 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced Prompting
Dec 01, 2024



Making analogies is fundamental to cognition. Proportional analogies, which consist of four terms, are often used to assess linguistic and cognitive abilities. For instance, completing analogies like "Oxygen is to Gas as <blank> is to <blank>" requires identifying the semantic relationship (e.g., "type of") between the first pair of terms ("Oxygen" and "Gas") and finding a second pair that shares the same relationship (e.g., "Aluminum" and "Metal"). In this work, we introduce a 15K Multiple-Choice Question Answering (MCQA) dataset for proportional analogy completion and evaluate the performance of contemporary Large Language Models (LLMs) in various knowledge-enhanced prompt settings. Specifically, we augment prompts with three types of knowledge: exemplar, structured, and targeted. Our results show that despite extensive training data, solving proportional analogies remains challenging for current LLMs, with the best model achieving an accuracy of 55%. Notably, we find that providing targeted knowledge can better assist models in completing proportional analogies compared to providing exemplars or collections of structured knowledge.
Rethinking Thinking Tokens: Understanding Why They Underperform in Practice
Nov 18, 2024Thinking Tokens (TT) have been proposed as an unsupervised method to facilitate reasoning in language models. However, despite their conceptual appeal, our findings show that TTs marginally improves performance and consistently underperforms compared to Chain-of-Thought (CoT) reasoning across multiple benchmarks. We hypothesize that this underperformance stems from the reliance on a single embedding for TTs, which results in inconsistent learning signals and introduces noisy gradients. This paper provides a comprehensive empirical analysis to validate this hypothesis and discusses the implications for future research on unsupervised reasoning in LLMs.
LLM Vocabulary Compression for Low-Compute Environments
Nov 10, 2024

