 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Text Quality-Based Pruning for Efficient Training of Language Models
Apr 26, 2024



In recent times training Language Models (LMs) have relied on computationally heavy training over massive datasets which makes this training process extremely laborious. In this paper we propose a novel method for numerically evaluating text quality in large unlabelled NLP datasets in a model agnostic manner to assign the text instances a "quality score". By proposing the text quality metric, the paper establishes a framework to identify and eliminate low-quality text instances, leading to improved training efficiency for LM models. Experimental results over multiple models and datasets demonstrate the efficacy of this approach, showcasing substantial gains in training effectiveness and highlighting the potential for resource-efficient LM training. For example, we observe an absolute accuracy improvement of 0.9% averaged over 14 downstream evaluation tasks for multiple LM models while using 40% lesser data and training 42% faster when training on the OpenWebText dataset and 0.8% average absolute accuracy improvement while using 20% lesser data and training 21% faster on the Wikipedia dataset.
Demystifying CLIP Data
Oct 02, 2023

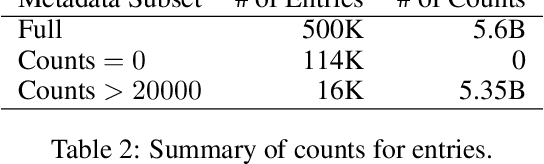

Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
Sep 05, 2023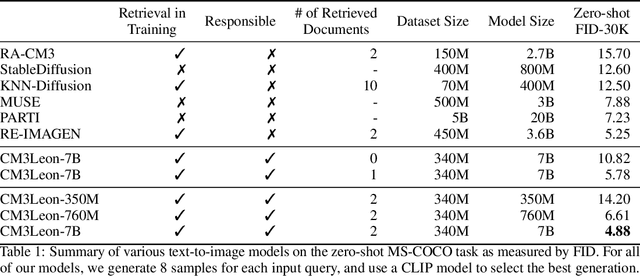

