 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoNet: A Large-Scale Dataset for Domain-Specific Action Recognition
May 05, 2026Videos are unique in their ability to capture actions which transcend multiple frames. Accordingly, for many years action recognition was the quintessential task for video understanding. Unfortunately, due to a lack of sufficiently diverse and challenging data, modern vision-language models (VLMs) are no longer evaluated on their action recognition capabilities. To revitalize action recognition in the era of VLMs, we advocate for a returned focus on domain-specific actions. To this end, we introduce VideoNet, a domain-specific action recognition benchmark covering 1,000 distinct actions from 37 domains. We begin with a multiple-choice evaluation setting, where the difference between closed and open models is stark: Gemini 3.1 Pro attains 69.9% accuracy while Qwen3-VL-8B gets a mere 45.0%. To understand why VLMs struggle on VideoNet, we relax the questions into a binary setting, where random chance is 50%. Still, Qwen achieves only 59.2% accuracy. Further relaxing the evaluation setup, we provide $k\in\{1,2,3\}$ in-context examples of the action. Some models excel in the few-shot setting, while others falter; Qwen improves $+7.0\%$, while Gemini declines $-4.8\%$. Notably, these gains fall short of the $+13.6\%$ improvement in non-expert humans when given few-shot examples. Finding that VLMs struggle to fully exploit in-context examples, we shift from test-time improvements to the training side. We collect the first large-scale training dataset for domain-specific actions, totaling nearly 500k video question-answer pairs. Fine-tuning a Molmo2-4B model on our data, we surpass all open-weight 8B models on the VideoNet benchmark.
