 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanistic origins of catastrophic forgetting: why RL preserves circuits better than SFT?
May 21, 2026Fine-tuning large language models (LLMs) frequently induces catastrophic forgetting of prior capabilities. Recent work has shown that reinforcement learning (RL) retains prior capabilities more effectively than supervised fine-tuning (SFT), attributing this to policy-gradient updates remaining closer to the base policy \cite{shenfeld2025rl}. We extend this behavioral account to the mechanistic level and ask whether RL's advantage is mirrored by stronger preservation of internal computational circuits. We introduce differential circuit vulnerability, a head-level measure of how much a circuit degrades under fine-tuning, and use it to compare RL and SFT on Qwen2.5-3B-Instruct adapted to scientific question-answering. We find a clear mechanistic trade-off: SFT adapts more rapidly to the target task but produces substantially greater circuit disruption and forgetting of prior capabilities, whereas RL preserves a larger fraction of the base circuit at the cost of slower task adaptation. These findings suggest that circuit preservation may help explain why RL is more robust to catastrophic forgetting. We released our code here: https://github.com/rl-sft-circuit-research/differential-circuit-vulnerability.
Findings of the Counter Turing Test: AI-Generated Image Detection
May 21, 2026The rapid advancements in generative AI technologies, such as Stable Diffusion, DALL-E, and Midjourney, have significantly transformed the creation of synthetic visual content. While these models enable innovation across industries, they also pose serious challenges, including misinformation, disinformation, and biased content generation. The increasing realism of AI-generated images makes their detection a pressing concern for researchers, policymakers, and industry stakeholders. In this paper, we present the findings of the Defactify 4.0 workshop, which introduced the Counter Turing Test (CT2) for AI-Generated Image Detection. The competition consisted of two key tasks: (1) binary classification of images as either AI-generated or real and (2) identification of the specific generative model responsible for an AI-generated image. To facilitate this, we developed the MS COCOAI dataset, consisting of 50,000 synthetic images from multiple generative models alongside real-world images from the MS COCO dataset. Participants employed diverse detection strategies, including convolutional neural networks (CNNs), Vision Transformers (ViTs), frequency-based analysis, contrastive learning, and multimodal techniques. The results demonstrated that while AI-generated images can be detected with high accuracy (F1-score > 0.83), identifying the exact model used remains significantly more challenging (highest F1-score: 0.4986). These findings highlight the need for improved model fingerprinting, adversarial robustness, and real-time detection mechanisms.
Playing Devil's Advocate: Off-the-Shelf Persona Vectors Rival Targeted Steering for Sycophancy
May 20, 2026We study the effect of different persona on \textbf{sycophancy}: model's agreement with users even when the user is incorrect. The standard mitigation, Contrastive Activation Addition (CAA), derives a steering direction from labelled pairs of sycophantic and honest responses. This study evaluates whether off-the-shelf persona steering vectors, originally developed for general role-playing and not trained on sycophancy data, can serve as an alternative. In two instruction-tuned models, steering toward personas characterised by doubt or scrutiny reduces sycophancy to approximately $68\%$ and $98\%$ of CAA's effect, and, unlike CAA, maintains accuracy when the user is correct. The effect is also asymmetric: steering toward agreeable personas does not produce a mirror increase in sycophancy. Geometrically, the persona vector is largely independent of the direction of sycophancy in activation space. Collectively, these findings suggest that sycophancy is better understood as a persona-level property rather than a single steerable direction. We release our code here: https://anonymous.4open.science/r/Sycophancy-Steering-9DF0/.
ProMoral-Bench: Evaluating Prompting Strategies for Moral Reasoning and Safety in LLMs
Feb 05, 2026Prompt design significantly impacts the moral competence and safety alignment of large language models (LLMs), yet empirical comparisons remain fragmented across datasets and models.We introduce ProMoral-Bench, a unified benchmark evaluating 11 prompting paradigms across four LLM families. Using ETHICS, Scruples, WildJailbreak, and our new robustness test, ETHICS-Contrast, we measure performance via our proposed Unified Moral Safety Score (UMSS), a metric balancing accuracy and safety. Our results show that compact, exemplar-guided scaffolds outperform complex multi-stage reasoning, providing higher UMSS scores and greater robustness at a lower token cost. While multi-turn reasoning proves fragile under perturbations, few-shot exemplars consistently enhance moral stability and jailbreak resistance. ProMoral-Bench establishes a standardized framework for principled, cost-effective prompt engineering.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Reasoning Relay: Evaluating Stability and Interchangeability of Large Language Models in Mathematical Reasoning
Dec 16, 2025Chain-of-Thought (CoT) prompting has significantly advanced the reasoning capabilities of large language models (LLMs). While prior work focuses on improving model performance through internal reasoning strategies, little is known about the interchangeability of reasoning across different models. In this work, we explore whether a partially completed reasoning chain from one model can be reliably continued by another model, either within the same model family or across families. We achieve this by assessing the sufficiency of intermediate reasoning traces as transferable scaffolds for logical coherence and final answer accuracy. We interpret this interchangeability as a means of examining inference-time trustworthiness, probing whether reasoning remains both coherent and reliable under model substitution. Using token-level log-probability thresholds to truncate reasoning at early, mid, and late stages from our baseline models, Gemma-3-4B-IT and LLaMA-3.1-70B-Instruct, we conduct continuation experiments with Gemma-3-1B-IT and LLaMA-3.1-8B-Instruct to test intra-family and cross-family behaviors. Our evaluation pipeline leverages truncation thresholds with a Process Reward Model (PRM), providing a reproducible framework for assessing reasoning stability via model interchange. Evaluations with a PRM reveal that hybrid reasoning chains often preserve, and in some cases even improve, final accuracy and logical structure. Our findings point towards interchangeability as an emerging behavioral property of reasoning models, offering insights into new paradigms for reliable modular reasoning in collaborative AI systems.
