 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIMSUM: Discourse in Mathematical Reasoning as a Supervision Module
Mar 07, 2025


We look at reasoning on GSM8k, a dataset of short texts presenting primary school, math problems. We find, with Mirzadeh et al. (2024), that current LLM progress on the data set may not be explained by better reasoning but by exposure to a broader pretraining data distribution. We then introduce a novel information source for helping models with less data or inferior training reason better: discourse structure. We show that discourse structure improves performance for models like Llama2 13b by up to 160%. Even for models that have most likely memorized the data set, adding discourse structural information to the model still improves predictions and dramatically improves large model performance on out of distribution examples.
The Brittleness of AI-Generated Image Watermarking Techniques: Examining Their Robustness Against Visual Paraphrasing Attacks
Aug 19, 2024The rapid advancement of text-to-image generation systems, exemplified by models like Stable Diffusion, Midjourney, Imagen, and DALL-E, has heightened concerns about their potential misuse. In response, companies like Meta and Google have intensified their efforts to implement watermarking techniques on AI-generated images to curb the circulation of potentially misleading visuals. However, in this paper, we argue that current image watermarking methods are fragile and susceptible to being circumvented through visual paraphrase attacks. The proposed visual paraphraser operates in two steps. First, it generates a caption for the given image using KOSMOS-2, one of the latest state-of-the-art image captioning systems. Second, it passes both the original image and the generated caption to an image-to-image diffusion system. During the denoising step of the diffusion pipeline, the system generates a visually similar image that is guided by the text caption. The resulting image is a visual paraphrase and is free of any watermarks. Our empirical findings demonstrate that visual paraphrase attacks can effectively remove watermarks from images. This paper provides a critical assessment, empirically revealing the vulnerability of existing watermarking techniques to visual paraphrase attacks. While we do not propose solutions to this issue, this paper serves as a call to action for the scientific community to prioritize the development of more robust watermarking techniques. Our first-of-its-kind visual paraphrase dataset and accompanying code are publicly available.
Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think -- Introducing AI Detectability Index
Oct 24, 2023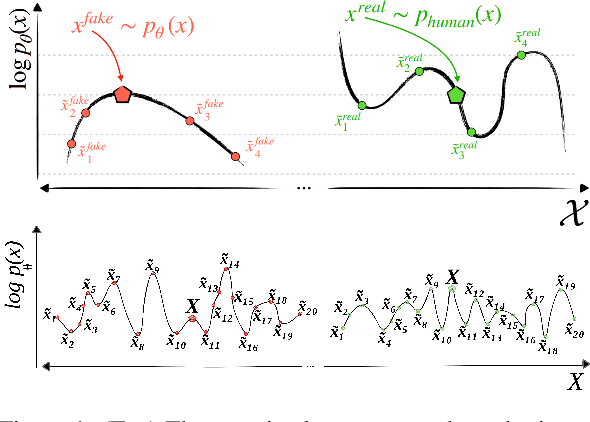



With the rise of prolific ChatGPT, the risk and consequences of AI-generated text has increased alarmingly. To address the inevitable question of ownership attribution for AI-generated artifacts, the US Copyright Office released a statement stating that 'If a work's traditional elements of authorship were produced by a machine, the work lacks human authorship and the Office will not register it'. Furthermore, both the US and the EU governments have recently drafted their initial proposals regarding the regulatory framework for AI. Given this cynosural spotlight on generative AI, AI-generated text detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by emergence of techniques to bypass detection. This paper introduces the Counter Turing Test (CT^2), a benchmark consisting of techniques aiming to offer a comprehensive evaluation of the robustness of existing AGTD techniques. Our empirical findings unequivocally highlight the fragility of the proposed AGTD methods under scrutiny. Amidst the extensive deliberations on policy-making for regulating AI development, it is of utmost importance to assess the detectability of content generated by LLMs. Thus, to establish a quantifiable spectrum facilitating the evaluation and ranking of LLMs according to their detectability levels, we propose the AI Detectability Index (ADI). We conduct a thorough examination of 15 contemporary LLMs, empirically demonstrating that larger LLMs tend to have a higher ADI, indicating they are less detectable compared to smaller LLMs. We firmly believe that ADI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making.