 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaP: A Graph-as-Policy Multi-Agent Self-Learning Harness For Variational Automation Tasks
Jul 06, 2026For robots to work reliably in commercial and industrial applications, can recent advances in agentic coding systems combine interpretable robot programming with the open-world adaptability of model-free policies? We focus on "Variational Automation" (VA), a class of tasks that have larger variations in object geometry and pose than fixed automation. Model-free policies often struggle to close the reliability gap for VA tasks, which must be executed persistently and reliably in commercial and industrial applications. Motivated by prior work on Task and Motion Planning (TAMP) and the Robot Operating System (ROS), we introduce Graph-as-Policy (GaP), a multi-agent coding harness that generates directed computation graphs with perception, planning, and control nodes from a Modular Open Robot Skill Library (MORSL). GaP then generates an internal simulation environment to rehearse task instances with different graphs in parallel to iteratively refine the graph structure and parameters to improve success rates and throughput. Evaluation with 8 new open VA task benchmarks, 4 in-simulation and 4 in real-world, suggests that GaP can achieve success rates that significantly outperform baselines. Details, code, and data can be found online: https://graph-robots.github.io/gap
Recover, Discover, Plan: Learning Skills and Concepts from Robot Failures
Jun 16, 2026Intelligent robots should not only recover from failures, but also acquire the abstract knowledge needed to avoid them in the future. While reinforcement learning (RL) can learn reactive recovery behaviors, training a separate policy for every distinct failure mode is highly inefficient. We introduce Recovery-Driven Synthesis of Relational Concepts (ReSYNC), the first approach that progressively discovers and refines state abstractions (relational predicates) from failure-recovery experience to support abstract planning. Unlike purely reactive methods, ReSYNC jointly learns skills and concepts through an incremental dual-learning process. In the skill-learning phase, the robot uses RL to learn to recover from failures seen in training tasks. In the concept-learning phase, the robot discovers new relational predicates and refines its abstract planning model to explain and generalize the learned recovery behaviors. This interaction enables ReSYNC to convert local recoveries seen during training into global failure avoidance at test time. Across four simulated domains, we show that ReSYNC's ability to continually expand and refine its abstraction library allows it to solve long-horizon, previously unseen problems, outperforming strong baselines by over 50%. Additionally, we demonstrate sim-to-real transfer of ReSYNC, where it performs real-world non-prehensile manipulation skills and generalizes to unseen scenarios through abstract planning. Overall, ReSYNC represents a significant step toward robots that autonomously acquire abstractions for scalable, failure-aware planning in the physical world.
Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced Prompting
Dec 01, 2024



Making analogies is fundamental to cognition. Proportional analogies, which consist of four terms, are often used to assess linguistic and cognitive abilities. For instance, completing analogies like "Oxygen is to Gas as <blank> is to <blank>" requires identifying the semantic relationship (e.g., "type of") between the first pair of terms ("Oxygen" and "Gas") and finding a second pair that shares the same relationship (e.g., "Aluminum" and "Metal"). In this work, we introduce a 15K Multiple-Choice Question Answering (MCQA) dataset for proportional analogy completion and evaluate the performance of contemporary Large Language Models (LLMs) in various knowledge-enhanced prompt settings. Specifically, we augment prompts with three types of knowledge: exemplar, structured, and targeted. Our results show that despite extensive training data, solving proportional analogies remains challenging for current LLMs, with the best model achieving an accuracy of 55%. Notably, we find that providing targeted knowledge can better assist models in completing proportional analogies compared to providing exemplars or collections of structured knowledge.
