 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLittiChoQA: Literary Texts in Indic Languages Chosen for Question Answering
Jan 06, 2026Long-context question answering (QA) over literary texts poses significant challenges for modern large language models, particularly in low-resource languages. We address the scarcity of long-context QA resources for Indic languages by introducing LittiChoQA, the largest literary QA dataset to date covering many languages spoken in the Gangetic plains of India. The dataset comprises over 270K automatically generated question-answer pairs with a balanced distribution of factoid and non-factoid questions, generated from naturally authored literary texts collected from the open web. We evaluate multiple multilingual LLMs on non-factoid, abstractive QA, under both full-context and context-shortened settings. Results demonstrate a clear trade-off between performance and efficiency: full-context fine-tuning yields the highest token-level and semantic-level scores, while context shortening substantially improves throughput. Among the evaluated models, Krutrim-2 achieves the strongest performance, obtaining a semantic score of 76.1 with full context. While, in shortened context settings it scores 74.9 with answer paragraph selection and 71.4 with vector-based retrieval. Qualitative evaluations further corroborate these findings.
Long-context Non-factoid Question Answering in Indic Languages
Apr 18, 2025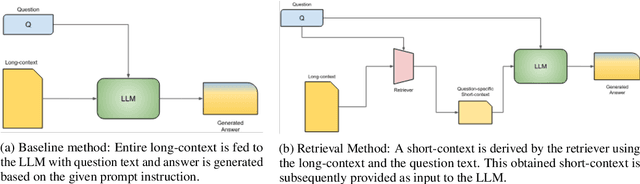
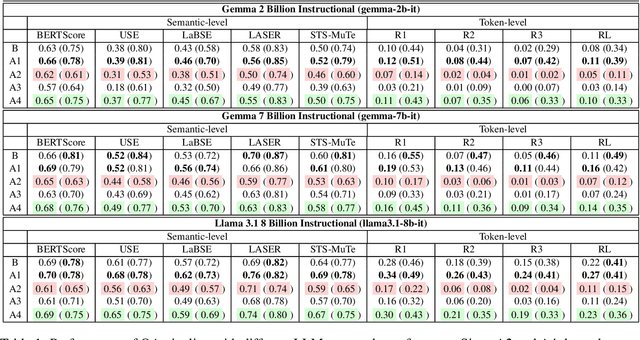
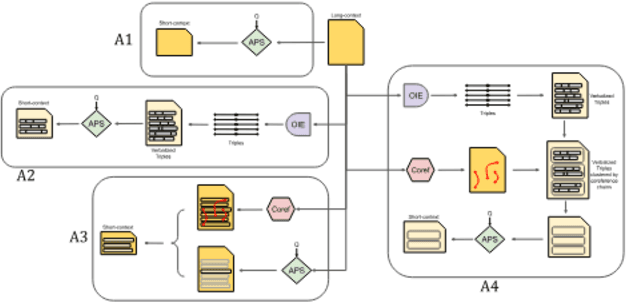
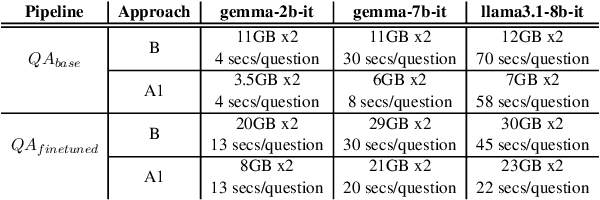
Question Answering (QA) tasks, which involve extracting answers from a given context, are relatively straightforward for modern Large Language Models (LLMs) when the context is short. However, long contexts pose challenges due to the quadratic complexity of the self-attention mechanism. This challenge is compounded in Indic languages, which are often low-resource. This study explores context-shortening techniques, including Open Information Extraction (OIE), coreference resolution, Answer Paragraph Selection (APS), and their combinations, to improve QA performance. Compared to the baseline of unshortened (long) contexts, our experiments on four Indic languages (Hindi, Tamil, Telugu, and Urdu) demonstrate that context-shortening techniques yield an average improvement of 4\% in semantic scores and 47\% in token-level scores when evaluated on three popular LLMs without fine-tuning. Furthermore, with fine-tuning, we achieve an average increase of 2\% in both semantic and token-level scores. Additionally, context-shortening reduces computational overhead. Explainability techniques like LIME and SHAP reveal that when the APS model confidently identifies the paragraph containing the answer, nearly all tokens within the selected text receive high relevance scores. However, the study also highlights the limitations of LLM-based QA systems in addressing non-factoid questions, particularly those requiring reasoning or debate. Moreover, verbalizing OIE-generated triples does not enhance system performance. These findings emphasize the potential of context-shortening techniques to improve the efficiency and effectiveness of LLM-based QA systems, especially for low-resource languages. The source code and resources are available at https://github.com/ritwikmishra/IndicGenQA.