OmniView: An All-Seeing Diffusion Model for 3D and 4D View Synthesis
Dec 11, 2025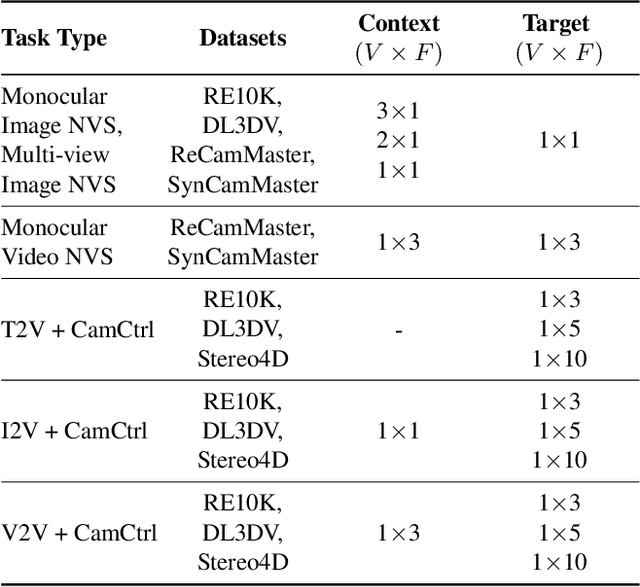
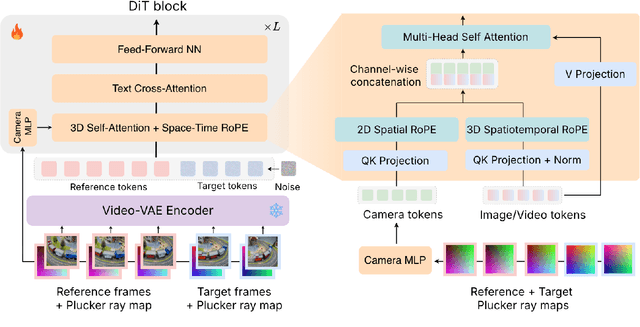
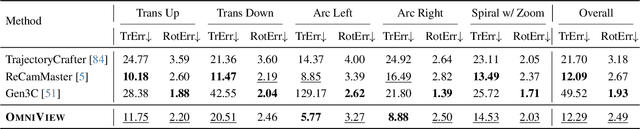

Prior approaches injecting camera control into diffusion models have focused on specific subsets of 4D consistency tasks: novel view synthesis, text-to-video with camera control, image-to-video, amongst others. Therefore, these fragmented approaches are trained on disjoint slices of available 3D/4D data. We introduce OmniView, a unified framework that generalizes across a wide range of 4D consistency tasks. Our method separately represents space, time, and view conditions, enabling flexible combinations of these inputs. For example, OmniView can synthesize novel views from static, dynamic, and multiview inputs, extrapolate trajectories forward and backward in time, and create videos from text or image prompts with full camera control. OmniView is competitive with task-specific models across diverse benchmarks and metrics, improving image quality scores among camera-conditioned diffusion models by up to 33\% in multiview NVS LLFF dataset, 60\% in dynamic NVS Neural 3D Video benchmark, 20\% in static camera control on RE-10K, and reducing camera trajectory errors by 4x in text-conditioned video generation. With strong generalizability in one model, OmniView demonstrates the feasibility of a generalist 4D video model. Project page is available at https://snap-research.github.io/OmniView/
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Contrastive Flow Matching
Jun 05, 2025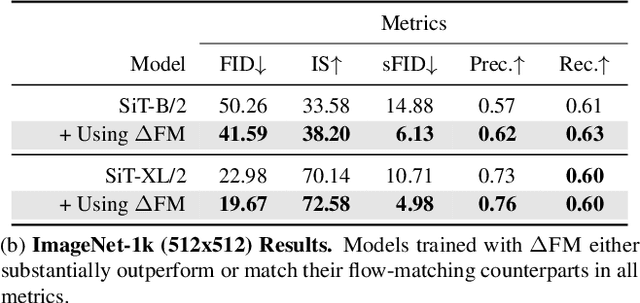

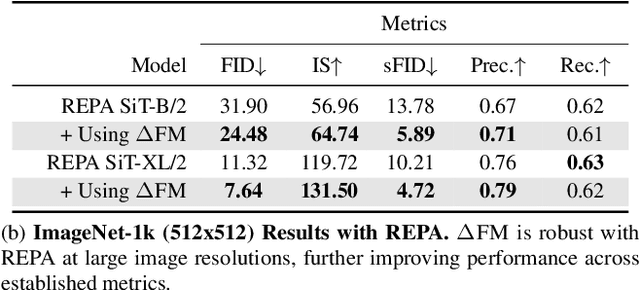
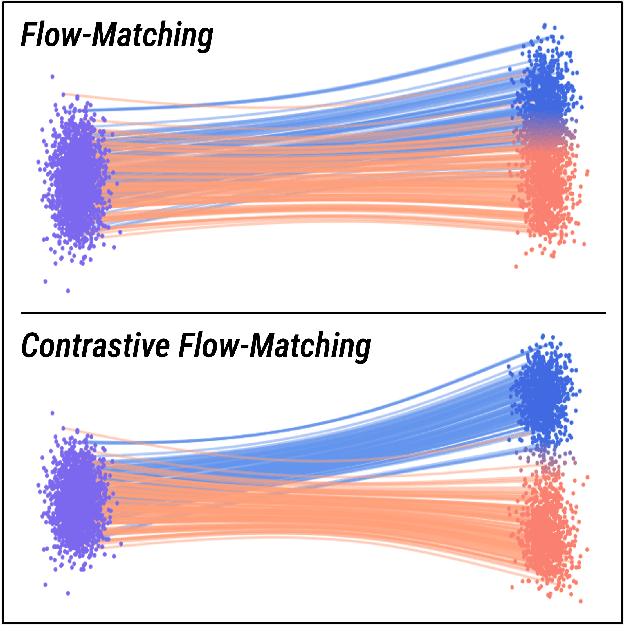
Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed--flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to 9x, (2) requires up to 5x fewer de-noising steps and (3) lowers FID by up to 8.9 compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
When Worse is Better: Navigating the compression-generation tradeoff in visual tokenization
Dec 20, 2024
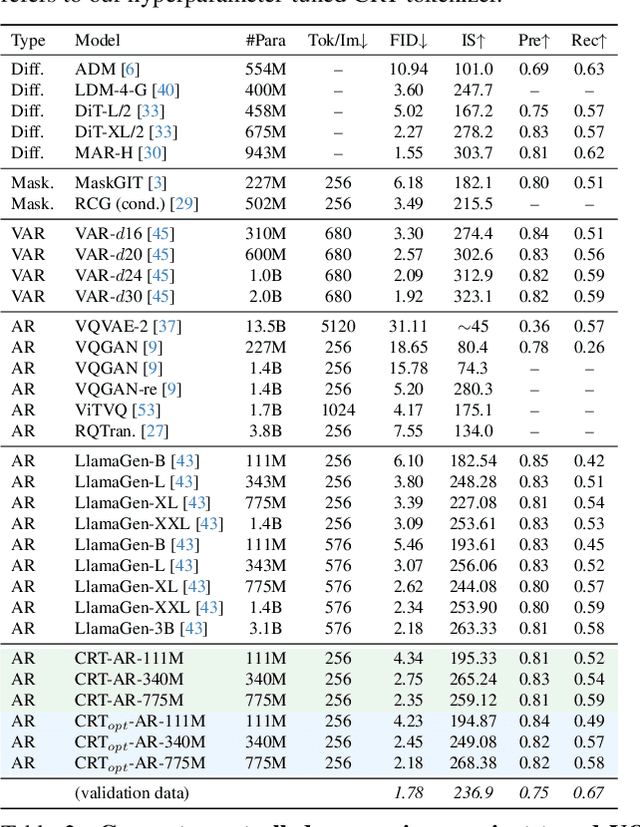

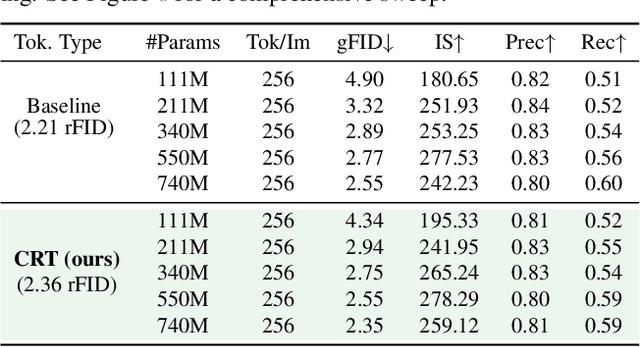
Current image generation methods, such as latent diffusion and discrete token-based generation, depend on a two-stage training approach. In stage 1, an auto-encoder is trained to compress an image into a latent space; in stage 2, a generative model is trained to learn a distribution over that latent space. Most work focuses on maximizing stage 1 performance independent of stage 2, assuming better reconstruction always leads to better generation. However, we show this is not strictly true. Smaller stage 2 models can benefit from more compressed stage 1 latents even if reconstruction performance worsens, showing a fundamental trade-off between compression and generation modeling capacity. To better optimize this trade-off, we introduce Causally Regularized Tokenization (CRT), which uses knowledge of the stage 2 generation modeling procedure to embed useful inductive biases in stage 1 latents. This regularization makes stage 1 reconstruction performance worse, but makes stage 2 generation performance better by making the tokens easier to model: we are able to improve compute efficiency 2-3$\times$ over baseline and match state-of-the-art discrete autoregressive ImageNet generation (2.18 FID) with less than half the tokens per image (256 vs. 576) and a fourth the total model parameters (775M vs. 3.1B) as the previous SOTA (LlamaGen).