Knowledge Graphs of Driving Scenes to Empower the Emerging Capabilities of Neurosymbolic AI
Nov 05, 2024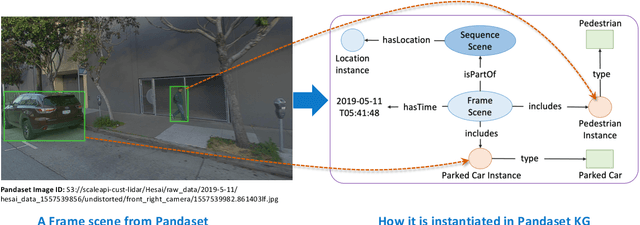
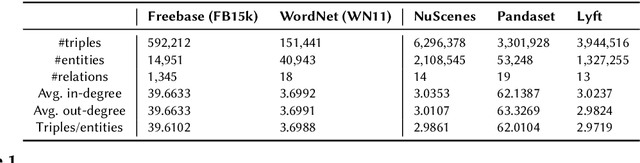
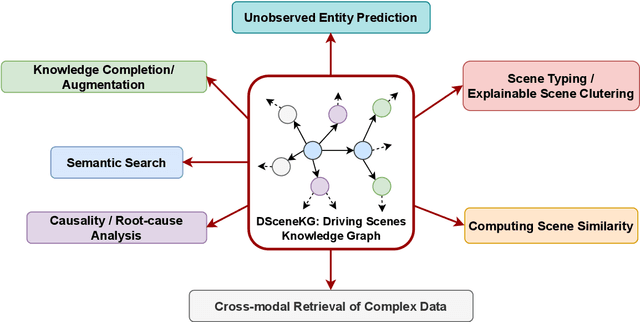
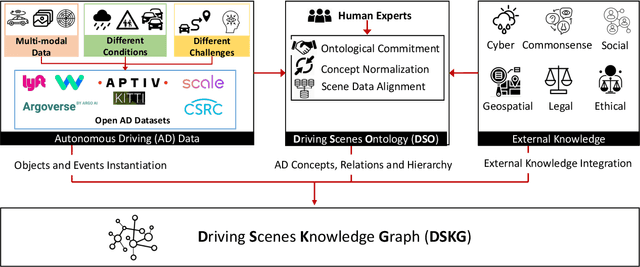
In the era of Generative AI, Neurosymbolic AI is emerging as a powerful approach for tasks spanning from perception to cognition. The use of Neurosymbolic AI has been shown to achieve enhanced capabilities, including improved grounding, alignment, explainability, and reliability. However, due to its nascent stage, there is a lack of widely available real-world benchmark datasets tailored to Neurosymbolic AI tasks. To address this gap and support the evaluation of current and future methods, we introduce DSceneKG -- a suite of knowledge graphs of driving scenes built from real-world, high-quality scenes from multiple open autonomous driving datasets. In this article, we detail the construction process of DSceneKG and highlight its application in seven different tasks. DSceneKG is publicly accessible at: https://github.com/ruwantw/DSceneKG
Towards Infusing Auxiliary Knowledge for Distracted Driver Detection
Aug 29, 2024



Distracted driving is a leading cause of road accidents globally. Identification of distracted driving involves reliably detecting and classifying various forms of driver distraction (e.g., texting, eating, or using in-car devices) from in-vehicle camera feeds to enhance road safety. This task is challenging due to the need for robust models that can generalize to a diverse set of driver behaviors without requiring extensive annotated datasets. In this paper, we propose KiD3, a novel method for distracted driver detection (DDD) by infusing auxiliary knowledge about semantic relations between entities in a scene and the structural configuration of the driver's pose. Specifically, we construct a unified framework that integrates the scene graphs, and driver pose information with the visual cues in video frames to create a holistic representation of the driver's actions.Our results indicate that KiD3 achieves a 13.64% accuracy improvement over the vision-only baseline by incorporating such auxiliary knowledge with visual information.
Evaluating the Role of Data Enrichment Approaches Towards Rare Event Analysis in Manufacturing
Jul 01, 2024Rare events are occurrences that take place with a significantly lower frequency than more common regular events. In manufacturing, predicting such events is particularly important, as they lead to unplanned downtime, shortening equipment lifespan, and high energy consumption. The occurrence of events is considered frequently-rare if observed in more than 10% of all instances, very-rare if it is 1-5%, moderately-rare if it is 5-10%, and extremely-rare if less than 1%. The rarity of events is inversely correlated with the maturity of a manufacturing industry. Typically, the rarity of events affects the multivariate data generated within a manufacturing process to be highly imbalanced, which leads to bias in predictive models. This paper evaluates the role of data enrichment techniques combined with supervised machine-learning techniques for rare event detection and prediction. To address the data scarcity, we use time series data augmentation and sampling methods to amplify the dataset with more multivariate features and data points while preserving the underlying time series patterns in the combined alterations. Imputation techniques are used in handling null values in datasets. Considering 15 learning models ranging from statistical learning to machine learning to deep learning methods, the best-performing model for the selected datasets is obtained and the efficacy of data enrichment is evaluated. Based on this evaluation, our results find that the enrichment procedure enhances up to 48% of F1 measure in rare failure event detection and prediction of supervised prediction models. We also conduct empirical and ablation experiments on the datasets to derive dataset-specific novel insights. Finally, we investigate the interpretability aspect of models for rare event prediction, considering multiple methods.