Multilingual Non-Factoid Question Answering with Silver Answers
Aug 20, 2024Most existing Question Answering Datasets (QuADs) primarily focus on factoid-based short-context Question Answering (QA) in high-resource languages. However, the scope of such datasets for low-resource languages remains limited, with only a few works centered on factoid-based QuADs and none on non-factoid QuADs. Therefore, this work presents MuNfQuAD, a multilingual QuAD with non-factoid questions. It utilizes interrogative sub-headings from BBC news articles as questions and the corresponding paragraphs as silver answers. The dataset comprises over 370K QA pairs across 38 languages, encompassing several low-resource languages, and stands as the largest multilingual QA dataset to date. Based on the manual annotations of 790 QA-pairs from MuNfQuAD (golden set), we observe that 98\% of questions can be answered using their corresponding silver answer. Our fine-tuned Answer Paragraph Selection (APS) model outperforms the baselines. The APS model attained an accuracy of 80\% and 72\%, as well as a macro F1 of 72\% and 66\%, on the MuNfQuAD testset and the golden set, respectively. Furthermore, the APS model effectively generalizes certain a language within the golden set, even after being fine-tuned on silver labels.
Multilingual Coreference Resolution in Low-resource South Asian Languages
Feb 21, 2024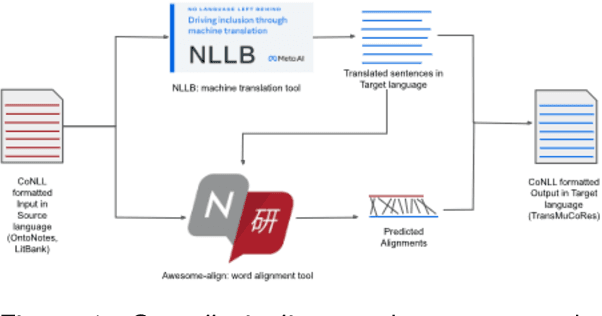
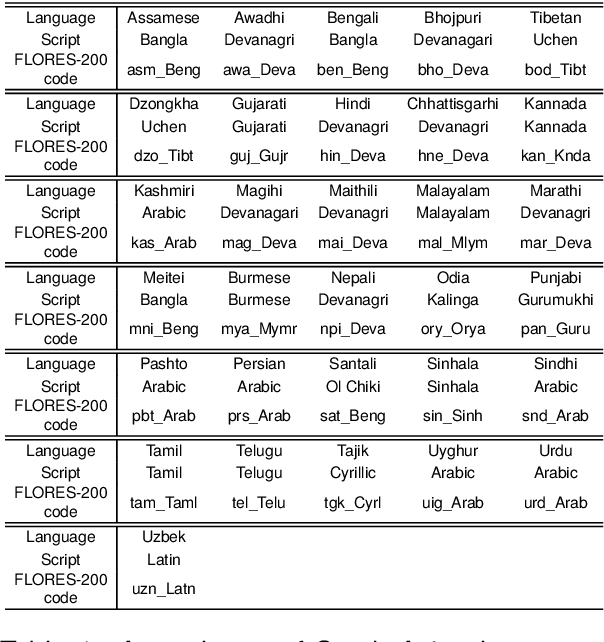
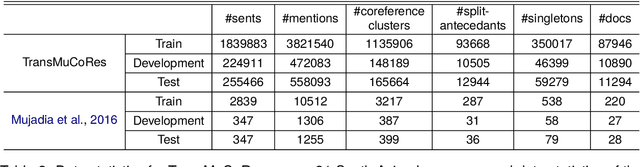

Coreference resolution involves the task of identifying text spans within a discourse that pertain to the same real-world entity. While this task has been extensively explored in the English language, there has been a notable scarcity of publicly accessible resources and models for coreference resolution in South Asian languages. We introduce a Translated dataset for Multilingual Coreference Resolution (TransMuCoRes) in 31 South Asian languages using off-the-shelf tools for translation and word-alignment. Nearly all of the predicted translations successfully pass a sanity check, and 75% of English references align with their predicted translations. Using multilingual encoders, two off-the-shelf coreference resolution models were trained on a concatenation of TransMuCoRes and a Hindi coreference resolution dataset with manual annotations. The best performing model achieved a score of 64 and 68 for LEA F1 and CoNLL F1, respectively, on our test-split of Hindi golden set. This study is the first to evaluate an end-to-end coreference resolution model on a Hindi golden set. Furthermore, this work underscores the limitations of current coreference evaluation metrics when applied to datasets with split antecedents, advocating for the development of more suitable evaluation metrics.