes multimodal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines, including GPT-4o, and supervised fine-tuned MLLMs, on our task. Our results demonstrate that our RL-finetuned MLLM outperforms all baselines by a significant margin ($19.1$-$40.3\%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
From an Image to a Scene: Learning to Imagine the World from a Million 360 Videos
Dec 10, 2024Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale 360 videos can address these limitations to provide: scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks
Oct 31, 2024
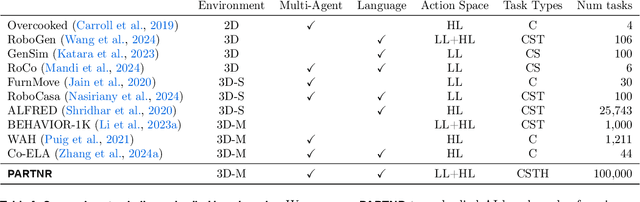

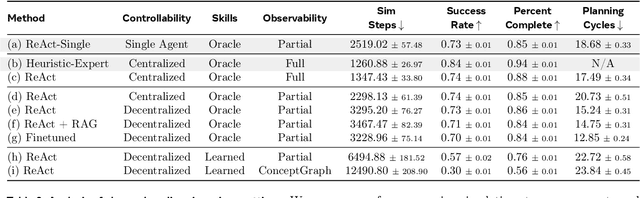
We present a benchmark for Planning And Reasoning Tasks in humaN-Robot collaboration (PARTNR) designed to study human-robot coordination in household activities. PARTNR tasks exhibit characteristics of everyday tasks, such as spatial, temporal, and heterogeneous agent capability constraints. We employ a semi-automated task generation pipeline using Large Language Models (LLMs), incorporating simulation in the loop for grounding and verification. PARTNR stands as the largest benchmark of its kind, comprising 100,000 natural language tasks, spanning 60 houses and 5,819 unique objects. We analyze state-of-the-art LLMs on PARTNR tasks, across the axes of planning, perception and skill execution. The analysis reveals significant limitations in SoTA models, such as poor coordination and failures in task tracking and recovery from errors. When LLMs are paired with real humans, they require 1.5x as many steps as two humans collaborating and 1.1x more steps than a single human, underscoring the potential for improvement in these models. We further show that fine-tuning smaller LLMs with planning data can achieve performance on par with models 9 times larger, while being 8.6x faster at inference. Overall, PARTNR highlights significant challenges facing collaborative embodied agents and aims to drive research in this direction.
Situated Instruction Following
Jul 15, 2024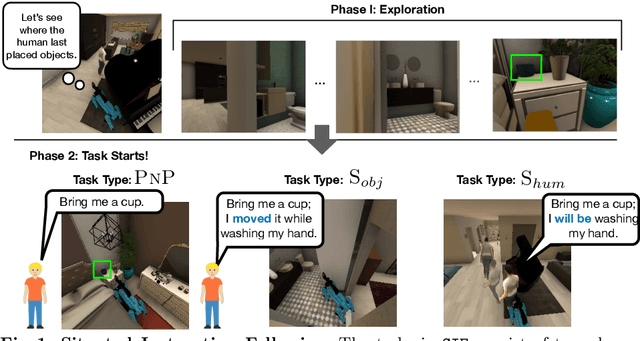
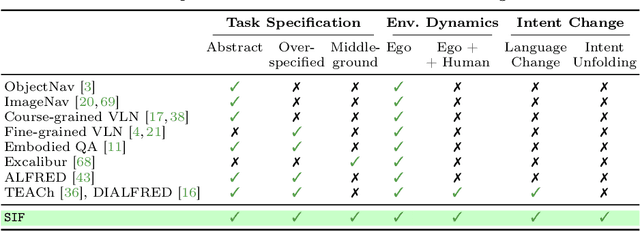
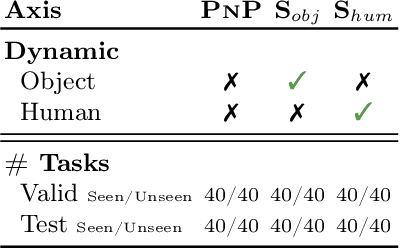
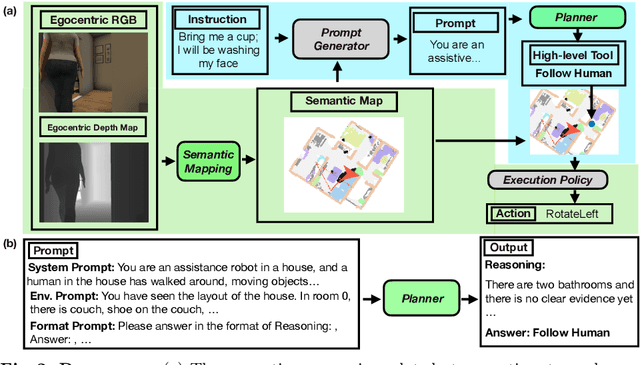
Language is never spoken in a vacuum. It is expressed, comprehended, and contextualized within the holistic backdrop of the speaker's history, actions, and environment. Since humans are used to communicating efficiently with situated language, the practicality of robotic assistants hinge on their ability to understand and act upon implicit and situated instructions. In traditional instruction following paradigms, the agent acts alone in an empty house, leading to language use that is both simplified and artificially "complete." In contrast, we propose situated instruction following, which embraces the inherent underspecification and ambiguity of real-world communication with the physical presence of a human speaker. The meaning of situated instructions naturally unfold through the past actions and the expected future behaviors of the human involved. Specifically, within our settings we have instructions that (1) are ambiguously specified, (2) have temporally evolving intent, (3) can be interpreted more precisely with the agent's dynamic actions. Our experiments indicate that state-of-the-art Embodied Instruction Following (EIF) models lack holistic understanding of situated human intention.
