 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalized Hamiltonians using fully Symplectic Mappings
Sep 17, 2024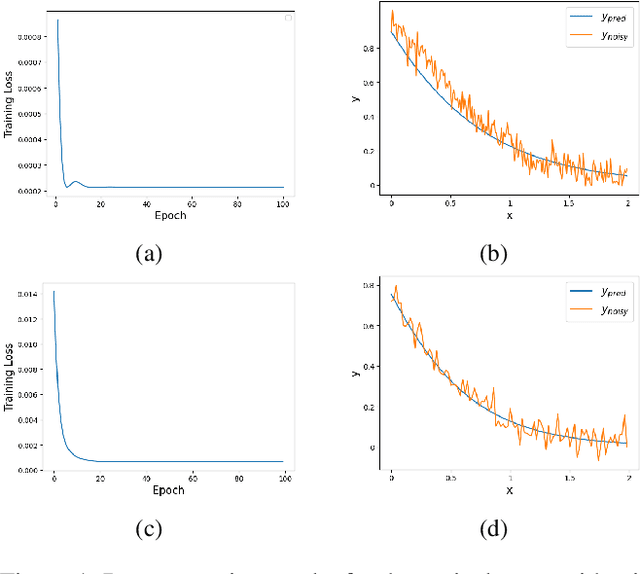
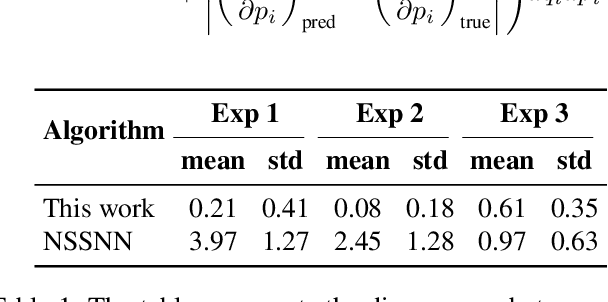
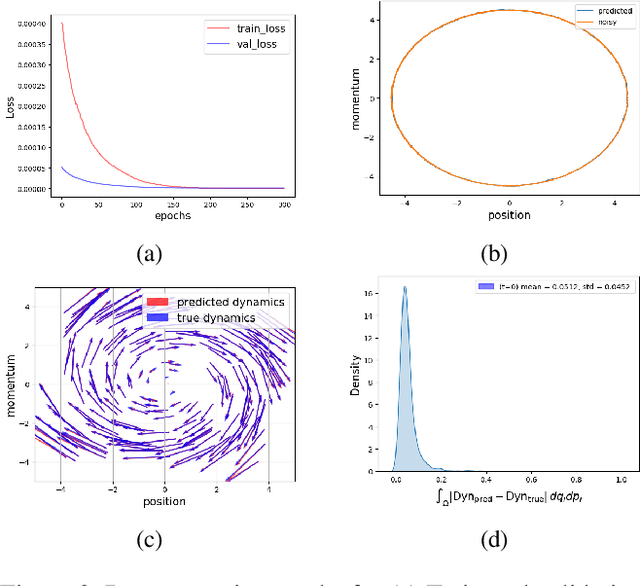

