 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
CAT: Content-Adaptive Image Tokenization
Jan 06, 2025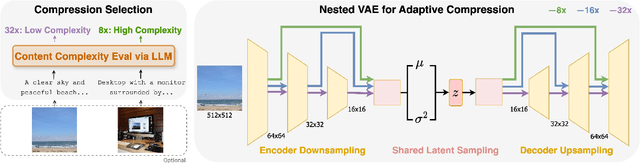



Most existing image tokenizers encode images into a fixed number of tokens or patches, overlooking the inherent variability in image complexity. To address this, we introduce Content-Adaptive Tokenizer (CAT), which dynamically adjusts representation capacity based on the image content and encodes simpler images into fewer tokens. We design a caption-based evaluation system that leverages large language models (LLMs) to predict content complexity and determine the optimal compression ratio for a given image, taking into account factors critical to human perception. Trained on images with diverse compression ratios, CAT demonstrates robust performance in image reconstruction. We also utilize its variable-length latent representations to train Diffusion Transformers (DiTs) for ImageNet generation. By optimizing token allocation, CAT improves the FID score over fixed-ratio baselines trained with the same flops and boosts the inference throughput by 18.5%.
When Worse is Better: Navigating the compression-generation tradeoff in visual tokenization
Dec 20, 2024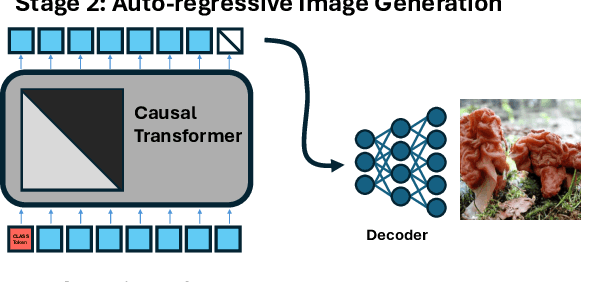
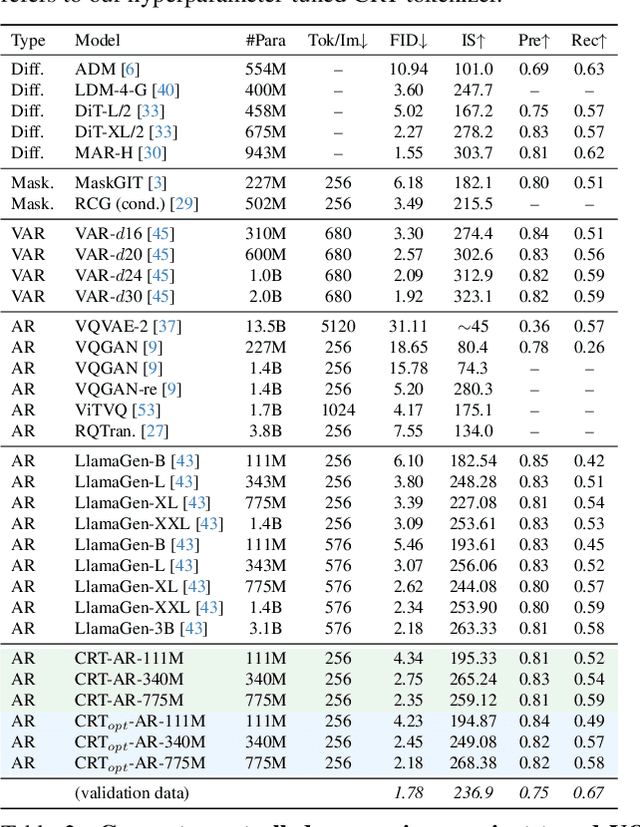

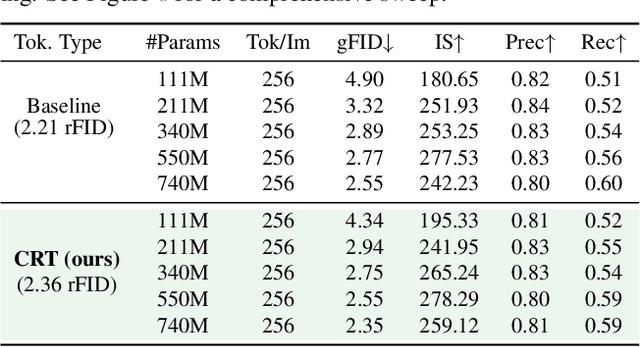
Current image generation methods, such as latent diffusion and discrete token-based generation, depend on a two-stage training approach. In stage 1, an auto-encoder is trained to compress an image into a latent space; in stage 2, a generative model is trained to learn a distribution over that latent space. Most work focuses on maximizing stage 1 performance independent of stage 2, assuming better reconstruction always leads to better generation. However, we show this is not strictly true. Smaller stage 2 models can benefit from more compressed stage 1 latents even if reconstruction performance worsens, showing a fundamental trade-off between compression and generation modeling capacity. To better optimize this trade-off, we introduce Causally Regularized Tokenization (CRT), which uses knowledge of the stage 2 generation modeling procedure to embed useful inductive biases in stage 1 latents. This regularization makes stage 1 reconstruction performance worse, but makes stage 2 generation performance better by making the tokens easier to model: we are able to improve compute efficiency 2-3$\times$ over baseline and match state-of-the-art discrete autoregressive ImageNet generation (2.18 FID) with less than half the tokens per image (256 vs. 576) and a fourth the total model parameters (775M vs. 3.1B) as the previous SOTA (LlamaGen).
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Aug 20, 2024