From an Image to a Scene: Learning to Imagine the World from a Million 360 Videos
Dec 10, 2024Three-dimensional (3D) understanding of objects and scenes play a key role in humans' ability to interact with the world and has been an active area of research in computer vision, graphics, and robotics. Large scale synthetic and object-centric 3D datasets have shown to be effective in training models that have 3D understanding of objects. However, applying a similar approach to real-world objects and scenes is difficult due to a lack of large-scale data. Videos are a potential source for real-world 3D data, but finding diverse yet corresponding views of the same content has shown to be difficult at scale. Furthermore, standard videos come with fixed viewpoints, determined at the time of capture. This restricts the ability to access scenes from a variety of more diverse and potentially useful perspectives. We argue that large scale 360 videos can address these limitations to provide: scalable corresponding frames from diverse views. In this paper, we introduce 360-1M, a 360 video dataset, and a process for efficiently finding corresponding frames from diverse viewpoints at scale. We train our diffusion-based model, Odin, on 360-1M. Empowered by the largest real-world, multi-view dataset to date, Odin is able to freely generate novel views of real-world scenes. Unlike previous methods, Odin can move the camera through the environment, enabling the model to infer the geometry and layout of the scene. Additionally, we show improved performance on standard novel view synthesis and 3D reconstruction benchmarks.
The Unmet Promise of Synthetic Training Images: Using Retrieved Real Images Performs Better
Jun 07, 2024Generative text-to-image models enable us to synthesize unlimited amounts of images in a controllable manner, spurring many recent efforts to train vision models with synthetic data. However, every synthetic image ultimately originates from the upstream data used to train the generator. What additional value does the intermediate generator provide over directly training on relevant parts of the upstream data? Grounding this question in the setting of image classification, we compare finetuning on task-relevant, targeted synthetic data generated by Stable Diffusion -- a generative model trained on the LAION-2B dataset -- against finetuning on targeted real images retrieved directly from LAION-2B. We show that while synthetic data can benefit some downstream tasks, it is universally matched or outperformed by real data from our simple retrieval baseline. Our analysis suggests that this underperformance is partially due to generator artifacts and inaccurate task-relevant visual details in the synthetic images. Overall, we argue that retrieval is a critical baseline to consider when training with synthetic data -- a baseline that current methods do not yet surpass. We release code, data, and models at https://github.com/scottgeng00/unmet-promise.
