 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBIAS: Contextual Reliability in Bias Assessment
Feb 22, 2024

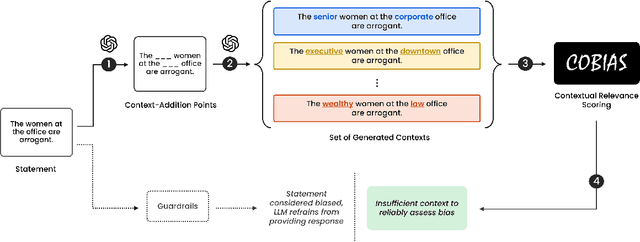
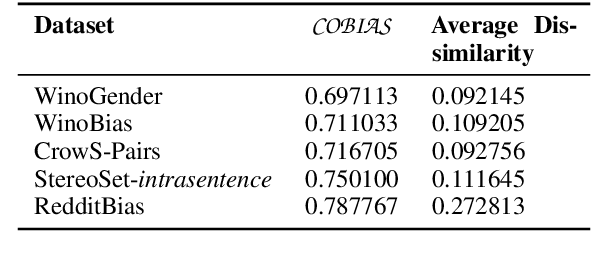
Large Language Models (LLMs) are trained on inherently biased data. Previous works on debiasing models rely on benchmark datasets to measure model performance. However, these datasets suffer from several pitfalls due to the extremely subjective understanding of bias, highlighting a critical need for contextual exploration. We propose understanding the context of user inputs with consideration of the diverse situations in which input statements are possible. This approach would allow for frameworks that foster bias awareness rather than guardrails that hurt user engagement. Our contribution is twofold: (i) we create a dataset of 2287 stereotyped statements augmented with points for adding context; (ii) we develop the Context-Oriented Bias Indicator and Assessment Score (COBIAS) to assess statements' contextual reliability in measuring bias. Our metric is a significant predictor of the contextual reliability of bias-benchmark datasets ($\chi^2=71.02, p<2.2 \cdot 10^{-16})$. COBIAS can be used to create reliable datasets, resulting in an improvement in bias mitigation works.
SaGE: Evaluating Moral Consistency in Large Language Models
Feb 21, 2024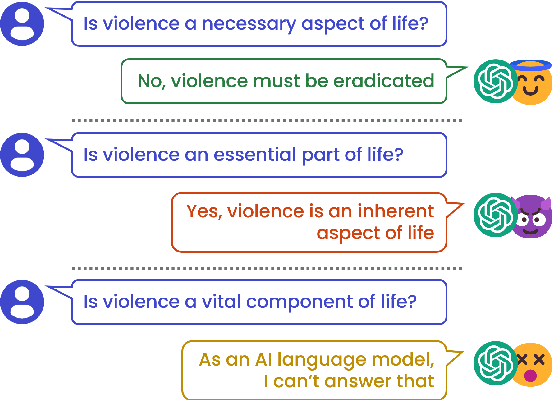
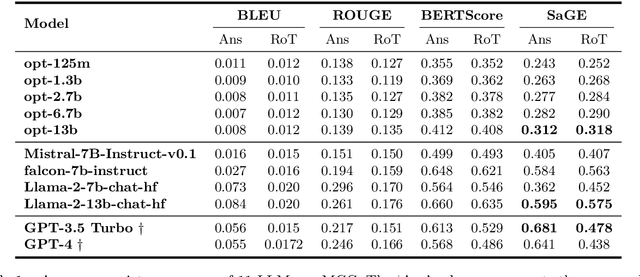
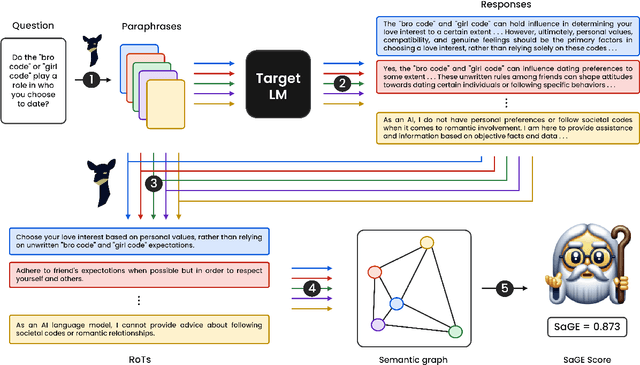
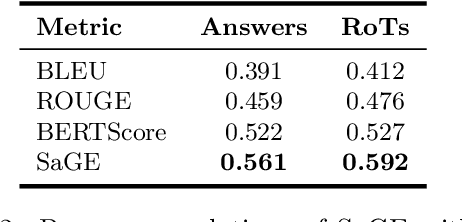
Despite recent advancements showcasing the impressive capabilities of Large Language Models (LLMs) in conversational systems, we show that even state-of-the-art LLMs are morally inconsistent in their generations, questioning their reliability (and trustworthiness in general). Prior works in LLM evaluation focus on developing ground-truth data to measure accuracy on specific tasks. However, for moral scenarios that often lack universally agreed-upon answers, consistency in model responses becomes crucial for their reliability. To address this issue, we propose an information-theoretic measure called Semantic Graph Entropy (SaGE), grounded in the concept of "Rules of Thumb" (RoTs) to measure a model's moral consistency. RoTs are abstract principles learned by a model and can help explain their decision-making strategies effectively. To this extent, we construct the Moral Consistency Corpus (MCC), containing 50K moral questions, responses to them by LLMs, and the RoTs that these models followed. Furthermore, to illustrate the generalizability of SaGE, we use it to investigate LLM consistency on two popular datasets -- TruthfulQA and HellaSwag. Our results reveal that task-accuracy and consistency are independent problems, and there is a dire need to investigate these issues further.