 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Guardrails: How Semantic Geometry of Personality Interacts with Emergent Misalignment in LLMs
May 11, 2026Fine-tuning Large Language Models (LLMs) on benign narrow data can sometimes induce broad harmful behaviors, a vulnerability termed emergent misalignment (EM). While prior work links these failures to specific directions in the activation space, their relationship to the model's broader persona remains unexplored. We map the latent personality space of LLMs through established psychometric profiles like the Big Five, Dark Triad, and LLM-specific behaviors (e.g. evil, sycophancy), and show that the semantic geometry is highly stable across aligned models and their corrupted fine-tunes. Through causal interventions, we find that directions isolating social valence, such as the 'Evil' persona vector, and a Semantic Valence Vector (SVV) that we introduce, function as intrinsic guardrails: ablating them drives the misalignment rates above $40$%, while amplifying them suppresses the failure mode to less than $3$%. Leveraging the structural stability of the personality space, we show that vectors extracted $\textit{a priori}$ from an instruct-tuned model transfer zero-shot to successfully regulate EM in corrupted fine-tunes. Overall, our findings suggest that harmful fine-tuning does not overwrite a model's internal representation of personality, allowing conserved representations to serve as robust, cross-distribution guardrails.
If Pigs Could Fly... Can LLMs Logically Reason Through Counterfactuals?
May 28, 2025Large Language Models (LLMs) demonstrate impressive reasoning capabilities in familiar contexts, but struggle when the context conflicts with their parametric knowledge. To investigate this phenomenon, we introduce CounterLogic, a dataset containing 1,800 examples across 9 logical schemas, explicitly designed to evaluate logical reasoning through counterfactual (hypothetical knowledge-conflicting) scenarios. Our systematic evaluation of 11 LLMs across 6 different datasets reveals a consistent performance degradation, with accuracies dropping by 27% on average when reasoning through counterfactual information. We propose Self-Segregate, a prompting method enabling metacognitive awareness (explicitly identifying knowledge conflicts) before reasoning. Our method dramatically narrows the average performance gaps from 27% to just 11%, while significantly increasing the overall accuracy (+7.5%). We discuss the implications of these findings and draw parallels to human cognitive processes, particularly on how humans disambiguate conflicting information during reasoning tasks. Our findings offer practical insights for understanding and enhancing LLMs reasoning capabilities in real-world applications, especially where models must logically reason independently of their factual knowledge.
From Human Judgements to Predictive Models: Unravelling Acceptability in Code-Mixed Sentences
May 09, 2024



Current computational approaches for analysing or generating code-mixed sentences do not explicitly model "naturalness" or "acceptability" of code-mixed sentences, but rely on training corpora to reflect distribution of acceptable code-mixed sentences. Modelling human judgement for the acceptability of code-mixed text can help in distinguishing natural code-mixed text and enable quality-controlled generation of code-mixed text. To this end, we construct Cline - a dataset containing human acceptability judgements for English-Hindi (en-hi) code-mixed text. Cline is the largest of its kind with 16,642 sentences, consisting of samples sourced from two sources: synthetically generated code-mixed text and samples collected from online social media. Our analysis establishes that popular code-mixing metrics such as CMI, Number of Switch Points, Burstines, which are used to filter/curate/compare code-mixed corpora have low correlation with human acceptability judgements, underlining the necessity of our dataset. Experiments using Cline demonstrate that simple Multilayer Perceptron (MLP) models trained solely on code-mixing metrics are outperformed by fine-tuned pre-trained Multilingual Large Language Models (MLLMs). Specifically, XLM-Roberta and Bernice outperform IndicBERT across different configurations in challenging data settings. Comparison with ChatGPT's zero and fewshot capabilities shows that MLLMs fine-tuned on larger data outperform ChatGPT, providing scope for improvement in code-mixed tasks. Zero-shot transfer from English-Hindi to English-Telugu acceptability judgments using our model checkpoints proves superior to random baselines, enabling application to other code-mixed language pairs and providing further avenues of research. We publicly release our human-annotated dataset, trained checkpoints, code-mix corpus, and code for data generation and model training.
COBIAS: Contextual Reliability in Bias Assessment
Feb 22, 2024