Exploring the Relationship between Analogy Identification and Sentence Structure Encoding in Large Language Models
Oct 13, 2023Identifying analogies plays a pivotal role in human cognition and language proficiency. In the last decade, there has been extensive research on word analogies in the form of ``A is to B as C is to D.'' However, there is a growing interest in analogies that involve longer text, such as sentences and collections of sentences, which convey analogous meanings. While the current NLP research community evaluates the ability of Large Language Models (LLMs) to identify such analogies, the underlying reasons behind these abilities warrant deeper investigation. Furthermore, the capability of LLMs to encode both syntactic and semantic structures of language within their embeddings has garnered significant attention with the surge in their utilization. In this work, we examine the relationship between the abilities of multiple LLMs to identify sentence analogies, and their capacity to encode syntactic and semantic structures. Through our analysis, we find that analogy identification ability of LLMs is positively correlated with their ability to encode syntactic and semantic structures of sentences. Specifically, we find that the LLMs which capture syntactic structures better, also have higher abilities in identifying sentence analogies.
A Comprehensive Survey on Rare Event Prediction
Sep 20, 2023Rare event prediction involves identifying and forecasting events with a low probability using machine learning and data analysis. Due to the imbalanced data distributions, where the frequency of common events vastly outweighs that of rare events, it requires using specialized methods within each step of the machine learning pipeline, i.e., from data processing to algorithms to evaluation protocols. Predicting the occurrences of rare events is important for real-world applications, such as Industry 4.0, and is an active research area in statistical and machine learning. This paper comprehensively reviews the current approaches for rare event prediction along four dimensions: rare event data, data processing, algorithmic approaches, and evaluation approaches. Specifically, we consider 73 datasets from different modalities (i.e., numerical, image, text, and audio), four major categories of data processing, five major algorithmic groupings, and two broader evaluation approaches. This paper aims to identify gaps in the current literature and highlight the challenges of predicting rare events. It also suggests potential research directions, which can help guide practitioners and researchers.
ANALOGICAL -- A New Benchmark for Analogy of Long Text for Large Language Models
May 14, 2023



Over the past decade, analogies, in the form of word-level analogies, have played a significant role as an intrinsic measure of evaluating the quality of word embedding methods such as word2vec. Modern large language models (LLMs), however, are primarily evaluated on extrinsic measures based on benchmarks such as GLUE and SuperGLUE, and there are only a few investigations on whether LLMs can draw analogies between long texts. In this paper, we present ANALOGICAL, a new benchmark to intrinsically evaluate LLMs across a taxonomy of analogies of long text with six levels of complexity -- (i) word, (ii) word vs. sentence, (iii) syntactic, (iv) negation, (v) entailment, and (vi) metaphor. Using thirteen datasets and three different distance measures, we evaluate the abilities of eight LLMs in identifying analogical pairs in the semantic vector space. Our evaluation finds that it is increasingly challenging for LLMs to identify analogies when going up the analogy taxonomy.
Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous Systems
Mar 30, 2022
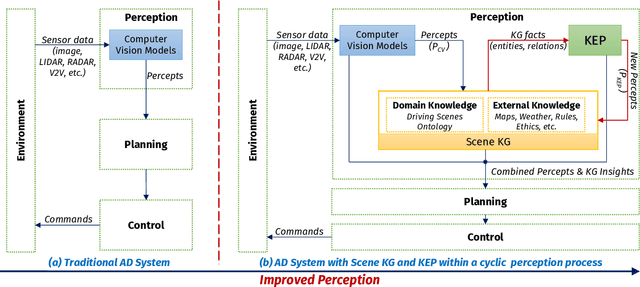
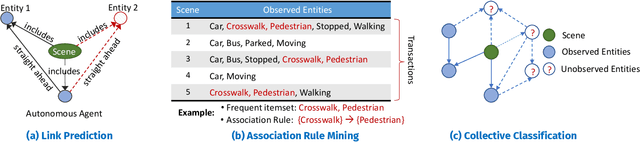
Knowledge-based entity prediction (KEP) is a novel task that aims to improve machine perception in autonomous systems. KEP leverages relational knowledge from heterogeneous sources in predicting potentially unrecognized entities. In this paper, we provide a formal definition of KEP as a knowledge completion task. Three potential solutions are then introduced, which employ several machine learning and data mining techniques. Finally, the applicability of KEP is demonstrated on two autonomous systems from different domains; namely, autonomous driving and smart manufacturing. We argue that in complex real-world systems, the use of KEP would significantly improve machine perception while pushing the current technology one step closer to achieving the full autonomy.