Towards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Track2Act: Predicting Point Tracks from Internet Videos enables Diverse Zero-shot Robot Manipulation
May 02, 2024



We seek to learn a generalizable goal-conditioned policy that enables zero-shot robot manipulation: interacting with unseen objects in novel scenes without test-time adaptation. While typical approaches rely on a large amount of demonstration data for such generalization, we propose an approach that leverages web videos to predict plausible interaction plans and learns a task-agnostic transformation to obtain robot actions in the real world. Our framework,Track2Act predicts tracks of how points in an image should move in future time-steps based on a goal, and can be trained with diverse videos on the web including those of humans and robots manipulating everyday objects. We use these 2D track predictions to infer a sequence of rigid transforms of the object to be manipulated, and obtain robot end-effector poses that can be executed in an open-loop manner. We then refine this open-loop plan by predicting residual actions through a closed loop policy trained with a few embodiment-specific demonstrations. We show that this approach of combining scalably learned track prediction with a residual policy requiring minimal in-domain robot-specific data enables zero-shot robot manipulation, and present a wide array of real-world robot manipulation results across unseen tasks, objects, and scenes. https://homangab.github.io/track2act/
GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation
Apr 09, 2024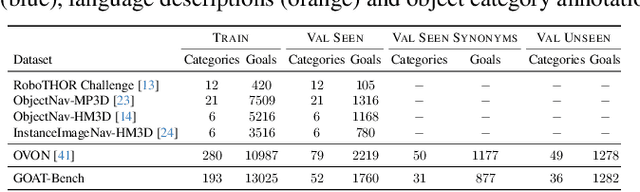

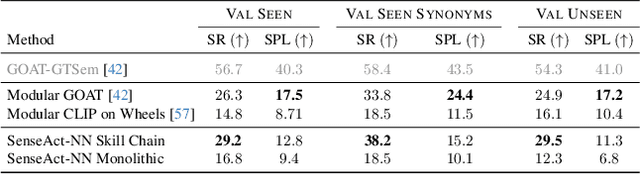
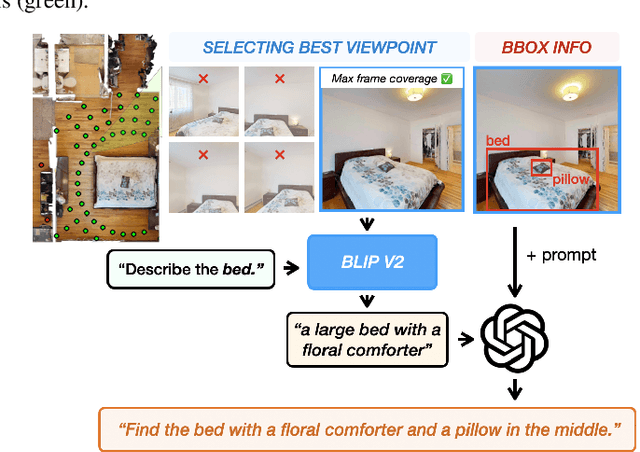
The Embodied AI community has made significant strides in visual navigation tasks, exploring targets from 3D coordinates, objects, language descriptions, and images. However, these navigation models often handle only a single input modality as the target. With the progress achieved so far, it is time to move towards universal navigation models capable of handling various goal types, enabling more effective user interaction with robots. To facilitate this goal, we propose GOAT-Bench, a benchmark for the universal navigation task referred to as GO to AnyThing (GOAT). In this task, the agent is directed to navigate to a sequence of targets specified by the category name, language description, or image in an open-vocabulary fashion. We benchmark monolithic RL and modular methods on the GOAT task, analyzing their performance across modalities, the role of explicit and implicit scene memories, their robustness to noise in goal specifications, and the impact of memory in lifelong scenarios.