We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. We pretrain multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens. By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches. We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.
Brevity is the soul of wit: Pruning long files for code generation
Jun 29, 2024


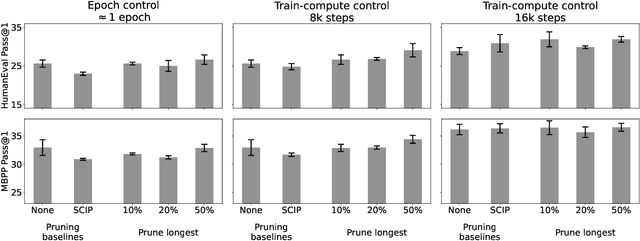
Data curation is commonly considered a "secret-sauce" for LLM training, with higher quality data usually leading to better LLM performance. Given the scale of internet-scraped corpora, data pruning has become a larger and larger focus. Specifically, many have shown that de-duplicating data, or sub-selecting higher quality data, can lead to efficiency or performance improvements. Generally, three types of methods are used to filter internet-scale corpora: embedding-based, heuristic-based, and classifier-based. In this work, we contrast the former two in the domain of finetuning LLMs for code generation. We find that embedding-based methods are often confounded by length, and that a simple heuristic--pruning long files--outperforms other methods in compute-limited regimes. Our method can yield up to a 2x efficiency benefit in training (while matching performance) or a 3.5% absolute performance improvement on HumanEval (while matching compute). However, we find that perplexity on held-out long files can increase, begging the question of whether optimizing data mixtures for common coding benchmarks (HumanEval, MBPP) actually best serves downstream use cases. Overall, we hope our work builds useful intuitions about code data (specifically, the low quality of extremely long code files) provides a compelling heuristic-based method for data pruning, and brings to light questions in how we evaluate code generation models.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Text Quality-Based Pruning for Efficient Training of Language Models
Apr 26, 2024