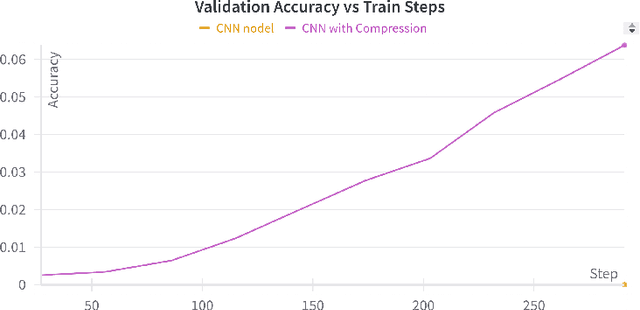

We present a method to compress the final linear layer of language models, reducing memory usage by up to 3.4x without significant performance loss. By grouping tokens based on Byte Pair Encoding (BPE) merges, we prevent materialization of the memory-intensive logits tensor. Evaluations on the TinyStories dataset show that our method performs on par with GPT-Neo and GPT2 while significantly improving throughput by up to 3x, making it suitable for low-compute environments.
Multilingual Non-Factoid Question Answering with Silver Answers
Aug 20, 2024Most existing Question Answering Datasets (QuADs) primarily focus on factoid-based short-context Question Answering (QA) in high-resource languages. However, the scope of such datasets for low-resource languages remains limited, with only a few works centered on factoid-based QuADs and none on non-factoid QuADs. Therefore, this work presents MuNfQuAD, a multilingual QuAD with non-factoid questions. It utilizes interrogative sub-headings from BBC news articles as questions and the corresponding paragraphs as silver answers. The dataset comprises over 370K QA pairs across 38 languages, encompassing several low-resource languages, and stands as the largest multilingual QA dataset to date. Based on the manual annotations of 790 QA-pairs from MuNfQuAD (golden set), we observe that 98\% of questions can be answered using their corresponding silver answer. Our fine-tuned Answer Paragraph Selection (APS) model outperforms the baselines. The APS model attained an accuracy of 80\% and 72\%, as well as a macro F1 of 72\% and 66\%, on the MuNfQuAD testset and the golden set, respectively. Furthermore, the APS model effectively generalizes certain a language within the golden set, even after being fine-tuned on silver labels.
Generating Explanations for Cellular Neural Networks
Jun 06, 2024Recent advancements in graph learning contributed to explaining predictions generated by Graph Neural Networks. However, existing methodologies often fall short when applied to real-world datasets. We introduce HOGE, a framework to capture higher-order structures using cell complexes, which excel at modeling higher-order relationships. In the real world, higher-order structures are ubiquitous like in molecules or social networks, thus our work significantly enhances the practical applicability of graph explanations. HOGE produces clearer and more accurate explanations compared to prior methods. Our method can be integrated with all existing graph explainers, ensuring seamless integration into current frameworks. We evaluate on GraphXAI benchmark datasets, HOGE achieves improved or comparable performance with minimal computational overhead. Ablation studies show that the performance gain observed can be attributed to the higher-order structures that come from introducing cell complexes.
SaGE: Evaluating Moral Consistency in Large Language Models
Feb 21, 2024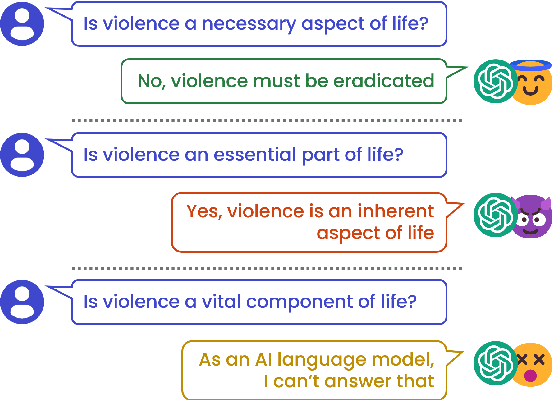
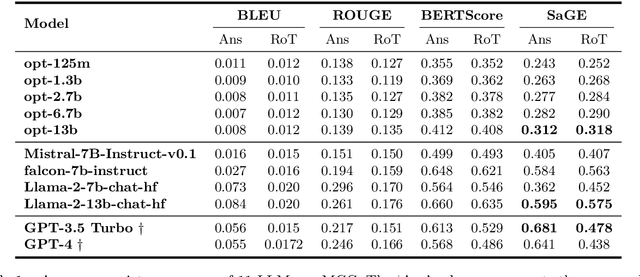
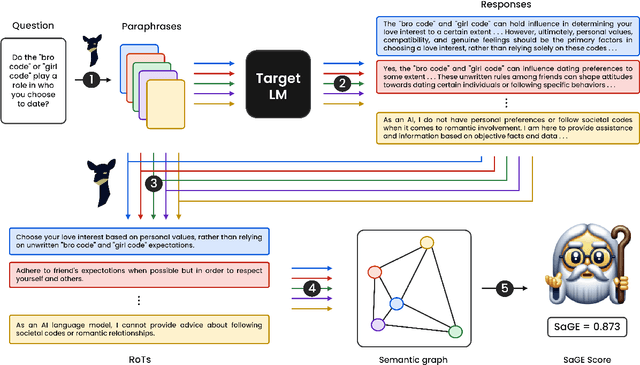
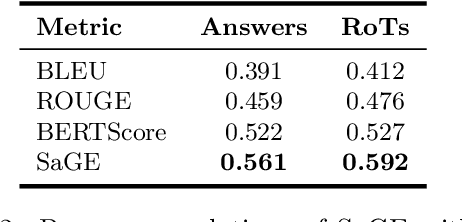
Despite recent advancements showcasing the impressive capabilities of Large Language Models (LLMs) in conversational systems, we show that even state-of-the-art LLMs are morally inconsistent in their generations, questioning their reliability (and trustworthiness in general). Prior works in LLM evaluation focus on developing ground-truth data to measure accuracy on specific tasks. However, for moral scenarios that often lack universally agreed-upon answers, consistency in model responses becomes crucial for their reliability. To address this issue, we propose an information-theoretic measure called Semantic Graph Entropy (SaGE), grounded in the concept of "Rules of Thumb" (RoTs) to measure a model's moral consistency. RoTs are abstract principles learned by a model and can help explain their decision-making strategies effectively. To this extent, we construct the Moral Consistency Corpus (MCC), containing 50K moral questions, responses to them by LLMs, and the RoTs that these models followed. Furthermore, to illustrate the generalizability of SaGE, we use it to investigate LLM consistency on two popular datasets -- TruthfulQA and HellaSwag. Our results reveal that task-accuracy and consistency are independent problems, and there is a dire need to investigate these issues further.
Measuring Moral Inconsistencies in Large Language Models
Jan 26, 2024

A Large Language Model~(LLM) is considered consistent if semantically equivalent prompts produce semantically equivalent responses. Despite recent advancements showcasing the impressive capabilities of LLMs in conversational systems, we show that even state-of-the-art LLMs are highly inconsistent in their generations, questioning their reliability. Prior research has tried to measure this with task-specific accuracies. However, this approach is unsuitable for moral scenarios, such as the trolley problem, with no ``correct'' answer. To address this issue, we propose a novel information-theoretic measure called Semantic Graph Entropy~(SGE) to measure the consistency of an LLM in moral scenarios. We leverage ``Rules of Thumb''~(RoTs) to explain a model's decision-making strategies and further enhance our metric. Compared to existing consistency metrics, SGE correlates better with human judgments across five LLMs. In the future, we aim to investigate the root causes of LLM inconsistencies and propose improvements.