WOLF: Werewolf-based Observations for LLM Deception and Falsehoods
Dec 09, 2025Deception is a fundamental challenge for multi-agent reasoning: effective systems must strategically conceal information while detecting misleading behavior in others. Yet most evaluations reduce deception to static classification, ignoring the interactive, adversarial, and longitudinal nature of real deceptive dynamics. Large language models (LLMs) can deceive convincingly but remain weak at detecting deception in peers. We present WOLF, a multi-agent social deduction benchmark based on Werewolf that enables separable measurement of deception production and detection. WOLF embeds role-grounded agents (Villager, Werewolf, Seer, Doctor) in a programmable LangGraph state machine with strict night-day cycles, debate turns, and majority voting. Every statement is a distinct analysis unit, with self-assessed honesty from speakers and peer-rated deceptiveness from others. Deception is categorized via a standardized taxonomy (omission, distortion, fabrication, misdirection), while suspicion scores are longitudinally smoothed to capture both immediate judgments and evolving trust dynamics. Structured logs preserve prompts, outputs, and state transitions for full reproducibility. Across 7,320 statements and 100 runs, Werewolves produce deceptive statements in 31% of turns, while peer detection achieves 71-73% precision with ~52% overall accuracy. Precision is higher for identifying Werewolves, though false positives occur against Villagers. Suspicion toward Werewolves rises from ~52% to over 60% across rounds, while suspicion toward Villagers and the Doctor stabilizes near 44-46%. This divergence shows that extended interaction improves recall against liars without compounding errors against truthful roles. WOLF moves deception evaluation beyond static datasets, offering a dynamic, controlled testbed for measuring deceptive and detective capacity in adversarial multi-agent interaction.
SALT: Steering Activations towards Leakage-free Thinking in Chain of Thought
Nov 11, 2025As Large Language Models (LLMs) evolve into personal assistants with access to sensitive user data, they face a critical privacy challenge: while prior work has addressed output-level privacy, recent findings reveal that LLMs often leak private information through their internal reasoning processes, violating contextual privacy expectations. These leaky thoughts occur when models inadvertently expose sensitive details in their reasoning traces, even when final outputs appear safe. The challenge lies in preventing such leakage without compromising the model's reasoning capabilities, requiring a delicate balance between privacy and utility. We introduce Steering Activations towards Leakage-free Thinking (SALT), a lightweight test-time intervention that mitigates privacy leakage in model's Chain of Thought (CoT) by injecting targeted steering vectors into hidden state. We identify the high-leakage layers responsible for this behavior. Through experiments across multiple LLMs, we demonstrate that SALT achieves reductions including $18.2\%$ reduction in CPL on QwQ-32B, $17.9\%$ reduction in CPL on Llama-3.1-8B, and $31.2\%$ reduction in CPL on Deepseek in contextual privacy leakage dataset AirGapAgent-R while maintaining comparable task performance and utility. Our work establishes SALT as a practical approach for test-time privacy protection in reasoning-capable language models, offering a path toward safer deployment of LLM-based personal agents.
A Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
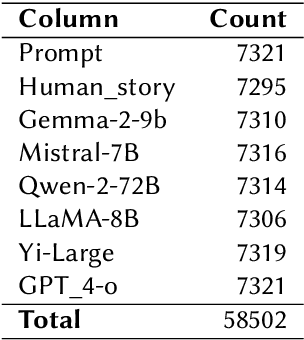

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
ERGO: Entropy-guided Resetting for Generation Optimization in Multi-turn Language Models
Oct 15, 2025Large Language Models (LLMs) suffer significant performance degradation in multi-turn conversations when information is presented incrementally. Given that multi-turn conversations characterize everyday interactions with LLMs, this degradation poses a severe challenge to real world usability. We hypothesize that abrupt increases in model uncertainty signal misalignment in multi-turn LLM interactions, and we exploit this insight to dynamically realign conversational context. We introduce ERGO (Entropy-guided Resetting for Generation Optimization), which continuously quantifies internal uncertainty via Shannon entropy over next token distributions and triggers adaptive prompt consolidation when a sharp spike in entropy is detected. By treating uncertainty as a first class signal rather than a nuisance to eliminate, ERGO embraces variability in language and modeling, representing and responding to uncertainty. In multi-turn tasks with incrementally revealed instructions, ERGO yields a 56.6% average performance gain over standard baselines, increases aptitude (peak performance capability) by 24.7%, and decreases unreliability (variability in performance) by 35.3%, demonstrating that uncertainty aware interventions can improve both accuracy and reliability in conversational AI.