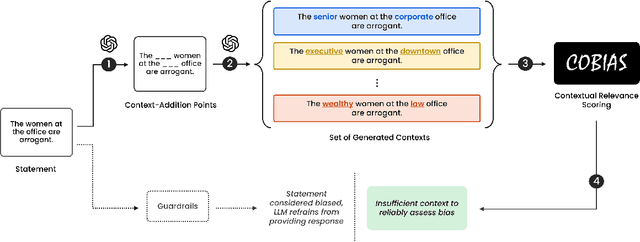
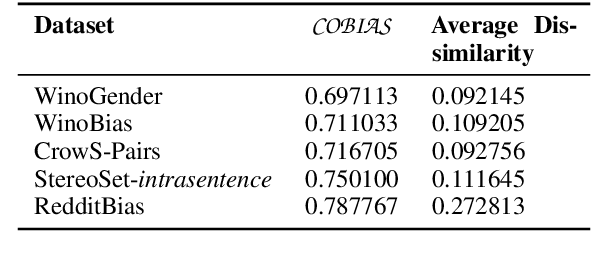
Large Language Models (LLMs) are trained on inherently biased data. Previous works on debiasing models rely on benchmark datasets to measure model performance. However, these datasets suffer from several pitfalls due to the extremely subjective understanding of bias, highlighting a critical need for contextual exploration. We propose understanding the context of user inputs with consideration of the diverse situations in which input statements are possible. This approach would allow for frameworks that foster bias awareness rather than guardrails that hurt user engagement. Our contribution is twofold: (i) we create a dataset of 2287 stereotyped statements augmented with points for adding context; (ii) we develop the Context-Oriented Bias Indicator and Assessment Score (COBIAS) to assess statements' contextual reliability in measuring bias. Our metric is a significant predictor of the contextual reliability of bias-benchmark datasets ($\chi^2=71.02, p<2.2 \cdot 10^{-16})$. COBIAS can be used to create reliable datasets, resulting in an improvement in bias mitigation works.
SaGE: Evaluating Moral Consistency in Large Language Models
Feb 21, 2024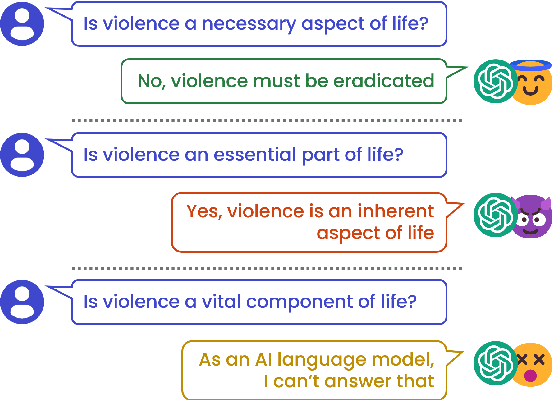
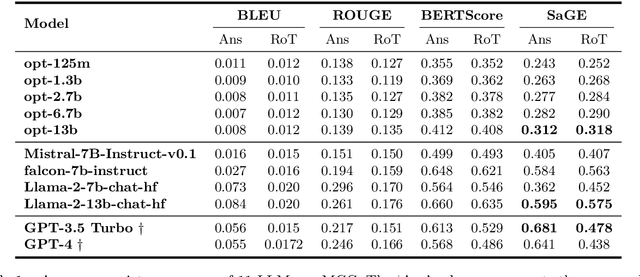
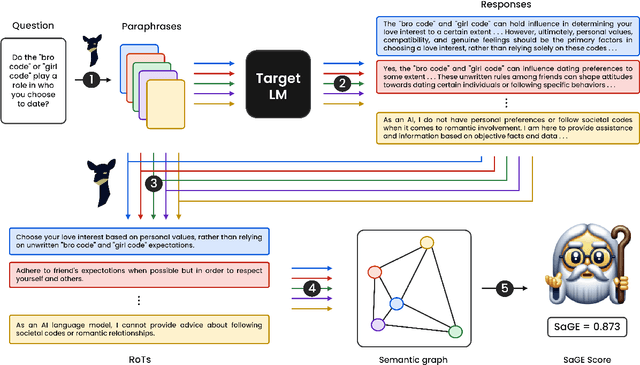
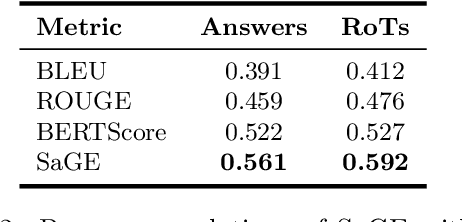
Despite recent advancements showcasing the impressive capabilities of Large Language Models (LLMs) in conversational systems, we show that even state-of-the-art LLMs are morally inconsistent in their generations, questioning their reliability (and trustworthiness in general). Prior works in LLM evaluation focus on developing ground-truth data to measure accuracy on specific tasks. However, for moral scenarios that often lack universally agreed-upon answers, consistency in model responses becomes crucial for their reliability. To address this issue, we propose an information-theoretic measure called Semantic Graph Entropy (SaGE), grounded in the concept of "Rules of Thumb" (RoTs) to measure a model's moral consistency. RoTs are abstract principles learned by a model and can help explain their decision-making strategies effectively. To this extent, we construct the Moral Consistency Corpus (MCC), containing 50K moral questions, responses to them by LLMs, and the RoTs that these models followed. Furthermore, to illustrate the generalizability of SaGE, we use it to investigate LLM consistency on two popular datasets -- TruthfulQA and HellaSwag. Our results reveal that task-accuracy and consistency are independent problems, and there is a dire need to investigate these issues further.
Measuring Moral Inconsistencies in Large Language Models
Jan 26, 2024

A Large Language Model~(LLM) is considered consistent if semantically equivalent prompts produce semantically equivalent responses. Despite recent advancements showcasing the impressive capabilities of LLMs in conversational systems, we show that even state-of-the-art LLMs are highly inconsistent in their generations, questioning their reliability. Prior research has tried to measure this with task-specific accuracies. However, this approach is unsuitable for moral scenarios, such as the trolley problem, with no ``correct'' answer. To address this issue, we propose a novel information-theoretic measure called Semantic Graph Entropy~(SGE) to measure the consistency of an LLM in moral scenarios. We leverage ``Rules of Thumb''~(RoTs) to explain a model's decision-making strategies and further enhance our metric. Compared to existing consistency metrics, SGE correlates better with human judgments across five LLMs. In the future, we aim to investigate the root causes of LLM inconsistencies and propose improvements.