In recent times training Language Models (LMs) have relied on computationally heavy training over massive datasets which makes this training process extremely laborious. In this paper we propose a novel method for numerically evaluating text quality in large unlabelled NLP datasets in a model agnostic manner to assign the text instances a "quality score". By proposing the text quality metric, the paper establishes a framework to identify and eliminate low-quality text instances, leading to improved training efficiency for LM models. Experimental results over multiple models and datasets demonstrate the efficacy of this approach, showcasing substantial gains in training effectiveness and highlighting the potential for resource-efficient LM training. For example, we observe an absolute accuracy improvement of 0.9% averaged over 14 downstream evaluation tasks for multiple LM models while using 40% lesser data and training 42% faster when training on the OpenWebText dataset and 0.8% average absolute accuracy improvement while using 20% lesser data and training 21% faster on the Wikipedia dataset.
The Unreasonable Ineffectiveness of the Deeper Layers
Mar 26, 2024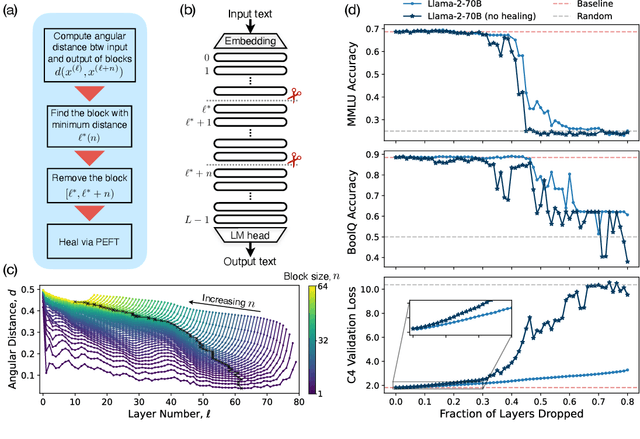
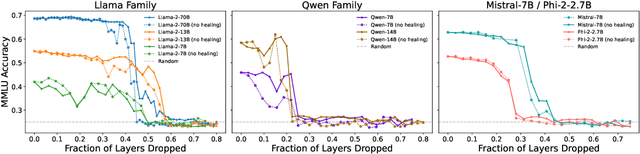
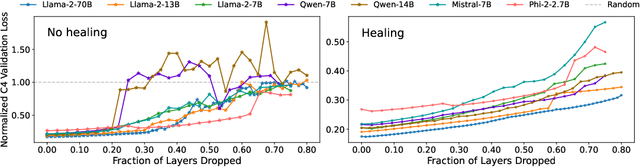
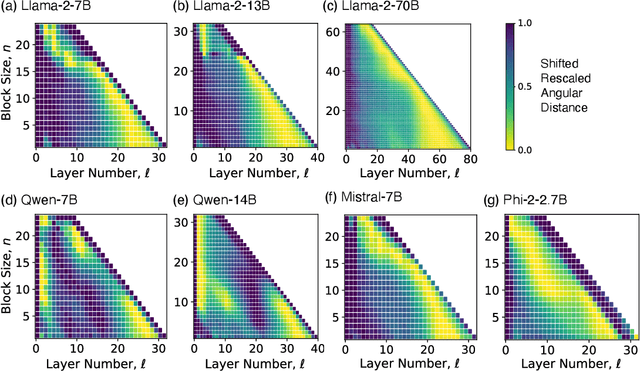
We empirically study a simple layer-pruning strategy for popular families of open-weight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until after a large fraction (up to half) of the layers are removed. To prune these models, we identify the optimal block of layers to prune by considering similarity across layers; then, to "heal" the damage, we perform a small amount of finetuning. In particular, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single A100 GPU. From a practical perspective, these results suggest that layer pruning methods can complement other PEFT strategies to further reduce computational resources of finetuning on the one hand, and can improve the memory and latency of inference on the other hand. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge.
Effective pruning of web-scale datasets based on complexity of concept clusters
Jan 09, 2024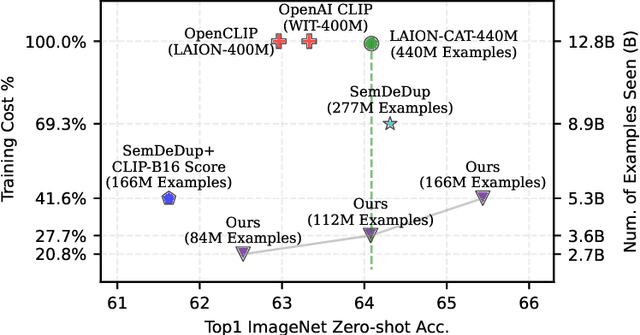
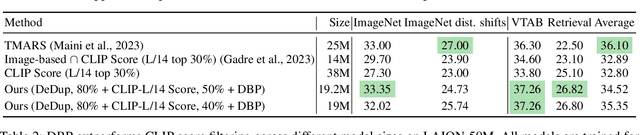
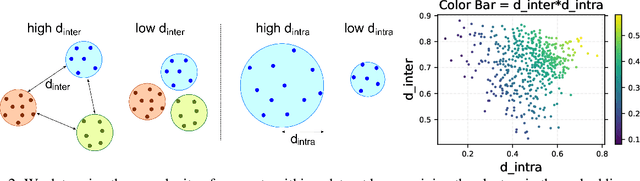

Utilizing massive web-scale datasets has led to unprecedented performance gains in machine learning models, but also imposes outlandish compute requirements for their training. In order to improve training and data efficiency, we here push the limits of pruning large-scale multimodal datasets for training CLIP-style models. Today's most effective pruning method on ImageNet clusters data samples into separate concepts according to their embedding and prunes away the most prototypical samples. We scale this approach to LAION and improve it by noting that the pruning rate should be concept-specific and adapted to the complexity of the concept. Using a simple and intuitive complexity measure, we are able to reduce the training cost to a quarter of regular training. By filtering from the LAION dataset, we find that training on a smaller set of high-quality data can lead to higher performance with significantly lower training costs. More specifically, we are able to outperform the LAION-trained OpenCLIP-ViT-B32 model on ImageNet zero-shot accuracy by 1.1p.p. while only using 27.7% of the data and training compute. Despite a strong reduction in training cost, we also see improvements on ImageNet dist. shifts, retrieval tasks and VTAB. On the DataComp Medium benchmark, we achieve a new state-of-the-art ImageNet zero-shot accuracy and a competitive average zero-shot accuracy on 38 evaluation tasks.
Decoding Data Quality via Synthetic Corruptions: Embedding-guided Pruning of Code Data
Dec 05, 2023Code datasets, often collected from diverse and uncontrolled sources such as GitHub, potentially suffer from quality issues, thereby affecting the performance and training efficiency of Large Language Models (LLMs) optimized for code generation. Previous studies demonstrated the benefit of using embedding spaces for data pruning, but they mainly focused on duplicate removal or increasing variety, and in other modalities, such as images. Our work focuses on using embeddings to identify and remove "low-quality" code data. First, we explore features of "low-quality" code in embedding space, through the use of synthetic corruptions. Armed with this knowledge, we devise novel pruning metrics that operate in embedding space to identify and remove low-quality entries in the Stack dataset. We demonstrate the benefits of this synthetic corruption informed pruning (SCIP) approach on the well-established HumanEval and MBPP benchmarks, outperforming existing embedding-based methods. Importantly, we achieve up to a 3% performance improvement over no pruning, thereby showing the promise of insights from synthetic corruptions for data pruning.