Many important physical systems can be described as the evolution of a Hamiltonian system, which has the important property of being conservative, that is, energy is conserved throughout the evolution. Physics Informed Neural Networks and in particular Hamiltonian Neural Networks have emerged as a mechanism to incorporate structural inductive bias into the NN model. By ensuring physical invariances are conserved, the models exhibit significantly better sample complexity and out-of-distribution accuracy than standard NNs. Learning the Hamiltonian as a function of its canonical variables, typically position and velocity, from sample observations of the system thus becomes a critical task in system identification and long-term prediction of system behavior. However, to truly preserve the long-run physical conservation properties of Hamiltonian systems, one must use symplectic integrators for a forward pass of the system's simulation. While symplectic schemes have been used in the literature, they are thus far limited to situations when they reduce to explicit algorithms, which include the case of separable Hamiltonians or augmented non-separable Hamiltonians. We extend it to generalized non-separable Hamiltonians, and noting the self-adjoint property of symplectic integrators, we bypass computationally intensive backpropagation through an ODE solver. We show that the method is robust to noise and provides a good approximation of the system Hamiltonian when the state variables are sampled from a noisy observation. In the numerical results, we show the performance of the method concerning Hamiltonian reconstruction and conservation, indicating its particular advantage for non-separable systems.
Counter Turing Test CT^2: AI-Generated Text Detection is Not as Easy as You May Think -- Introducing AI Detectability Index
Oct 24, 2023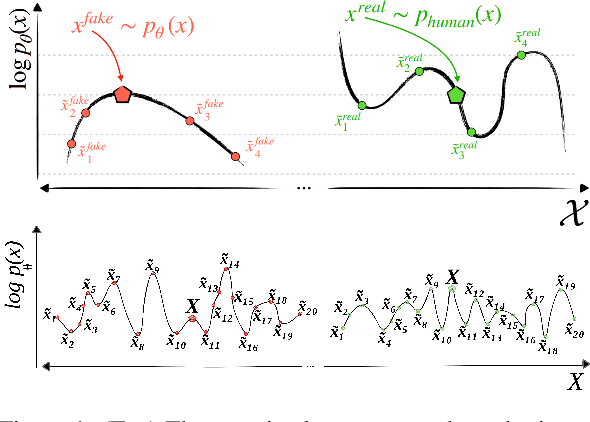



With the rise of prolific ChatGPT, the risk and consequences of AI-generated text has increased alarmingly. To address the inevitable question of ownership attribution for AI-generated artifacts, the US Copyright Office released a statement stating that 'If a work's traditional elements of authorship were produced by a machine, the work lacks human authorship and the Office will not register it'. Furthermore, both the US and the EU governments have recently drafted their initial proposals regarding the regulatory framework for AI. Given this cynosural spotlight on generative AI, AI-generated text detection (AGTD) has emerged as a topic that has already received immediate attention in research, with some initial methods having been proposed, soon followed by emergence of techniques to bypass detection. This paper introduces the Counter Turing Test (CT^2), a benchmark consisting of techniques aiming to offer a comprehensive evaluation of the robustness of existing AGTD techniques. Our empirical findings unequivocally highlight the fragility of the proposed AGTD methods under scrutiny. Amidst the extensive deliberations on policy-making for regulating AI development, it is of utmost importance to assess the detectability of content generated by LLMs. Thus, to establish a quantifiable spectrum facilitating the evaluation and ranking of LLMs according to their detectability levels, we propose the AI Detectability Index (ADI). We conduct a thorough examination of 15 contemporary LLMs, empirically demonstrating that larger LLMs tend to have a higher ADI, indicating they are less detectable compared to smaller LLMs. We firmly believe that ADI holds significant value as a tool for the wider NLP community, with the potential to serve as a rubric in AI-related policy-making.
ANALOGICAL -- A New Benchmark for Analogy of Long Text for Large Language Models
May 14, 2023



Over the past decade, analogies, in the form of word-level analogies, have played a significant role as an intrinsic measure of evaluating the quality of word embedding methods such as word2vec. Modern large language models (LLMs), however, are primarily evaluated on extrinsic measures based on benchmarks such as GLUE and SuperGLUE, and there are only a few investigations on whether LLMs can draw analogies between long texts. In this paper, we present ANALOGICAL, a new benchmark to intrinsically evaluate LLMs across a taxonomy of analogies of long text with six levels of complexity -- (i) word, (ii) word vs. sentence, (iii) syntactic, (iv) negation, (v) entailment, and (vi) metaphor. Using thirteen datasets and three different distance measures, we evaluate the abilities of eight LLMs in identifying analogical pairs in the semantic vector space. Our evaluation finds that it is increasingly challenging for LLMs to identify analogies when going up the analogy taxonomy.