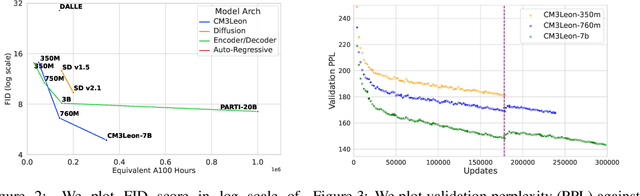

We present CM3Leon (pronounced "Chameleon"), a retrieval-augmented, token-based, decoder-only multi-modal language model capable of generating and infilling both text and images. CM3Leon uses the CM3 multi-modal architecture but additionally shows the extreme benefits of scaling up and tuning on more diverse instruction-style data. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pre-training stage and a second multi-task supervised fine-tuning (SFT) stage. It is also a general-purpose model that can do both text-to-image and image-to-text generation, allowing us to introduce self-contained contrastive decoding methods that produce high-quality outputs. Extensive experiments demonstrate that this recipe is highly effective for multi-modal models. CM3Leon achieves state-of-the-art performance in text-to-image generation with 5x less training compute than comparable methods (zero-shot MS-COCO FID of 4.88). After SFT, CM3Leon can also demonstrate unprecedented levels of controllability in tasks ranging from language-guided image editing to image-controlled generation and segmentation.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
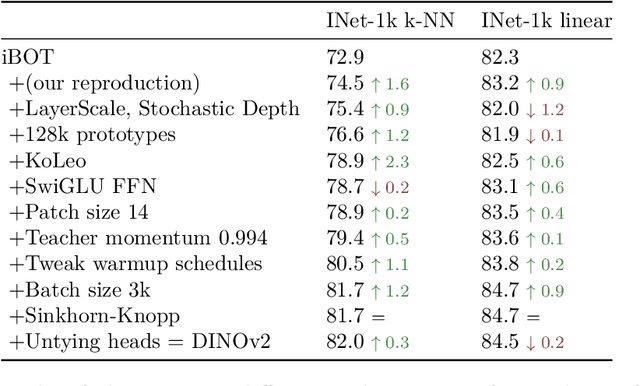
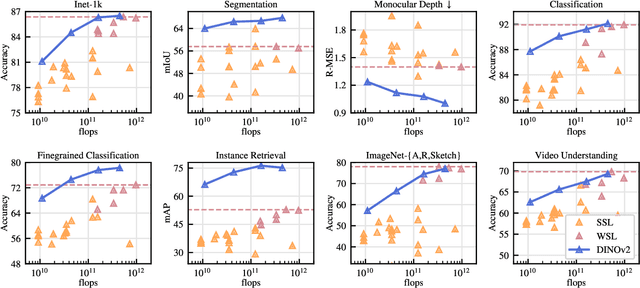
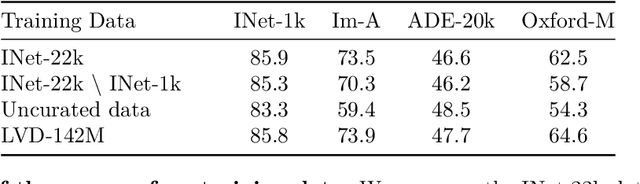
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.
CiT: Curation in Training for Effective Vision-Language Data
Jan 05, 2023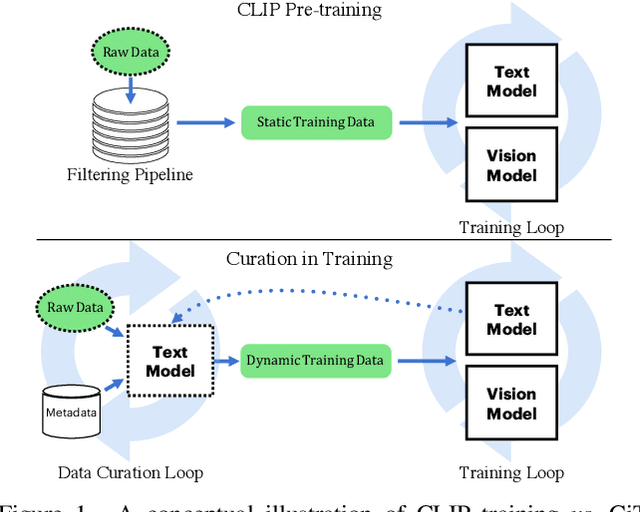


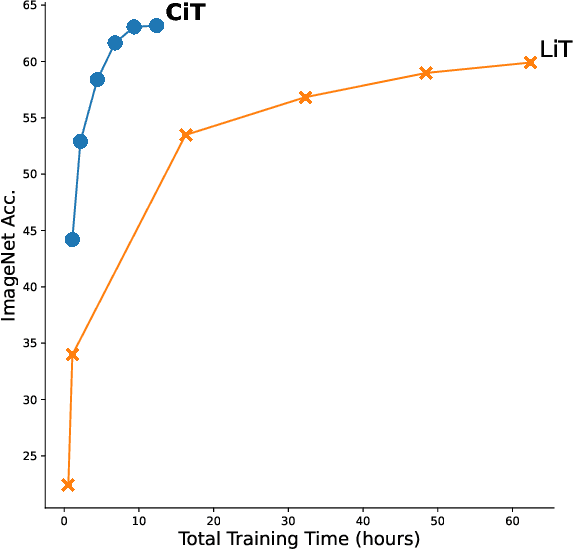
Large vision-language models are generally applicable to many downstream tasks, but come at an exorbitant training cost that only large institutions can afford. This paper trades generality for efficiency and presents Curation in Training (CiT), a simple and efficient vision-text learning algorithm that couples a data objective into training. CiT automatically yields quality data to speed-up contrastive image-text training and alleviates the need for an offline data filtering pipeline, allowing broad data sources (including raw image-text pairs from the web). CiT contains two loops: an outer loop curating the training data and an inner loop consuming the curated training data. The text encoder connects the two loops. Given metadata for tasks of interest, e.g., class names, and a large pool of image-text pairs, CiT alternatively selects relevant training data from the pool by measuring the similarity of their text embeddings and embeddings of the metadata. In our experiments, we observe that CiT can speed up training by over an order of magnitude, especially if the raw data size is large.