Controllable Human-Object Interaction Synthesis
Dec 06, 2023
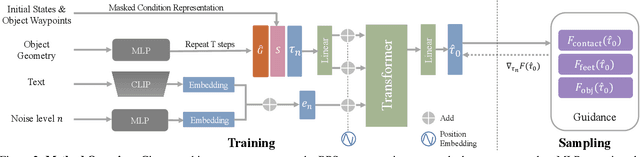
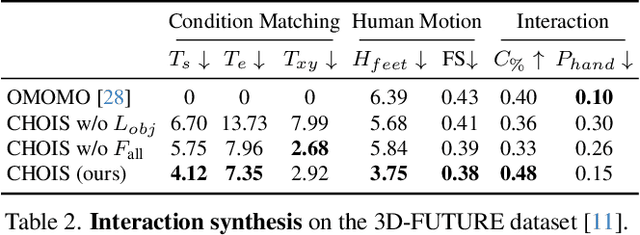
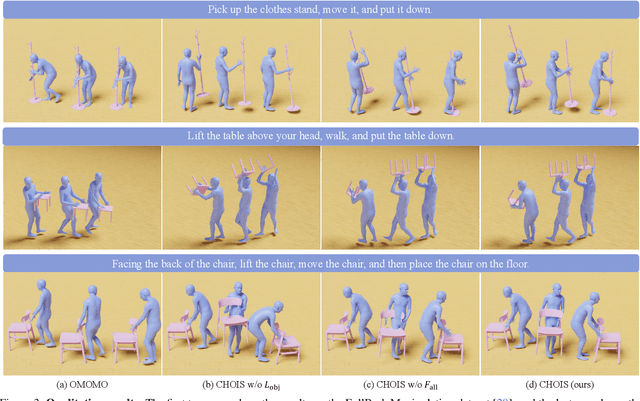
Synthesizing semantic-aware, long-horizon, human-object interaction is critical to simulate realistic human behaviors. In this work, we address the challenging problem of generating synchronized object motion and human motion guided by language descriptions in 3D scenes. We propose Controllable Human-Object Interaction Synthesis (CHOIS), an approach that generates object motion and human motion simultaneously using a conditional diffusion model given a language description, initial object and human states, and sparse object waypoints. While language descriptions inform style and intent, waypoints ground the motion in the scene and can be effectively extracted using high-level planning methods. Naively applying a diffusion model fails to predict object motion aligned with the input waypoints and cannot ensure the realism of interactions that require precise hand-object contact and appropriate contact grounded by the floor. To overcome these problems, we introduce an object geometry loss as additional supervision to improve the matching between generated object motion and input object waypoints. In addition, we design guidance terms to enforce contact constraints during the sampling process of the trained diffusion model.
GOAT: GO to Any Thing
Nov 10, 2023



In deployment scenarios such as homes and warehouses, mobile robots are expected to autonomously navigate for extended periods, seamlessly executing tasks articulated in terms that are intuitively understandable by human operators. We present GO To Any Thing (GOAT), a universal navigation system capable of tackling these requirements with three key features: a) Multimodal: it can tackle goals specified via category labels, target images, and language descriptions, b) Lifelong: it benefits from its past experience in the same environment, and c) Platform Agnostic: it can be quickly deployed on robots with different embodiments. GOAT is made possible through a modular system design and a continually augmented instance-aware semantic memory that keeps track of the appearance of objects from different viewpoints in addition to category-level semantics. This enables GOAT to distinguish between different instances of the same category to enable navigation to targets specified by images and language descriptions. In experimental comparisons spanning over 90 hours in 9 different homes consisting of 675 goals selected across 200+ different object instances, we find GOAT achieves an overall success rate of 83%, surpassing previous methods and ablations by 32% (absolute improvement). GOAT improves with experience in the environment, from a 60% success rate at the first goal to a 90% success after exploration. In addition, we demonstrate that GOAT can readily be applied to downstream tasks such as pick and place and social navigation.