 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Worse is Better: Navigating the compression-generation tradeoff in visual tokenization
Paper and Code
Dec 20, 2024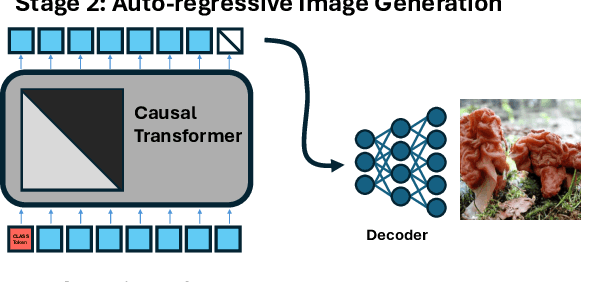
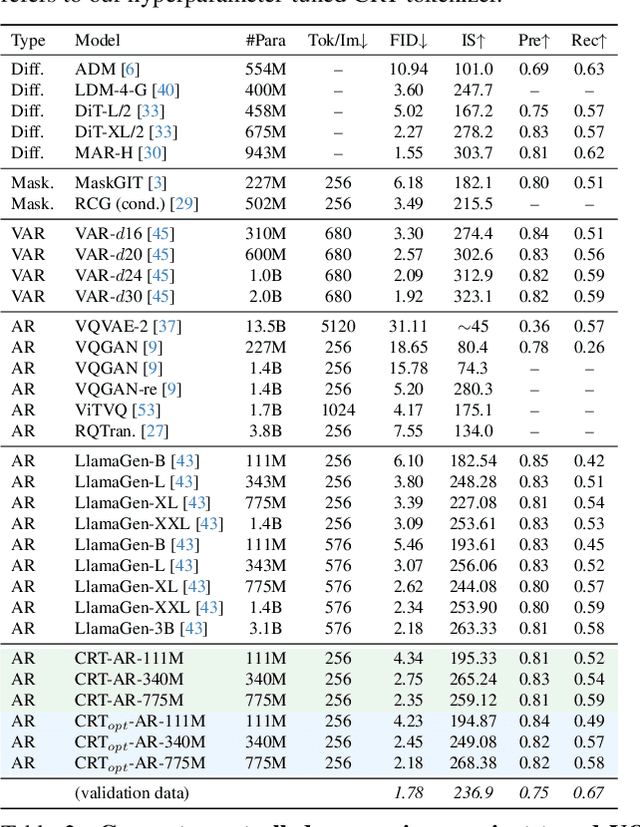

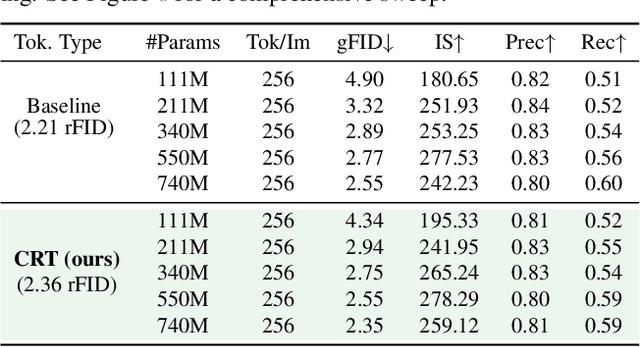
Current image generation methods, such as latent diffusion and discrete token-based generation, depend on a two-stage training approach. In stage 1, an auto-encoder is trained to compress an image into a latent space; in stage 2, a generative model is trained to learn a distribution over that latent space. Most work focuses on maximizing stage 1 performance independent of stage 2, assuming better reconstruction always leads to better generation. However, we show this is not strictly true. Smaller stage 2 models can benefit from more compressed stage 1 latents even if reconstruction performance worsens, showing a fundamental trade-off between compression and generation modeling capacity. To better optimize this trade-off, we introduce Causally Regularized Tokenization (CRT), which uses knowledge of the stage 2 generation modeling procedure to embed useful inductive biases in stage 1 latents. This regularization makes stage 1 reconstruction performance worse, but makes stage 2 generation performance better by making the tokens easier to model: we are able to improve compute efficiency 2-3$\times$ over baseline and match state-of-the-art discrete autoregressive ImageNet generation (2.18 FID) with less than half the tokens per image (256 vs. 576) and a fourth the total model parameters (775M vs. 3.1B) as the previous SOTA (LlamaGen).