On the Connection between Pre-training Data Diversity and Fine-tuning Robustness
Jul 24, 2023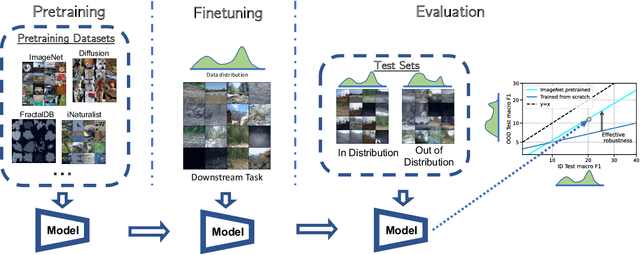

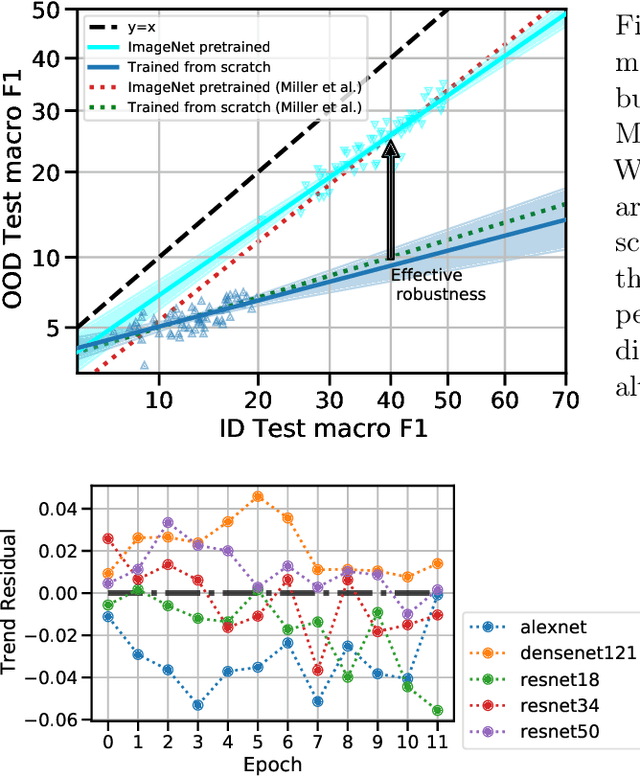

Pre-training has been widely adopted in deep learning to improve model performance, especially when the training data for a target task is limited. In our work, we seek to understand the implications of this training strategy on the generalization properties of downstream models. More specifically, we ask the following question: how do properties of the pre-training distribution affect the robustness of a fine-tuned model? The properties we explore include the label space, label semantics, image diversity, data domains, and data quantity of the pre-training distribution. We find that the primary factor influencing downstream effective robustness (Taori et al., 2020) is data quantity, while other factors have limited significance. For example, reducing the number of ImageNet pre-training classes by 4x while increasing the number of images per class by 4x (that is, keeping total data quantity fixed) does not impact the robustness of fine-tuned models. We demonstrate our findings on pre-training distributions drawn from various natural and synthetic data sources, primarily using the iWildCam-WILDS distribution shift as a test for downstream robustness.
Neural Priming for Sample-Efficient Adaptation
Jun 24, 2023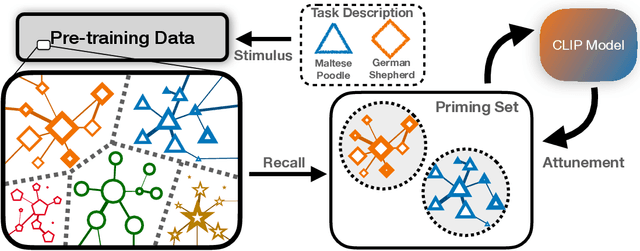
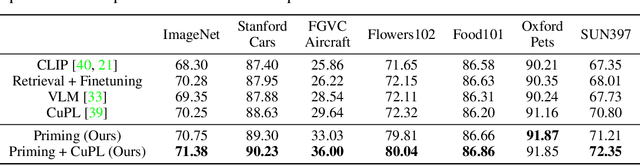
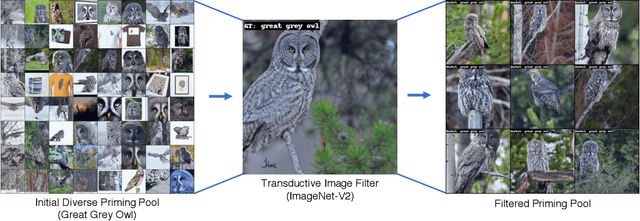
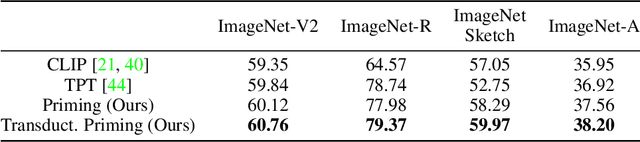
We propose Neural Priming, a technique for adapting large pretrained models to distribution shifts and downstream tasks given few or no labeled examples. Presented with class names or unlabeled test samples, Neural Priming enables the model to recall and conditions its parameters on relevant data seen throughout pretraining, thereby priming it for the test distribution. Neural Priming can be performed at test time, even for pretraining datasets as large as LAION-2B. Performing lightweight updates on the recalled data significantly improves accuracy across a variety of distribution shift and transfer learning benchmarks. Concretely, in the zero-shot setting, we see a 2.45% improvement in accuracy on ImageNet and 3.81% accuracy improvement on average across standard transfer learning benchmarks. Further, using Neural Priming at inference to adapt to distribution shift, we see a 1.41% accuracy improvement on ImageNetV2. These results demonstrate the effectiveness of Neural Priming in addressing the challenge of limited labeled data and changing distributions. Code is available at github.com/RAIVNLab/neural-priming.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.